 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Assessing the Relevance of Code Reviews Authored by Generative Models
Dec 17, 2025

The use of large language models like ChatGPT in code review offers promising efficiency gains but also raises concerns about correctness and safety. Existing evaluation methods for code review generation either rely on automatic comparisons to a single ground truth, which fails to capture the variability of human perspectives, or on subjective assessments of "usefulness", a highly ambiguous concept. We propose a novel evaluation approach based on what we call multi-subjective ranking. Using a dataset of 280 self-contained code review requests and corresponding comments from CodeReview StackExchange, multiple human judges ranked the quality of ChatGPT-generated comments alongside the top human responses from the platform. Results show that ChatGPT's comments were ranked significantly better than human ones, even surpassing StackExchange's accepted answers. Going further, our proposed method motivates and enables more meaningful assessments of generative AI's performance in code review, while also raising awareness of potential risks of unchecked integration into review processes.
Previously on... Automating Code Review
Aug 25, 2025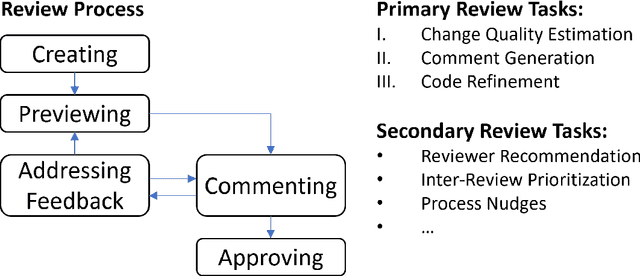
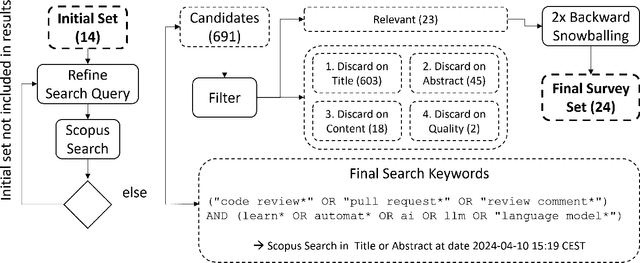
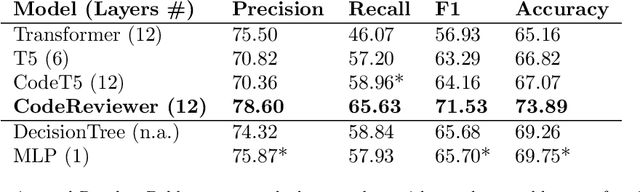
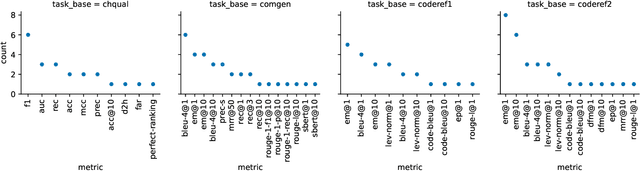
Modern Code Review (MCR) is a standard practice in software engineering, yet it demands substantial time and resource investments. Recent research has increasingly explored automating core review tasks using machine learning (ML) and deep learning (DL). As a result, there is substantial variability in task definitions, datasets, and evaluation procedures. This study provides the first comprehensive analysis of MCR automation research, aiming to characterize the field's evolution, formalize learning tasks, highlight methodological challenges, and offer actionable recommendations to guide future research. Focusing on the primary code review tasks, we systematically surveyed 691 publications and identified 24 relevant studies published between May 2015 and April 2024. Each study was analyzed in terms of tasks, models, metrics, baselines, results, validity concerns, and artifact availability. In particular, our analysis reveals significant potential for standardization, including 48 task metric combinations, 22 of which were unique to their original paper, and limited dataset reuse. We highlight challenges and derive concrete recommendations for examples such as the temporal bias threat, which are rarely addressed so far. Our work contributes to a clearer overview of the field, supports the framing of new research, helps to avoid pitfalls, and promotes greater standardization in evaluation practices.