 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExp-Concavity of Proper Composite Losses
May 20, 2018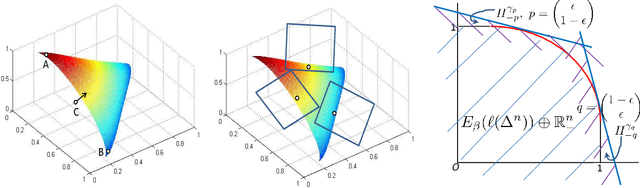
The goal of online prediction with expert advice is to find a decision strategy which will perform almost as well as the best expert in a given pool of experts, on any sequence of outcomes. This problem has been widely studied and $O(\sqrt{T})$ and $O(\log{T})$ regret bounds can be achieved for convex losses (\cite{zinkevich2003online}) and strictly convex losses with bounded first and second derivatives (\cite{hazan2007logarithmic}) respectively. In special cases like the Aggregating Algorithm (\cite{vovk1995game}) with mixable losses and the Weighted Average Algorithm (\cite{kivinen1999averaging}) with exp-concave losses, it is possible to achieve $O(1)$ regret bounds. \cite{van2012exp} has argued that mixability and exp-concavity are roughly equivalent under certain conditions. Thus by understanding the underlying relationship between these two notions we can gain the best of both algorithms (strong theoretical performance guarantees of the Aggregating Algorithm and the computational efficiency of the Weighted Average Algorithm). In this paper we provide a complete characterization of the exp-concavity of any proper composite loss. Using this characterization and the mixability condition of proper losses (\cite{van2012mixability}), we show that it is possible to transform (re-parameterize) any $\beta$-mixable binary proper loss into a $\beta$-exp-concave composite loss with the same $\beta$. In the multi-class case, we propose an approximation approach for this transformation.
Minimax Lower Bounds for Cost Sensitive Classification
May 20, 2018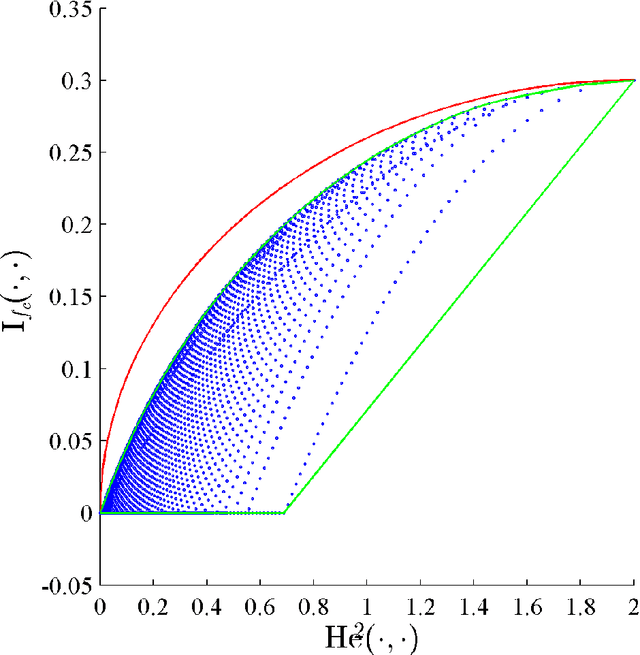
The cost-sensitive classification problem plays a crucial role in mission-critical machine learning applications, and differs with traditional classification by taking the misclassification costs into consideration. Although being studied extensively in the literature, the fundamental limits of this problem are still not well understood. We investigate the hardness of this problem by extending the standard minimax lower bound of balanced binary classification problem (due to \cite{massart2006risk}), and emphasize the impact of cost terms on the hardness.
Provably Fair Representations
Oct 12, 2017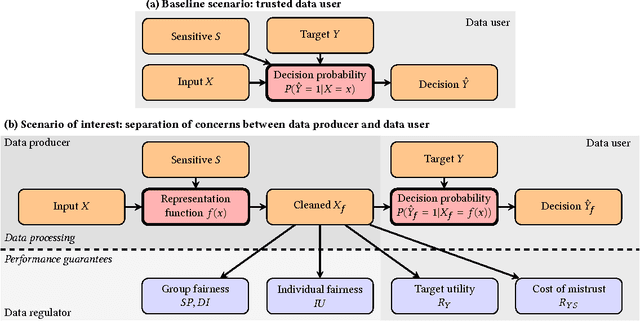

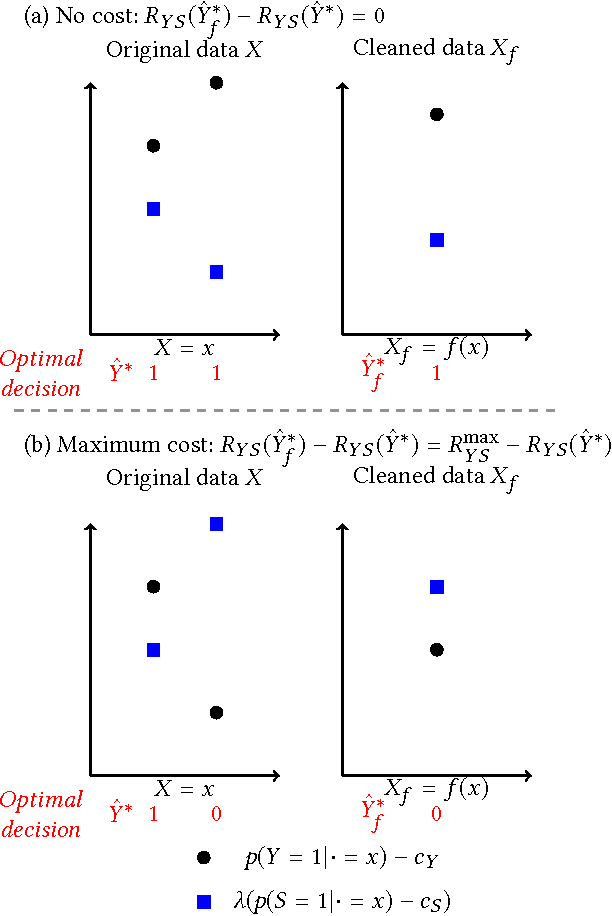
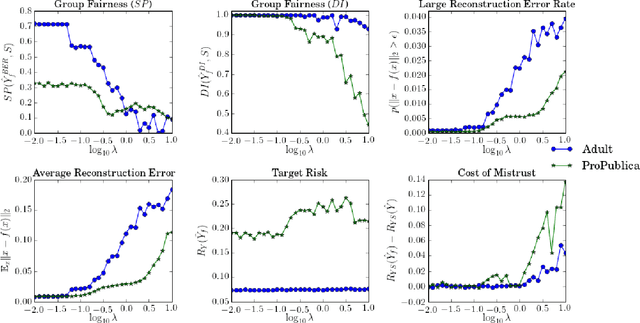
Machine learning systems are increasingly used to make decisions about people's lives, such as whether to give someone a loan or whether to interview someone for a job. This has led to considerable interest in making such machine learning systems fair. One approach is to transform the input data used by the algorithm. This can be achieved by passing each input data point through a representation function prior to its use in training or testing. Techniques for learning such representation functions from data have been successful empirically, but typically lack theoretical fairness guarantees. We show that it is possible to prove that a representation function is fair according to common measures of both group and individual fairness, as well as useful with respect to a target task. These provable properties can be used in a governance model involving a data producer, a data user and a data regulator, where there is a separation of concerns between fairness and target task utility to ensure transparency and prevent perverse incentives. We formally define the 'cost of mistrust' of using this model compared to the setting where there is a single trusted party, and provide bounds on this cost in particular cases. We present a practical approach to learning fair representation functions and apply it to financial and criminal justice datasets. We evaluate the fairness and utility of these representation functions using measures motivated by our theoretical results.
f-GANs in an Information Geometric Nutshell
Jul 14, 2017

Nowozin \textit{et al} showed last year how to extend the GAN \textit{principle} to all $f$-divergences. The approach is elegant but falls short of a full description of the supervised game, and says little about the key player, the generator: for example, what does the generator actually converge to if solving the GAN game means convergence in some space of parameters? How does that provide hints on the generator's design and compare to the flourishing but almost exclusively experimental literature on the subject? In this paper, we unveil a broad class of distributions for which such convergence happens --- namely, deformed exponential families, a wide superset of exponential families --- and show tight connections with the three other key GAN parameters: loss, game and architecture. In particular, we show that current deep architectures are able to factorize a very large number of such densities using an especially compact design, hence displaying the power of deep architectures and their concinnity in the $f$-GAN game. This result holds given a sufficient condition on \textit{activation functions} --- which turns out to be satisfied by popular choices. The key to our results is a variational generalization of an old theorem that relates the KL divergence between regular exponential families and divergences between their natural parameters. We complete this picture with additional results and experimental insights on how these results may be used to ground further improvements of GAN architectures, via (i) a principled design of the activation functions in the generator and (ii) an explicit integration of proper composite losses' link function in the discriminator.
The cost of fairness in classification
May 25, 2017

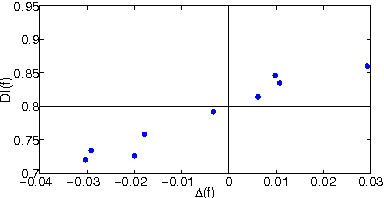
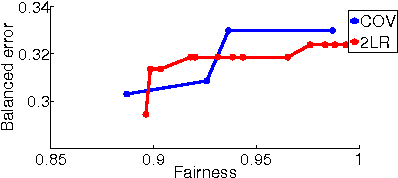
We study the problem of learning classifiers with a fairness constraint, with three main contributions towards the goal of quantifying the problem's inherent tradeoffs. First, we relate two existing fairness measures to cost-sensitive risks. Second, we show that for cost-sensitive classification and fairness measures, the optimal classifier is an instance-dependent thresholding of the class-probability function. Third, we show how the tradeoff between accuracy and fairness is determined by the alignment between the class-probabilities for the target and sensitive features. Underpinning our analysis is a general framework that casts the problem of learning with a fairness requirement as one of minimising the difference of two statistical risks.
A Modular Theory of Feature Learning
Nov 09, 2016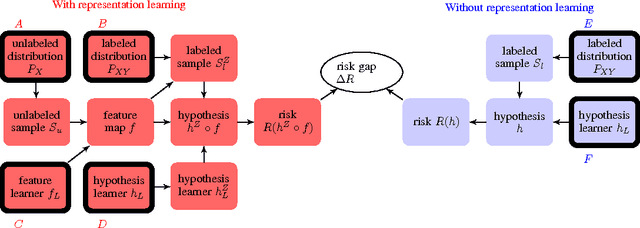
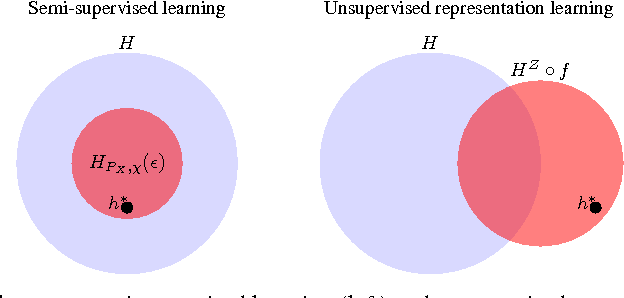
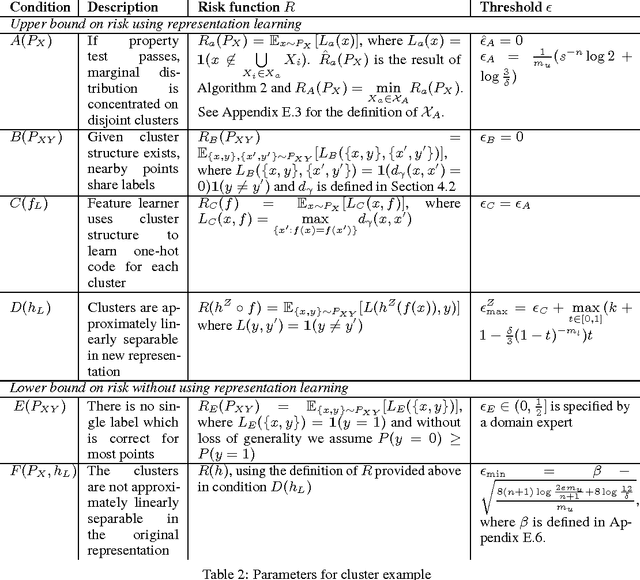
Learning representations of data, and in particular learning features for a subsequent prediction task, has been a fruitful area of research delivering impressive empirical results in recent years. However, relatively little is understood about what makes a representation `good'. We propose the idea of a risk gap induced by representation learning for a given prediction context, which measures the difference in the risk of some learner using the learned features as compared to the original inputs. We describe a set of sufficient conditions for unsupervised representation learning to provide a benefit, as measured by this risk gap. These conditions decompose the problem of when representation learning works into its constituent parts, which can be separately evaluated using an unlabeled sample, suitable domain-specific assumptions about the joint distribution, and analysis of the feature learner and subsequent supervised learner. We provide two examples of such conditions in the context of specific properties of the unlabeled distribution, namely when the data lies close to a low-dimensional manifold and when it forms clusters. We compare our approach to a recently proposed analysis of semi-supervised learning.
An Average Classification Algorithm
Dec 15, 2015
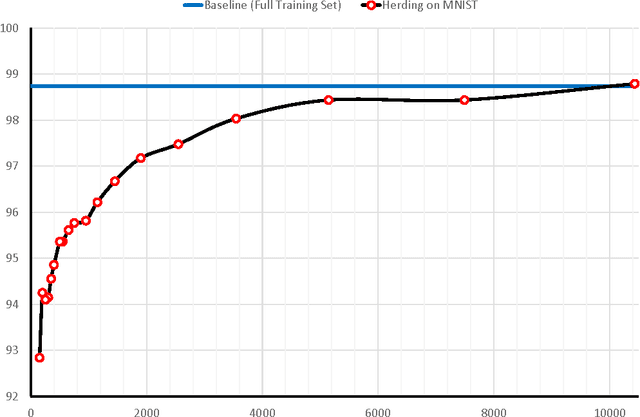
Many classification algorithms produce a classifier that is a weighted average of kernel evaluations. When working with a high or infinite dimensional kernel, it is imperative for speed of evaluation and storage issues that as few training samples as possible are used in the kernel expansion. Popular existing approaches focus on altering standard learning algorithms, such as the Support Vector Machine, to induce sparsity, as well as post-hoc procedures for sparse approximations. Here we adopt the latter approach. We begin with a very simple classifier, given by the kernel mean $$ f(x) = \frac{1}{n} \sum\limits_{i=i}^{n} y_i K(x_i,x) $$ We then find a sparse approximation to this kernel mean via herding. The result is an accurate, easily parallelized algorithm for learning classifiers.
Fast rates in statistical and online learning
Sep 01, 2015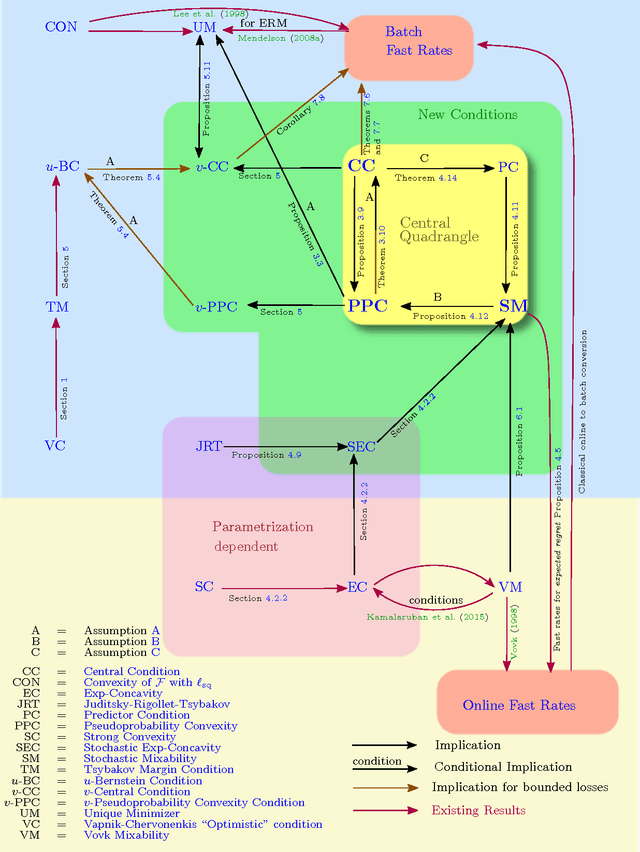
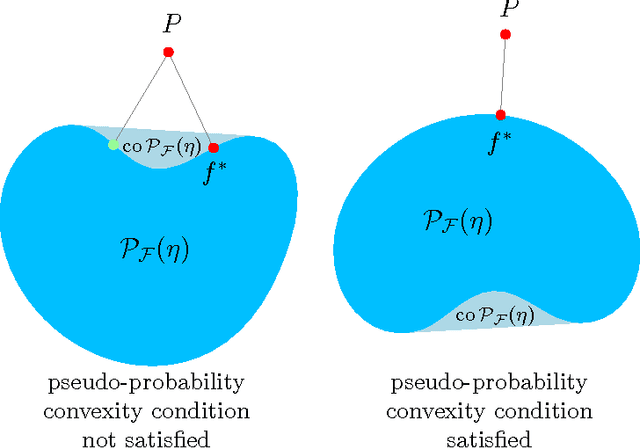
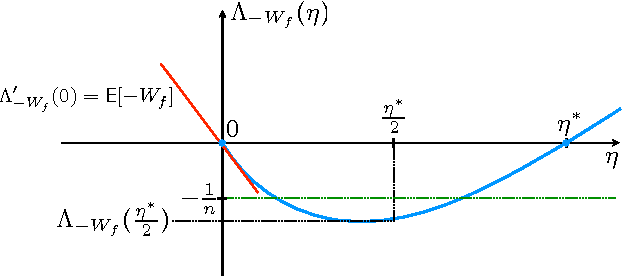
The speed with which a learning algorithm converges as it is presented with more data is a central problem in machine learning --- a fast rate of convergence means less data is needed for the same level of performance. The pursuit of fast rates in online and statistical learning has led to the discovery of many conditions in learning theory under which fast learning is possible. We show that most of these conditions are special cases of a single, unifying condition, that comes in two forms: the central condition for 'proper' learning algorithms that always output a hypothesis in the given model, and stochastic mixability for online algorithms that may make predictions outside of the model. We show that under surprisingly weak assumptions both conditions are, in a certain sense, equivalent. The central condition has a re-interpretation in terms of convexity of a set of pseudoprobabilities, linking it to density estimation under misspecification. For bounded losses, we show how the central condition enables a direct proof of fast rates and we prove its equivalence to the Bernstein condition, itself a generalization of the Tsybakov margin condition, both of which have played a central role in obtaining fast rates in statistical learning. Yet, while the Bernstein condition is two-sided, the central condition is one-sided, making it more suitable to deal with unbounded losses. In its stochastic mixability form, our condition generalizes both a stochastic exp-concavity condition identified by Juditsky, Rigollet and Tsybakov and Vovk's notion of mixability. Our unifying conditions thus provide a substantial step towards a characterization of fast rates in statistical learning, similar to how classical mixability characterizes constant regret in the sequential prediction with expert advice setting.
Learning in the Presence of Corruption
Jul 04, 2015
In supervised learning one wishes to identify a pattern present in a joint distribution $P$, of instances, label pairs, by providing a function $f$ from instances to labels that has low risk $\mathbb{E}_{P}\ell(y,f(x))$. To do so, the learner is given access to $n$ iid samples drawn from $P$. In many real world problems clean samples are not available. Rather, the learner is given access to samples from a corrupted distribution $\tilde{P}$ from which to learn, while the goal of predicting the clean pattern remains. There are many different types of corruption one can consider, and as of yet there is no general means to compare the relative ease of learning under these different corruption processes. In this paper we develop a general framework for tackling such problems as well as introducing upper and lower bounds on the risk for learning in the presence of corruption. Our ultimate goal is to be able to make informed economic decisions in regards to the acquisition of data sets. For a certain subclass of corruption processes (those that are \emph{reconstructible}) we achieve this goal in a particular sense. Our lower bounds are in terms of the coefficient of ergodicity, a simple to calculate property of stochastic matrices. Our upper bounds proceed via a generalization of the method of unbiased estimators appearing in recent work of Natarajan et al and implicit in the earlier work of Kearns.
Learning with Symmetric Label Noise: The Importance of Being Unhinged
May 28, 2015
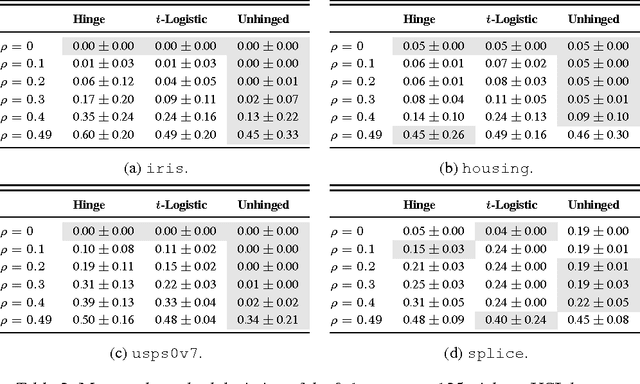
Convex potential minimisation is the de facto approach to binary classification. However, Long and Servedio [2010] proved that under symmetric label noise (SLN), minimisation of any convex potential over a linear function class can result in classification performance equivalent to random guessing. This ostensibly shows that convex losses are not SLN-robust. In this paper, we propose a convex, classification-calibrated loss and prove that it is SLN-robust. The loss avoids the Long and Servedio [2010] result by virtue of being negatively unbounded. The loss is a modification of the hinge loss, where one does not clamp at zero; hence, we call it the unhinged loss. We show that the optimal unhinged solution is equivalent to that of a strongly regularised SVM, and is the limiting solution for any convex potential; this implies that strong l2 regularisation makes most standard learners SLN-robust. Experiments confirm the SLN-robustness of the unhinged loss.