 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREBAR: Reference Ethical Benchmark for Autonomy Readiness
May 18, 2026As autonomous systems grow more advanced, objective metrics to evaluate their ethical and legal compliance are critical for informing end users of their limitations and ensuring accountability of those who misuse them. Current ethical embodied AI frameworks remain mostly qualitative, focusing on system design (through safety guardrails or targeted red teaming), and the realized guardrails often directly disallow unsafe behavior without providing the user with an override or interpretable reason. Instead, there is a need for computable metrics through rigorous testing that allow a user to determine the applicability of the system to the task. To address this gap, we introduce the Reference Ethical Benchmark for Autonomy Readiness (REBAR), a quantitative test and evaluation framework for autonomous systems. REBAR maps operating metrics into a computable Autonomy Readiness Level (ARL) rubric that can quantify ethical performance. Key innovations of the framework include a neuro-symbolic Large Language Model (LLM) approach to calculate and explain the ethical difficulty of scenarios, LLM-driven at-scale generation of test instances, and a versatile, photorealistic simulation environment. By evaluating white-box autonomy solutions through this rigorous testing pipeline, REBAR delivers an objective and repeatable benchmark score, bridging the gap between abstract principles and verifiable, accountable autonomy.
Deep Neural Networks In Fully Connected CRF For Image Labeling With Social Network Metadata
Jan 27, 2018
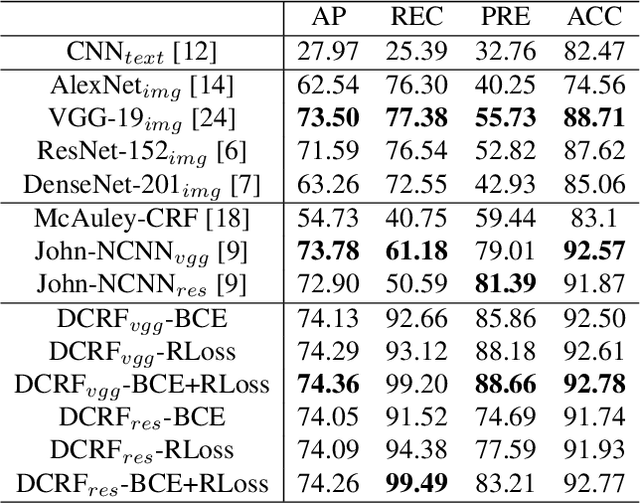
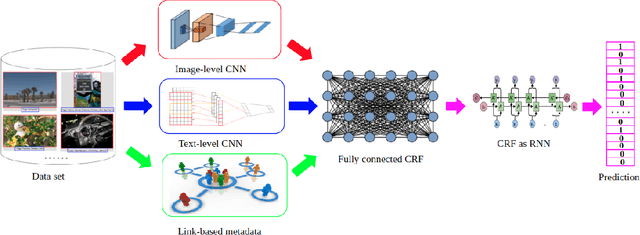
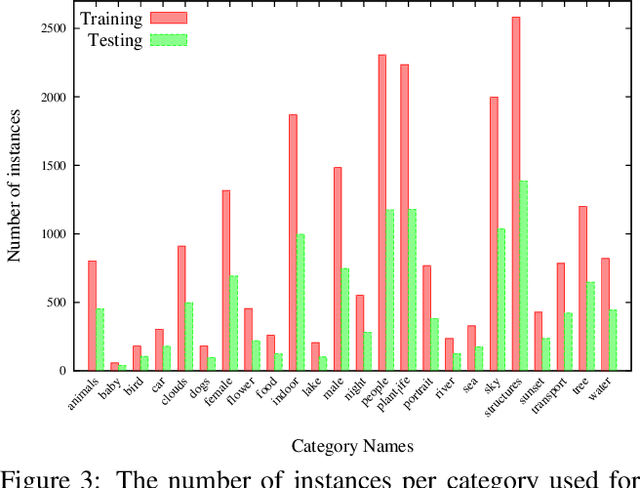
We propose a novel method for predicting image labels by fusing image content descriptors with the social media context of each image. An image uploaded to a social media site such as Flickr often has meaningful, associated information, such as comments and other images the user has uploaded, that is complementary to pixel content and helpful in predicting labels. Prediction challenges such as ImageNet~\cite{imagenet_cvpr09} and MSCOCO~\cite{LinMBHPRDZ:ECCV14} use only pixels, while other methods make predictions purely from social media context \cite{McAuleyECCV12}. Our method is based on a novel fully connected Conditional Random Field (CRF) framework, where each node is an image, and consists of two deep Convolutional Neural Networks (CNN) and one Recurrent Neural Network (RNN) that model both textual and visual node/image information. The edge weights of the CRF graph represent textual similarity and link-based metadata such as user sets and image groups. We model the CRF as an RNN for both learning and inference, and incorporate the weighted ranking loss and cross entropy loss into the CRF parameter optimization to handle the training data imbalance issue. Our proposed approach is evaluated on the MIR-9K dataset and experimentally outperforms current state-of-the-art approaches.