 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreviously on... Automating Code Review
Paper and Code
Aug 25, 2025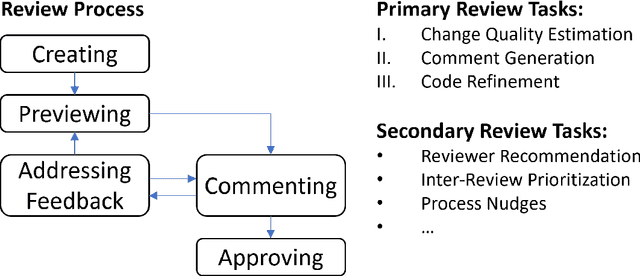
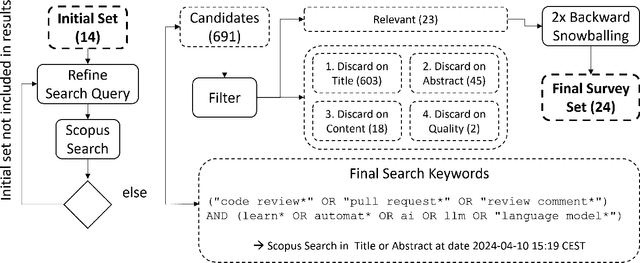
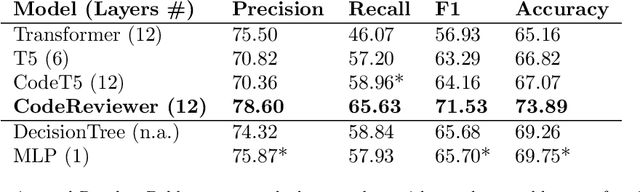
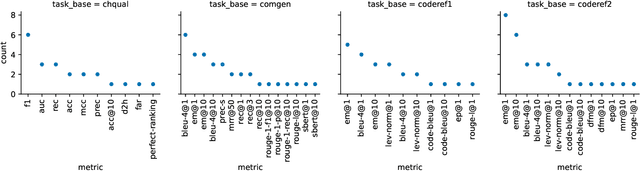
Modern Code Review (MCR) is a standard practice in software engineering, yet it demands substantial time and resource investments. Recent research has increasingly explored automating core review tasks using machine learning (ML) and deep learning (DL). As a result, there is substantial variability in task definitions, datasets, and evaluation procedures. This study provides the first comprehensive analysis of MCR automation research, aiming to characterize the field's evolution, formalize learning tasks, highlight methodological challenges, and offer actionable recommendations to guide future research. Focusing on the primary code review tasks, we systematically surveyed 691 publications and identified 24 relevant studies published between May 2015 and April 2024. Each study was analyzed in terms of tasks, models, metrics, baselines, results, validity concerns, and artifact availability. In particular, our analysis reveals significant potential for standardization, including 48 task metric combinations, 22 of which were unique to their original paper, and limited dataset reuse. We highlight challenges and derive concrete recommendations for examples such as the temporal bias threat, which are rarely addressed so far. Our work contributes to a clearer overview of the field, supports the framing of new research, helps to avoid pitfalls, and promotes greater standardization in evaluation practices.