 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpermanent: A Live Benchmark for Temporal Generalization in Time Series Forecasting
Mar 10, 2026Recent advances in time-series forecasting increasingly rely on pre-trained foundation-style models. While these models often claim broad generalization, existing evaluation protocols provide limited evidence. Indeed, most current benchmarks use static train-test splits that can easily lead to contamination as foundation models can inadvertently train on test data or perform model selection using test scores, which can inflate performance. We introduce Impermanent, a live benchmark that evaluates forecasting models under open-world temporal change by scoring forecasts sequentially over time on continuously updated data streams, enabling the study of temporal robustness, distributional shift, and performance stability rather than one-off accuracy on a frozen test set. Impermanent is instantiated on GitHub open-source activity, providing a naturally live and highly non-stationary dataset shaped by releases, shifting contributor behavior, platform/tooling changes, and external events. We focus on the top 400 repositories by star count and construct time series from issues opened, pull requests opened, push events, and new stargazers, evaluated over a rolling window with daily updates, alongside standardized protocols and leaderboards for reproducible, ongoing comparison. By shifting evaluation from static accuracy to sustained performance, Impermanent takes a concrete step toward assessing when and whether foundation-level generalization in time-series forecasting can be meaningfully claimed. Code and a live dashboard are available at https://github.com/TimeCopilot/impermanent and https://impermanent.timecopilot.dev.
Federated PCA with Adaptive Rank Estimation
Jul 18, 2019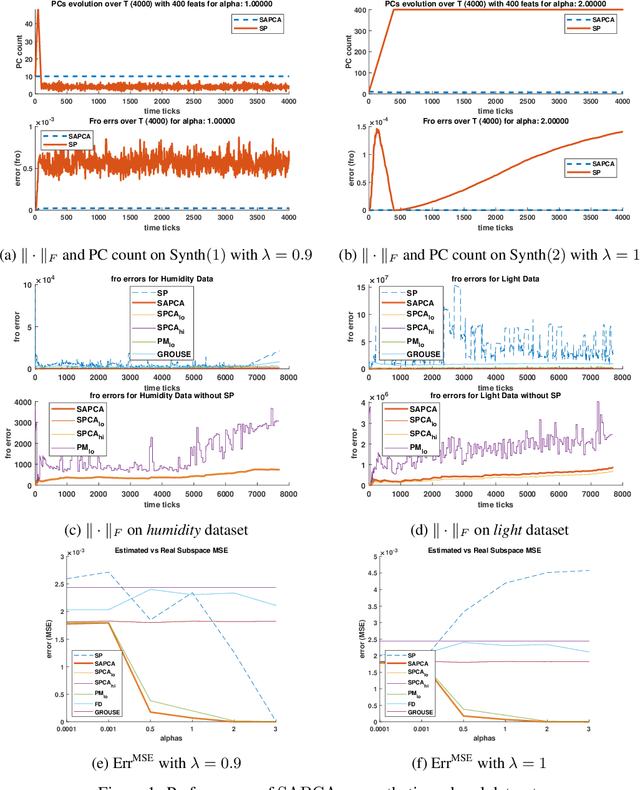

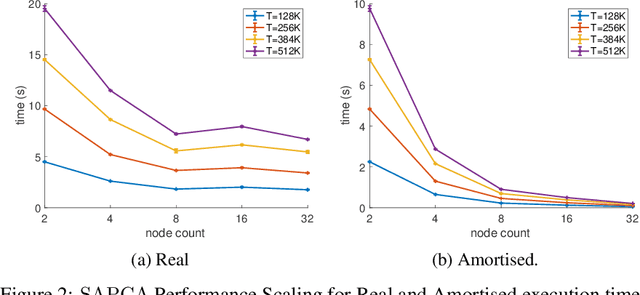
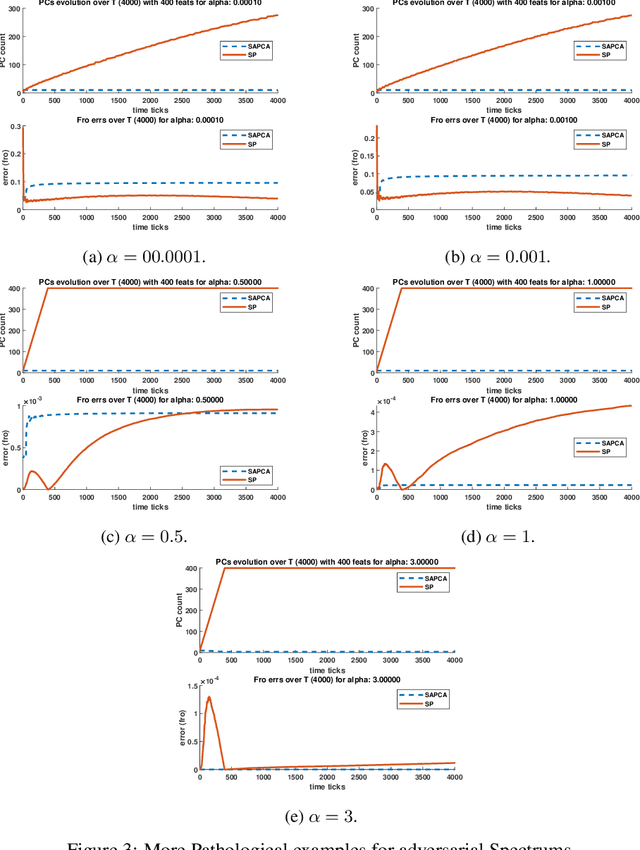
In many online machine learning and data science tasks such as data summarisation and feature compression, $d$-dimensional vectors are usually distributed across a large number of clients in a decentralised network and collected in a streaming fashion. This is increasingly common in modern applications due to the sheer volume of data generated and the clients' constrained resources. In this setting, some clients are required to compute an update to a centralised target model independently using local data while other clients aggregate these updates with a low-complexity merging algorithm. However, some clients with limited storage might not be able to store all of the data samples if $d$ is large, nor compute procedures requiring at least $\Omega(d^2)$ storage-complexity such as Principal Component Analysis, Subspace Tracking, or general Feature Correlation. In this work, we present a novel federated algorithm for PCA that is able to adaptively estimate the rank $r$ of the dataset and compute its $r$ leading principal components when only $O(dr)$ memory is available. This inherent adaptability implies that $r$ does not have to be supplied as a fixed hyper-parameter which is beneficial when the underlying data distribution is not known in advance, such as in a streaming setting. Numerical simulations show that, while using limited-memory, our algorithm exhibits state-of-the-art performance that closely matches or outperforms traditional non-federated algorithms, and in the absence of communication latency, it exhibits attractive horizontal scalability.