 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Training for Accurate 3D Human Pose and Shape Estimation in the Wild
Sep 22, 2020
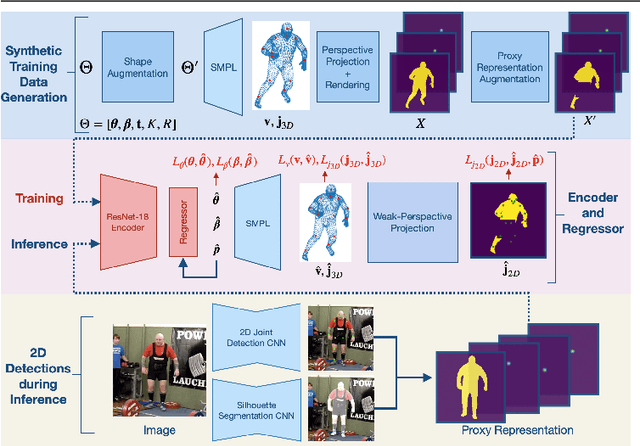
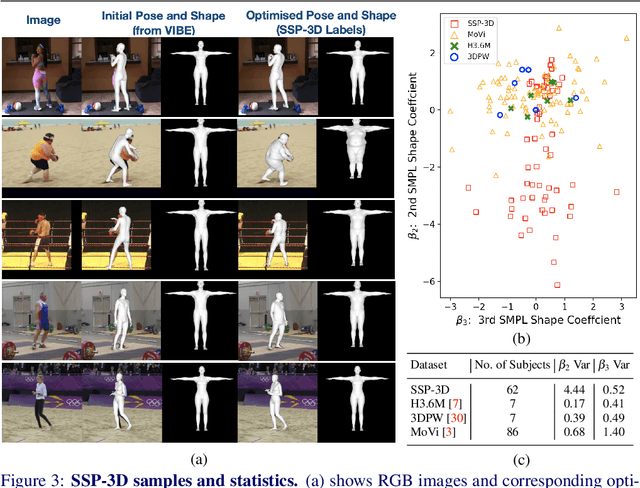

This paper addresses the problem of monocular 3D human shape and pose estimation from an RGB image. Despite great progress in this field in terms of pose prediction accuracy, state-of-the-art methods often predict inaccurate body shapes. We suggest that this is primarily due to the scarcity of in-the-wild training data with diverse and accurate body shape labels. Thus, we propose STRAPS (Synthetic Training for Real Accurate Pose and Shape), a system that utilises proxy representations, such as silhouettes and 2D joints, as inputs to a shape and pose regression neural network, which is trained with synthetic training data (generated on-the-fly during training using the SMPL statistical body model) to overcome data scarcity. We bridge the gap between synthetic training inputs and noisy real inputs, which are predicted by keypoint detection and segmentation CNNs at test-time, by using data augmentation and corruption during training. In order to evaluate our approach, we curate and provide a challenging evaluation dataset for monocular human shape estimation, Sports Shape and Pose 3D (SSP-3D). It consists of RGB images of tightly-clothed sports-persons with a variety of body shapes and corresponding pseudo-ground-truth SMPL shape and pose parameters, obtained via multi-frame optimisation. We show that STRAPS outperforms other state-of-the-art methods on SSP-3D in terms of shape prediction accuracy, while remaining competitive with the state-of-the-art on pose-centric datasets and metrics.
A CNN Based Approach for the Near-Field Photometric Stereo Problem
Sep 12, 2020
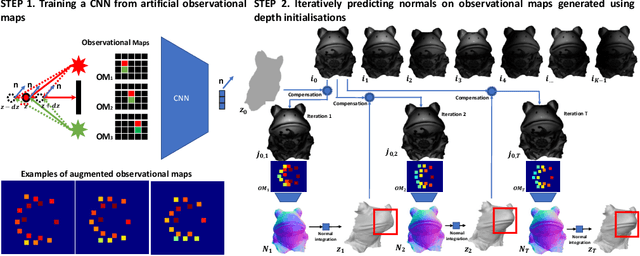
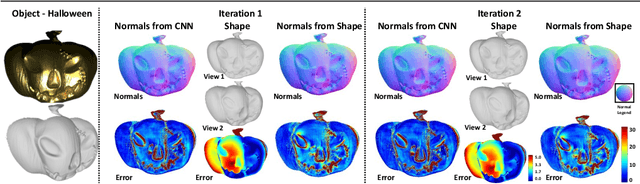
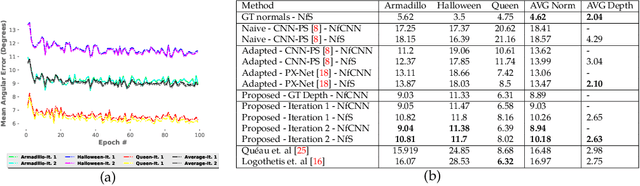
Reconstructing the 3D shape of an object using several images under different light sources is a very challenging task, especially when realistic assumptions such as light propagation and attenuation, perspective viewing geometry and specular light reflection are considered. Many of works tackling Photometric Stereo (PS) problems often relax most of the aforementioned assumptions. Especially they ignore specular reflection and global illumination effects. In this work, we propose the first CNN based approach capable of handling these realistic assumptions in Photometric Stereo. We leverage recent improvements of deep neural networks for far-field Photometric Stereo and adapt them to near field setup. We achieve this by employing an iterative procedure for shape estimation which has two main steps. Firstly we train a per-pixel CNN to predict surface normals from reflectance samples. Secondly, we compute the depth by integrating the normal field in order to iteratively estimate light directions and attenuation which is used to compensate the input images to compute reflectance samples for the next iteration. To the best of our knowledge this is the first near-field framework which is able to accurately predict 3D shape from highly specular objects. Our method outperforms competing state-of-the-art near-field Photometric Stereo approaches on both synthetic and real experiments.
Embodied Visual Navigation with Automatic Curriculum Learning in Real Environments
Sep 11, 2020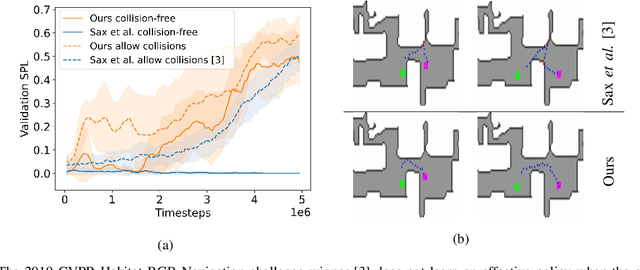
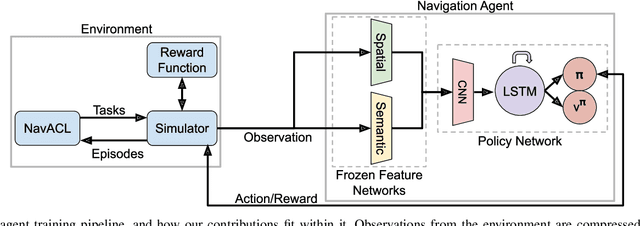
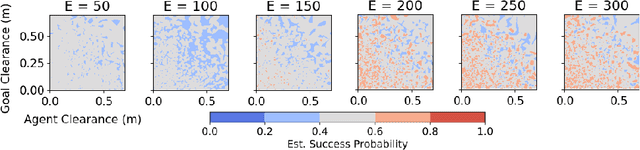
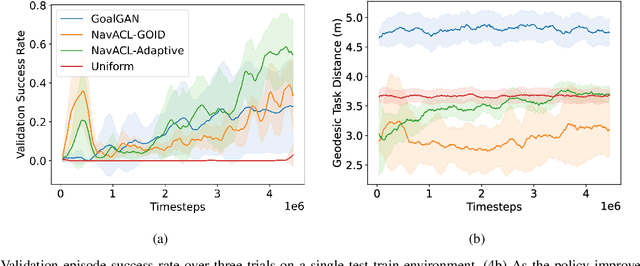
We present NavACL, a method of automatic curriculum learning tailored to the navigation task. NavACL is simple to train and efficiently selects relevant tasks using geometric features. In our experiments, deep reinforcement learning agents trained using NavACL in collision-free environments significantly outperform state-of-the-art agents trained with uniform sampling -- the current standard. Furthermore, our agents are able to navigate through unknown cluttered indoor environments to semantically-specified targets using only RGB images. Collision avoidance policies and frozen feature networks support transfer to unseen real-world environments, without any modification or retraining requirements. We evaluate our policies in simulation, and in the real world on a ground robot and a quadrotor drone. Videos of real-world results are available in the supplementary material
PX-NET: Simple, Efficient Pixel-Wise Training of Photometric Stereo Networks
Aug 11, 2020
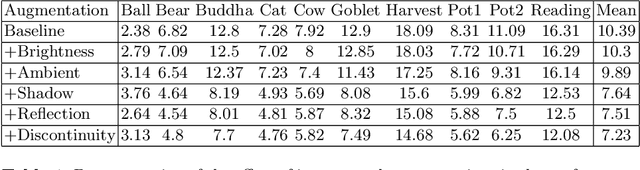
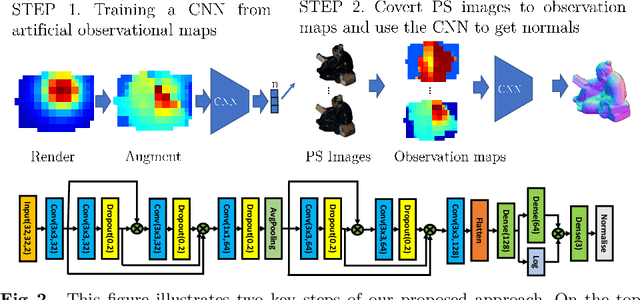
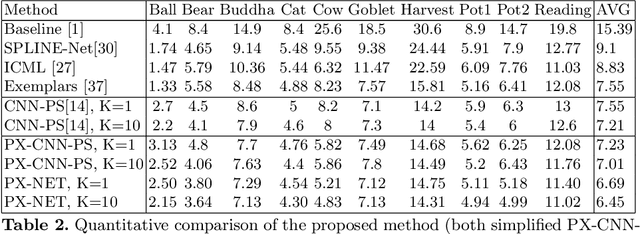
Retrieving accurate 3D reconstructions of objects from the way they reflect light is a very challenging task in computer vision. Despite more than four decades since the definition of the Photometric Stereo problem, most of the literature has had limited success when global illumination effects such as cast shadows, self-reflections and ambient light come into play, especially for specular surfaces. Recent approaches have leveraged the power of deep learning in conjunction with computer graphics in order to cope with the need of a vast number of training data in order to invert the image irradiance equation and retrieve the geometry of the object. However, rendering global illumination effects is a slow process which can limit the amount of training data that can be generated. In this work we propose a novel pixel-wise training procedure for normal prediction by replacing the training data of globally rendered images with independent per-pixel renderings. We show that robustness to global physical effects can be achieved via data-augmentation which greatly simplifies and speeds up the data creation procedure. Our network, PX-NET, achieves the state-of-the-art performance on synthetic datasets, as well as the Diligent real dataset.
Who Left the Dogs Out? 3D Animal Reconstruction with Expectation Maximization in the Loop
Jul 21, 2020
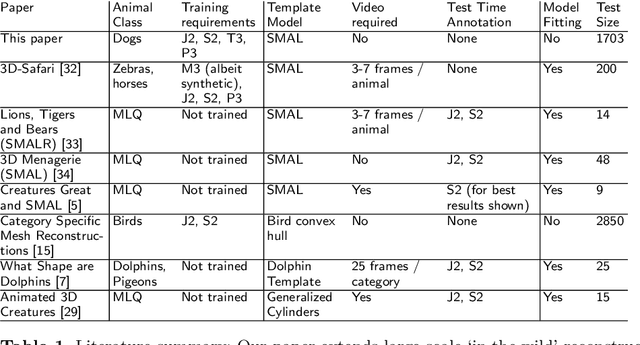
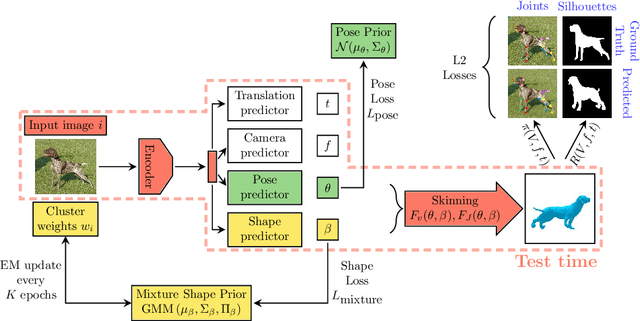
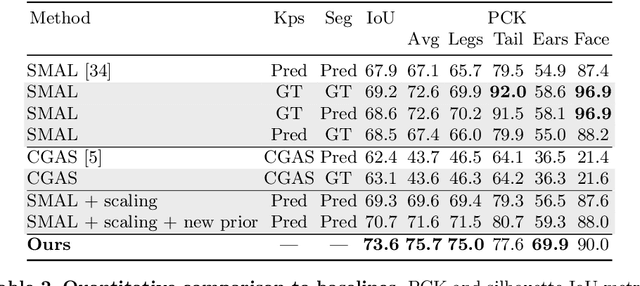
We introduce an automatic, end-to-end method for recovering the 3D pose and shape of dogs from monocular internet images. The large variation in shape between dog breeds, significant occlusion and low quality of internet images makes this a challenging problem. We learn a richer prior over shapes than previous work, which helps regularize parameter estimation. We demonstrate results on the Stanford Dog dataset, an 'in the wild' dataset of 20,580 dog images for which we have collected 2D joint and silhouette annotations to split for training and evaluation. In order to capture the large shape variety of dogs, we show that the natural variation in the 2D dataset is enough to learn a detailed 3D prior through expectation maximization (EM). As a by-product of training, we generate a new parameterized model (including limb scaling) SMBLD which we release alongside our new annotation dataset StanfordExtra to the research community.
Predicting Semantic Map Representations from Images using Pyramid Occupancy Networks
Mar 30, 2020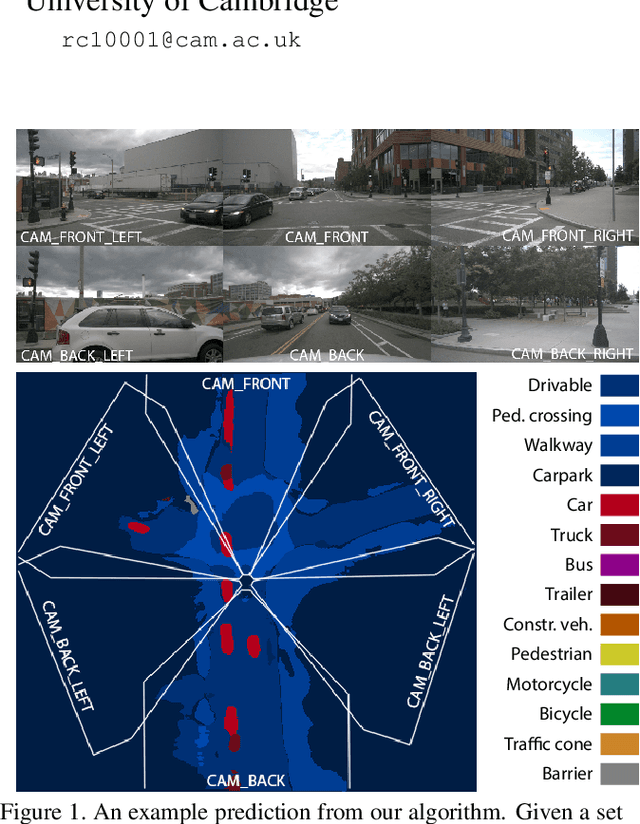
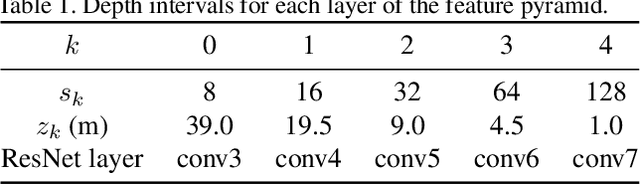
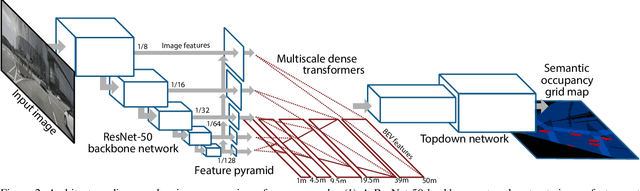
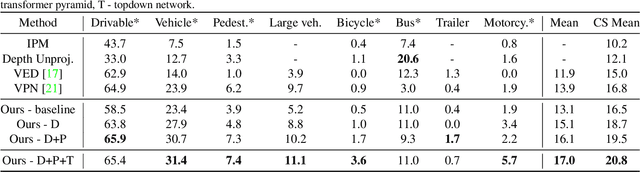
Autonomous vehicles commonly rely on highly detailed birds-eye-view maps of their environment, which capture both static elements of the scene such as road layout as well as dynamic elements such as other cars and pedestrians. Generating these map representations on the fly is a complex multi-stage process which incorporates many important vision-based elements, including ground plane estimation, road segmentation and 3D object detection. In this work we present a simple, unified approach for estimating maps directly from monocular images using a single end-to-end deep learning architecture. For the maps themselves we adopt a semantic Bayesian occupancy grid framework, allowing us to trivially accumulate information over multiple cameras and timesteps. We demonstrate the effectiveness of our approach by evaluating against several challenging baselines on the NuScenes and Argoverse datasets, and show that we are able to achieve a relative improvement of 9.1% and 22.3% respectively compared to the best-performing existing method.
Learning a Spatio-Temporal Embedding for Video Instance Segmentation
Dec 19, 2019

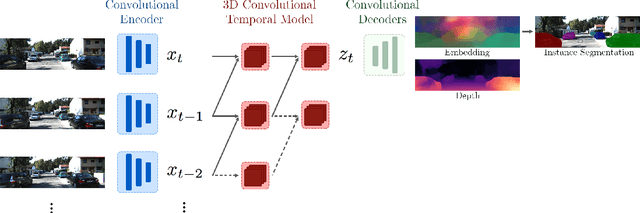
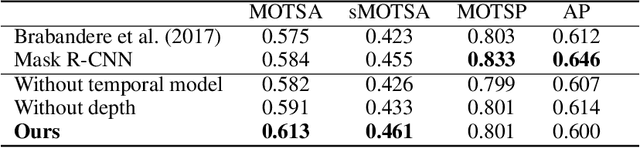
We present a novel embedding approach for video instance segmentation. Our method learns a spatio-temporal embedding integrating cues from appearance, motion, and geometry; a 3D causal convolutional network models motion, and a monocular self-supervised depth loss models geometry. In this embedding space, video-pixels of the same instance are clustered together while being separated from other instances, to naturally track instances over time without any complex post-processing. Our network runs in real-time as our architecture is entirely causal - we do not incorporate information from future frames, contrary to previous methods. We show that our model can accurately track and segment instances, even with occlusions and missed detections, advancing the state-of-the-art on the KITTI Multi-Object and Tracking Dataset.
Large Scale Joint Semantic Re-Localisation and Scene Understanding via Globally Unique Instance Coordinate Regression
Sep 23, 2019
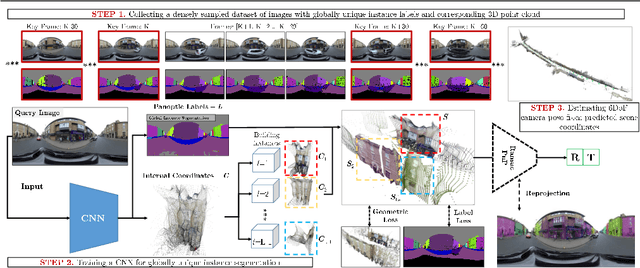

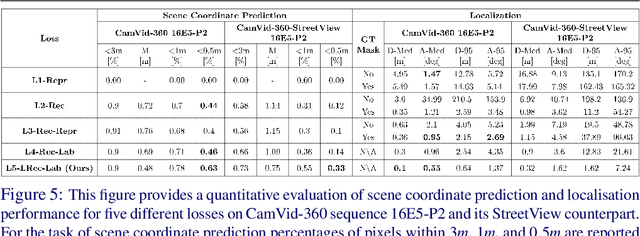
In this work we present a novel approach to joint semantic localisation and scene understanding. Our work is motivated by the need for localisation algorithms which not only predict 6-DoF camera pose but also simultaneously recognise surrounding objects and estimate 3D geometry. Such capabilities are crucial for computer vision guided systems which interact with the environment: autonomous driving, augmented reality and robotics. In particular, we propose a two step procedure. During the first step we train a convolutional neural network to jointly predict per-pixel globally unique instance labels and corresponding local coordinates for each instance of a static object (e.g. a building). During the second step we obtain scene coordinates by combining object center coordinates and local coordinates and use them to perform 6-DoF camera pose estimation. We evaluate our approach on real world (CamVid-360) and artificial (SceneCity) autonomous driving datasets. We obtain smaller mean distance and angular errors than state-of-the-art 6-DoF pose estimation algorithms based on direct pose regression and pose estimation from scene coordinates on all datasets. Our contributions include: (i) a novel formulation of scene coordinate regression as two separate tasks of object instance recognition and local coordinate regression and a demonstration that our proposed solution allows to predict accurate 3D geometry of static objects and estimate 6-DoF pose of camera on (ii) maps larger by several orders of magnitude than previously attempted by scene coordinate regression methods, as well as on (iii) lightweight, approximate 3D maps built from 3D primitives such as building-aligned cuboids.
Orientation-aware Semantic Segmentation on Icosahedron Spheres
Jul 30, 2019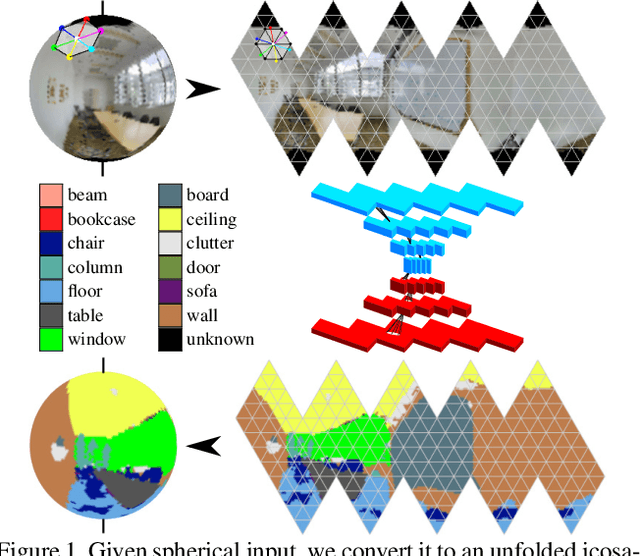
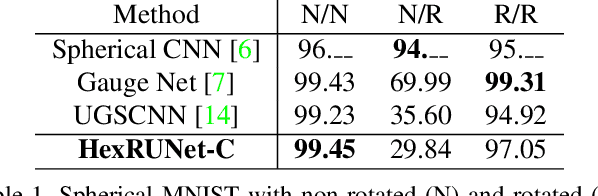
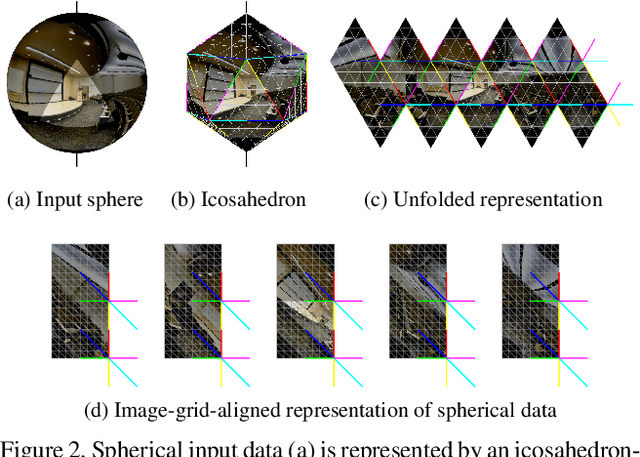
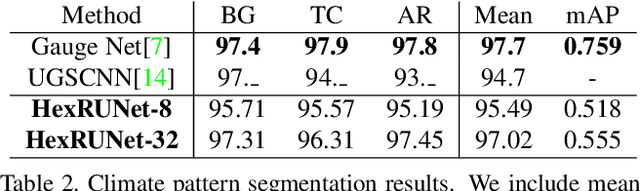
We address semantic segmentation on omnidirectional images, to leverage a holistic understanding of the surrounding scene for applications like autonomous driving systems. For the spherical domain, several methods recently adopt an icosahedron mesh, but systems are typically rotation invariant or require significant memory and parameters, thus enabling execution only at very low resolutions. In our work, we propose an orientation-aware CNN framework for the icosahedron mesh. Our representation allows for fast network operations, as our design simplifies to standard network operations of classical CNNs, but under consideration of north-aligned kernel convolutions for features on the sphere. We implement our representation and demonstrate its memory efficiency up-to a level-8 resolution mesh (equivalent to 640 x 1024 equirectangular images). Finally, since our kernels operate on the tangent of the sphere, standard feature weights, pretrained on perspective data, can be directly transferred with only small need for weight refinement. In our evaluation our orientation-aware CNN becomes a new state of the art for the recent 2D3DS dataset, and our Omni-SYNTHIA version of SYNTHIA. Rotation invariant classification and segmentation tasks are additionally presented for comparison to prior art.
Fast-SCNN: Fast Semantic Segmentation Network
Feb 12, 2019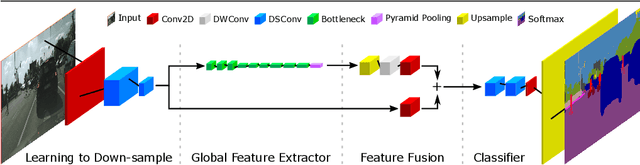
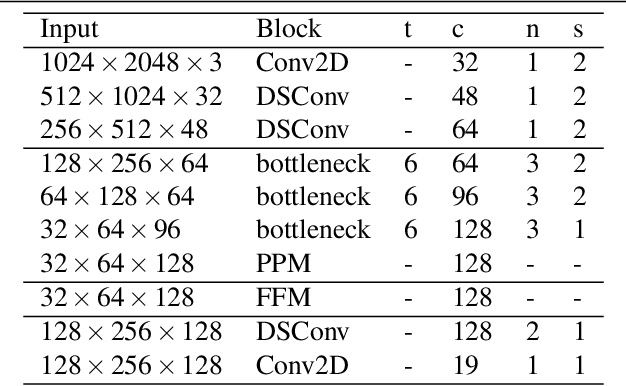


The encoder-decoder framework is state-of-the-art for offline semantic image segmentation. Since the rise in autonomous systems, real-time computation is increasingly desirable. In this paper, we introduce fast segmentation convolutional neural network (Fast-SCNN), an above real-time semantic segmentation model on high resolution image data (1024x2048px) suited to efficient computation on embedded devices with low memory. Building on existing two-branch methods for fast segmentation, we introduce our `learning to downsample' module which computes low-level features for multiple resolution branches simultaneously. Our network combines spatial detail at high resolution with deep features extracted at lower resolution, yielding an accuracy of 68.0% mean intersection over union at 123.5 frames per second on Cityscapes. We also show that large scale pre-training is unnecessary. We thoroughly validate our metric in experiments with ImageNet pre-training and the coarse labeled data of Cityscapes. Finally, we show even faster computation with competitive results on subsampled inputs, without any network modifications.