 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormal Language Recognition by Hard Attention Transformers: Perspectives from Circuit Complexity
Apr 13, 2022
This paper analyzes three formal models of Transformer encoders that differ in the form of their self-attention mechanism: unique hard attention (UHAT); generalized unique hard attention (GUHAT), which generalizes UHAT; and averaging hard attention (AHAT). We show that UHAT and GUHAT Transformers, viewed as string acceptors, can only recognize formal languages in the complexity class AC$^0$, the class of languages recognizable by families of Boolean circuits of constant depth and polynomial size. This upper bound subsumes Hahn's (2020) results that GUHAT cannot recognize the DYCK languages or the PARITY language, since those languages are outside AC$^0$ (Furst et al., 1984). In contrast, the non-AC$^0$ languages MAJORITY and DYCK-1 are recognizable by AHAT networks, implying that AHAT can recognize languages that UHAT and GUHAT cannot.
Coloring the Blank Slate: Pre-training Imparts a Hierarchical Inductive Bias to Sequence-to-sequence Models
Mar 17, 2022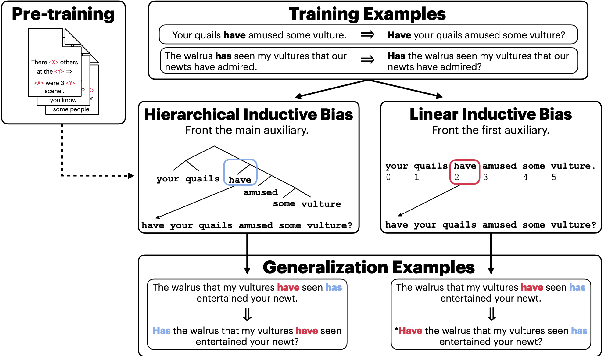


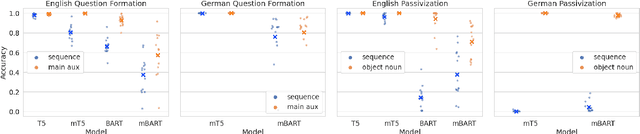
Relations between words are governed by hierarchical structure rather than linear ordering. Sequence-to-sequence (seq2seq) models, despite their success in downstream NLP applications, often fail to generalize in a hierarchy-sensitive manner when performing syntactic transformations - for example, transforming declarative sentences into questions. However, syntactic evaluations of seq2seq models have only observed models that were not pre-trained on natural language data before being trained to perform syntactic transformations, in spite of the fact that pre-training has been found to induce hierarchical linguistic generalizations in language models; in other words, the syntactic capabilities of seq2seq models may have been greatly understated. We address this gap using the pre-trained seq2seq models T5 and BART, as well as their multilingual variants mT5 and mBART. We evaluate whether they generalize hierarchically on two transformations in two languages: question formation and passivization in English and German. We find that pre-trained seq2seq models generalize hierarchically when performing syntactic transformations, whereas models trained from scratch on syntactic transformations do not. This result presents evidence for the learnability of hierarchical syntactic information from non-annotated natural language text while also demonstrating that seq2seq models are capable of syntactic generalization, though only after exposure to much more language data than human learners receive.
Do Language Models Learn Position-Role Mappings?
Feb 08, 2022How is knowledge of position-role mappings in natural language learned? We explore this question in a computational setting, testing whether a variety of well-performing pertained language models (BERT, RoBERTa, and DistilBERT) exhibit knowledge of these mappings, and whether this knowledge persists across alternations in syntactic, structural, and lexical alternations. In Experiment 1, we show that these neural models do indeed recognize distinctions between theme and recipient roles in ditransitive constructions, and that these distinct patterns are shared across construction type. We strengthen this finding in Experiment 2 by showing that fine-tuning these language models on novel theme- and recipient-like tokens in one paradigm allows the models to make correct predictions about their placement in other paradigms, suggesting that the knowledge of these mappings is shared rather than independently learned. We do, however, observe some limitations of this generalization when tasks involve constructions with novel ditransitive verbs, hinting at a degree of lexical specificity which underlies model performance.
Transformers Generalize Linearly
Sep 24, 2021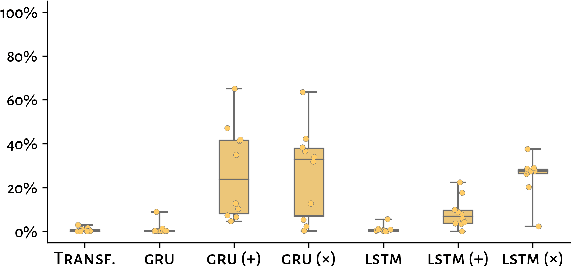
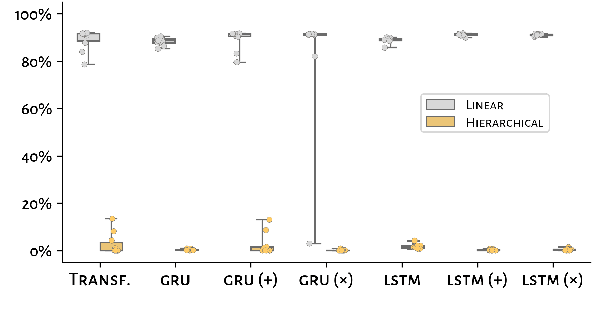
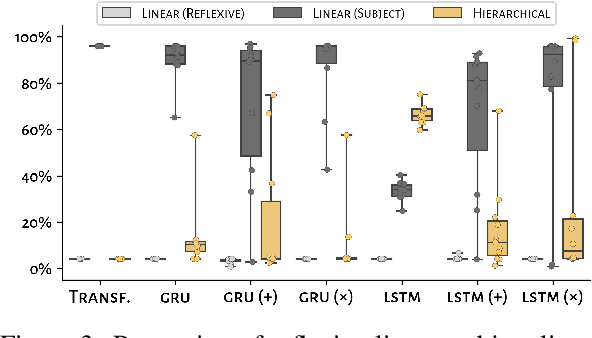
Natural language exhibits patterns of hierarchically governed dependencies, in which relations between words are sensitive to syntactic structure rather than linear ordering. While re-current network models often fail to generalize in a hierarchically sensitive way (McCoy et al.,2020) when trained on ambiguous data, the improvement in performance of newer Trans-former language models (Vaswani et al., 2017)on a range of syntactic benchmarks trained on large data sets (Goldberg, 2019; Warstadtet al., 2019) opens the question of whether these models might exhibit hierarchical generalization in the face of impoverished data.In this paper we examine patterns of structural generalization for Transformer sequence-to-sequence models and find that not only do Transformers fail to generalize hierarchically across a wide variety of grammatical mapping tasks, but they exhibit an even stronger preference for linear generalization than comparable recurrent networks
Sequence-to-Sequence Networks Learn the Meaning of Reflexive Anaphora
Nov 02, 2020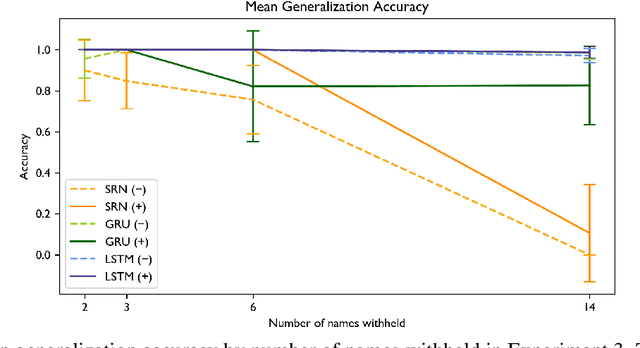
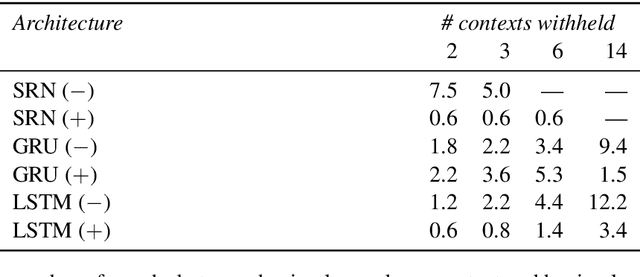
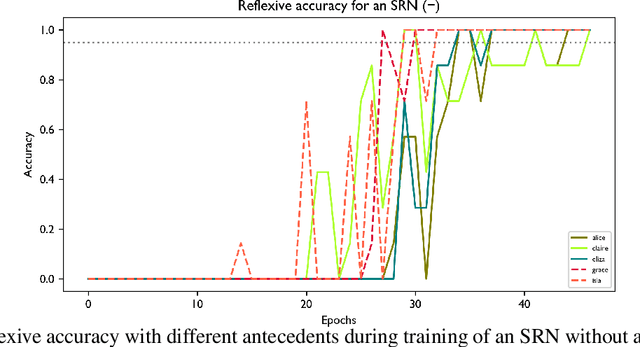
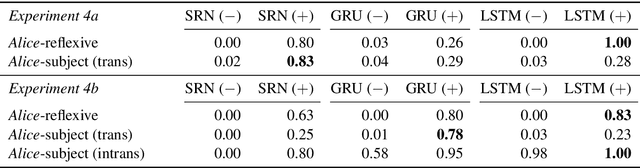
Reflexive anaphora present a challenge for semantic interpretation: their meaning varies depending on context in a way that appears to require abstract variables. Past work has raised doubts about the ability of recurrent networks to meet this challenge. In this paper, we explore this question in the context of a fragment of English that incorporates the relevant sort of contextual variability. We consider sequence-to-sequence architectures with recurrent units and show that such networks are capable of learning semantic interpretations for reflexive anaphora which generalize to novel antecedents. We explore the effect of attention mechanisms and different recurrent unit types on the type of training data that is needed for success as measured in two ways: how much lexical support is needed to induce an abstract reflexive meaning (i.e., how many distinct reflexive antecedents must occur during training) and what contexts must a noun phrase occur in to support generalization of reflexive interpretation to this noun phrase?
Probabilistic Predictions of People Perusing: Evaluating Metrics of Language Model Performance for Psycholinguistic Modeling
Sep 08, 2020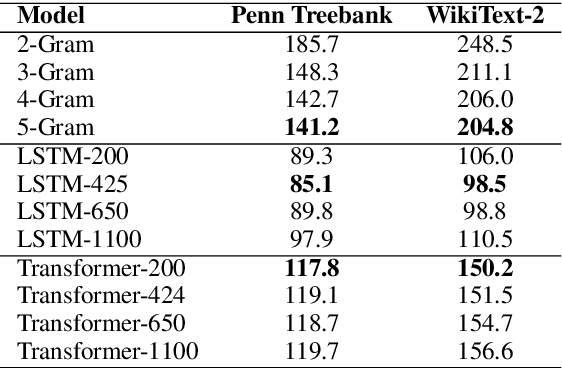
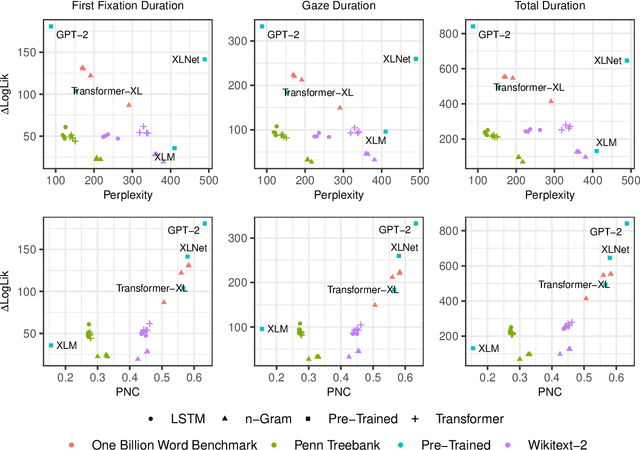
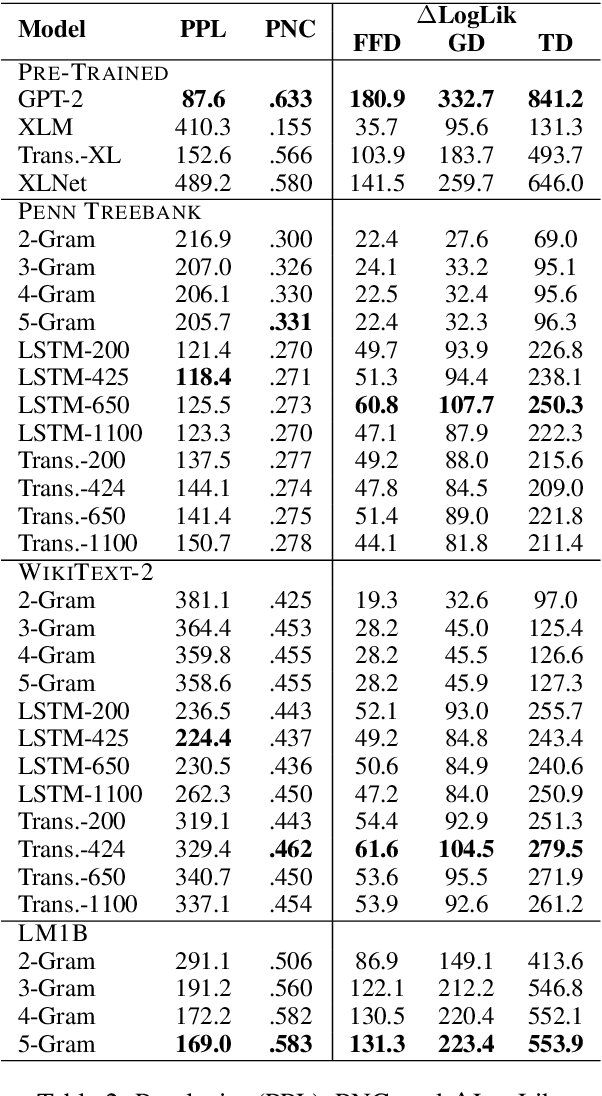
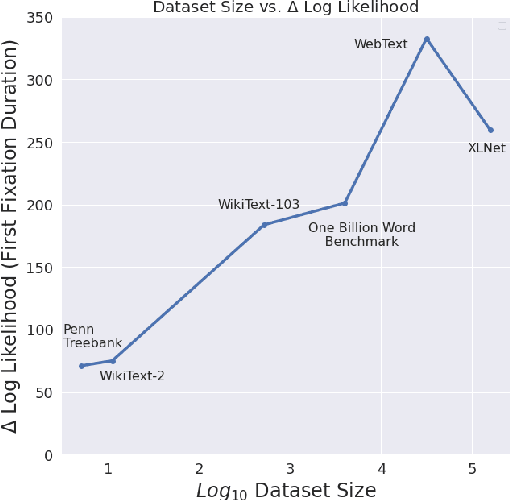
By positing a relationship between naturalistic reading times and information-theoretic surprisal, surprisal theory (Hale, 2001; Levy, 2008) provides a natural interface between language models and psycholinguistic models. This paper re-evaluates a claim due to Goodkind and Bicknell (2018) that a language model's ability to model reading times is a linear function of its perplexity. By extending Goodkind and Bicknell's analysis to modern neural architectures, we show that the proposed relation does not always hold for Long Short-Term Memory networks, Transformers, and pre-trained models. We introduce an alternate measure of language modeling performance called predictability norm correlation based on Cloze probabilities measured from human subjects. Our new metric yields a more robust relationship between language model quality and psycholinguistic modeling performance that allows for comparison between models with different training configurations.
Does syntax need to grow on trees? Sources of hierarchical inductive bias in sequence-to-sequence networks
Jan 10, 2020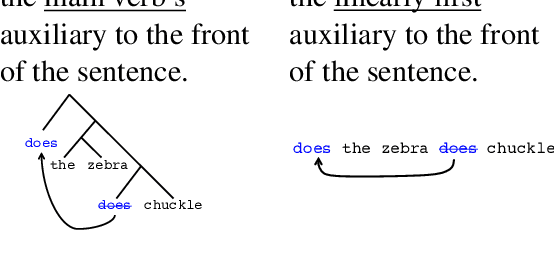

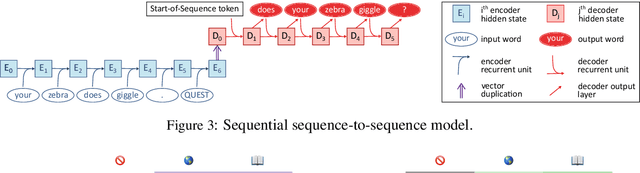

Learners that are exposed to the same training data might generalize differently due to differing inductive biases. In neural network models, inductive biases could in theory arise from any aspect of the model architecture. We investigate which architectural factors affect the generalization behavior of neural sequence-to-sequence models trained on two syntactic tasks, English question formation and English tense reinflection. For both tasks, the training set is consistent with a generalization based on hierarchical structure and a generalization based on linear order. All architectural factors that we investigated qualitatively affected how models generalized, including factors with no clear connection to hierarchical structure. For example, LSTMs and GRUs displayed qualitatively different inductive biases. However, the only factor that consistently contributed a hierarchical bias across tasks was the use of a tree-structured model rather than a model with sequential recurrence, suggesting that human-like syntactic generalization requires architectural syntactic structure.
Detecting Syntactic Change Using a Neural Part-of-Speech Tagger
Jul 09, 2019

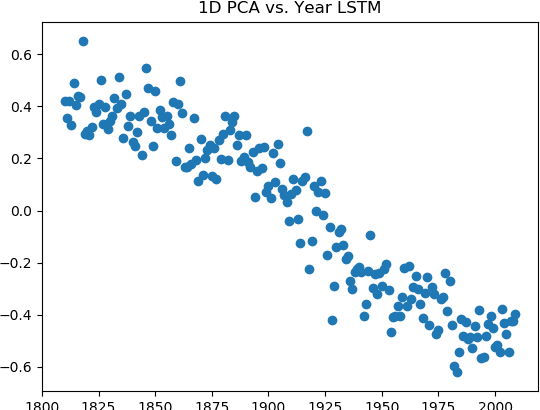

We train a diachronic long short-term memory (LSTM) part-of-speech tagger on a large corpus of American English from the 19th, 20th, and 21st centuries. We analyze the tagger's ability to implicitly learn temporal structure between years, and the extent to which this knowledge can be transferred to date new sentences. The learned year embeddings show a strong linear correlation between their first principal component and time. We show that temporal information encoded in the model can be used to predict novel sentences' years of composition relatively well. Comparisons to a feedforward baseline suggest that the temporal change learned by the LSTM is syntactic rather than purely lexical. Thus, our results suggest that our tagger is implicitly learning to model syntactic change in American English over the course of the 19th, 20th, and early 21st centuries.
Open Sesame: Getting Inside BERT's Linguistic Knowledge
Jun 04, 2019
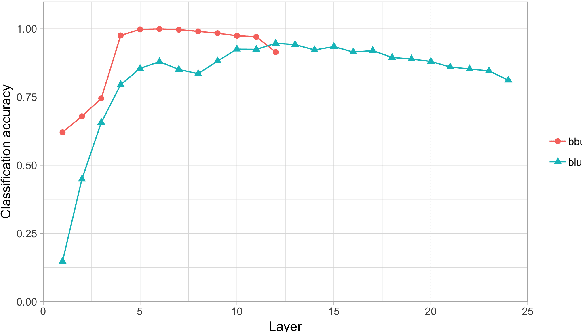
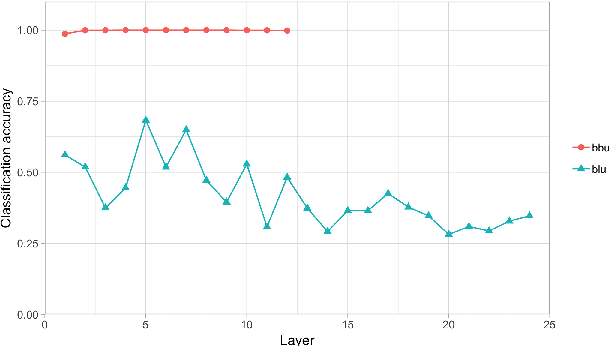
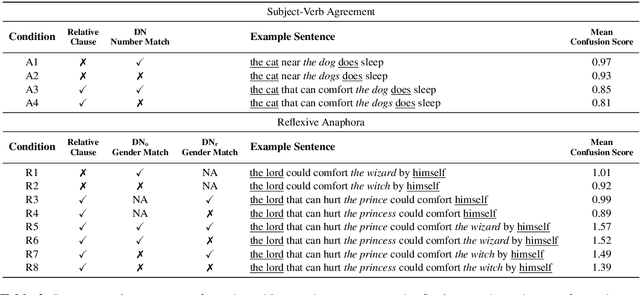
How and to what extent does BERT encode syntactically-sensitive hierarchical information or positionally-sensitive linear information? Recent work has shown that contextual representations like BERT perform well on tasks that require sensitivity to linguistic structure. We present here two studies which aim to provide a better understanding of the nature of BERT's representations. The first of these focuses on the identification of structurally-defined elements using diagnostic classifiers, while the second explores BERT's representation of subject-verb agreement and anaphor-antecedent dependencies through a quantitative assessment of self-attention vectors. In both cases, we find that BERT encodes positional information about word tokens well on its lower layers, but switches to a hierarchically-oriented encoding on higher layers. We conclude then that BERT's representations do indeed model linguistically relevant aspects of hierarchical structure, though they do not appear to show the sharp sensitivity to hierarchical structure that is found in human processing of reflexive anaphora.
Finding Syntactic Representations in Neural Stacks
Jun 04, 2019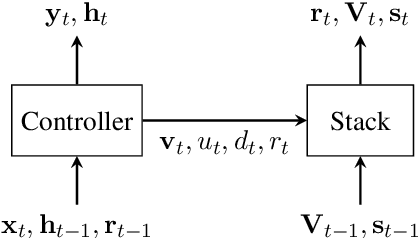
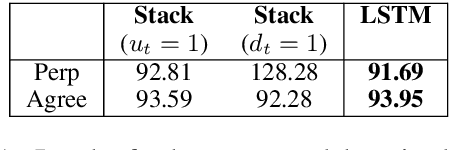
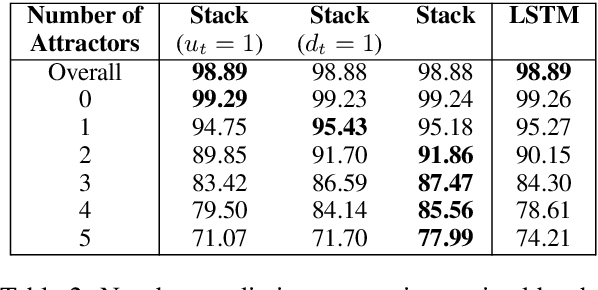
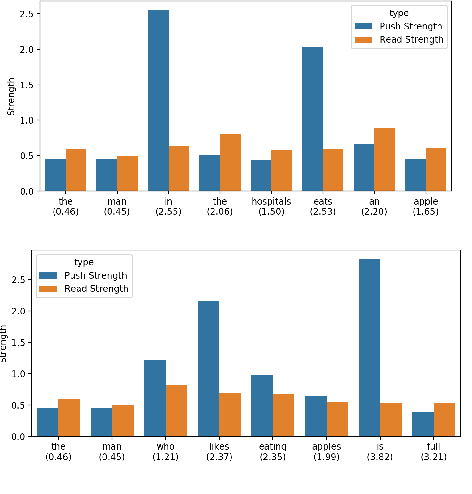
Neural network architectures have been augmented with differentiable stacks in order to introduce a bias toward learning hierarchy-sensitive regularities. It has, however, proven difficult to assess the degree to which such a bias is effective, as the operation of the differentiable stack is not always interpretable. In this paper, we attempt to detect the presence of latent representations of hierarchical structure through an exploration of the unsupervised learning of constituency structure. Using a technique due to Shen et al. (2018a,b), we extract syntactic trees from the pushing behavior of stack RNNs trained on language modeling and classification objectives. We find that our models produce parses that reflect natural language syntactic constituencies, demonstrating that stack RNNs do indeed infer linguistically relevant hierarchical structure.