 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Fair Representations
Oct 12, 2017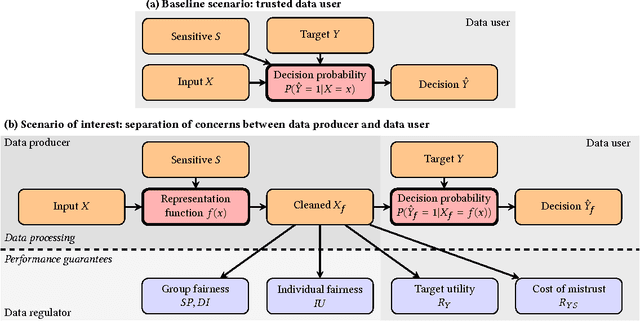

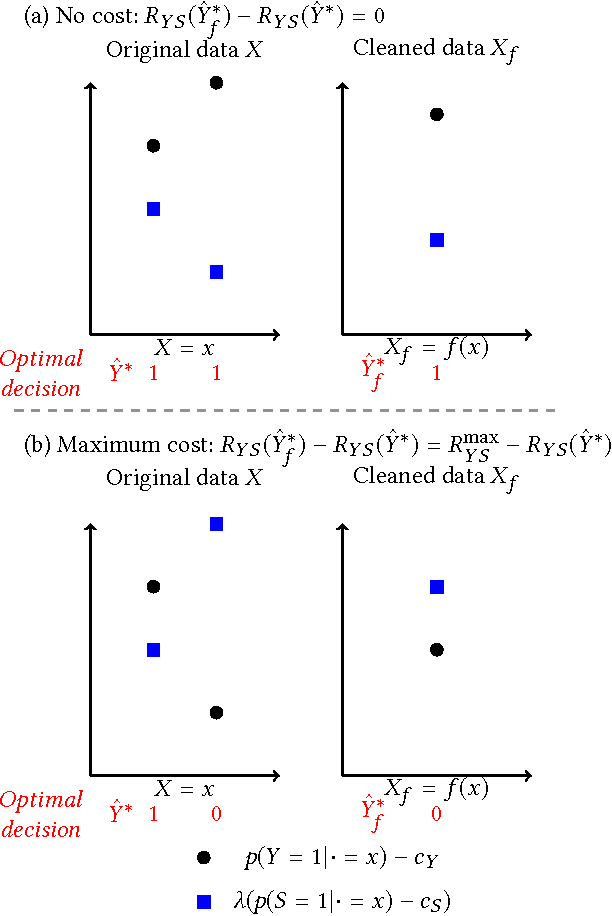
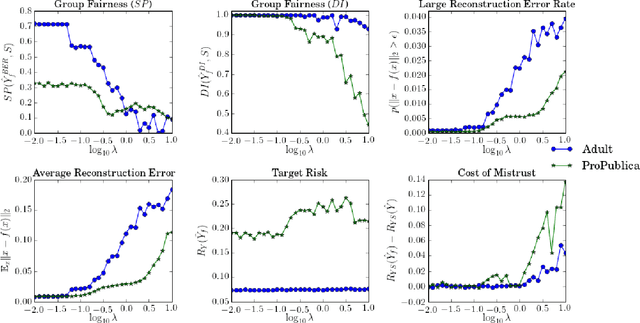
Machine learning systems are increasingly used to make decisions about people's lives, such as whether to give someone a loan or whether to interview someone for a job. This has led to considerable interest in making such machine learning systems fair. One approach is to transform the input data used by the algorithm. This can be achieved by passing each input data point through a representation function prior to its use in training or testing. Techniques for learning such representation functions from data have been successful empirically, but typically lack theoretical fairness guarantees. We show that it is possible to prove that a representation function is fair according to common measures of both group and individual fairness, as well as useful with respect to a target task. These provable properties can be used in a governance model involving a data producer, a data user and a data regulator, where there is a separation of concerns between fairness and target task utility to ensure transparency and prevent perverse incentives. We formally define the 'cost of mistrust' of using this model compared to the setting where there is a single trusted party, and provide bounds on this cost in particular cases. We present a practical approach to learning fair representation functions and apply it to financial and criminal justice datasets. We evaluate the fairness and utility of these representation functions using measures motivated by our theoretical results.
A Modular Theory of Feature Learning
Nov 09, 2016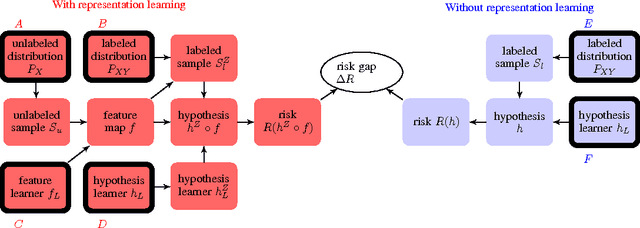
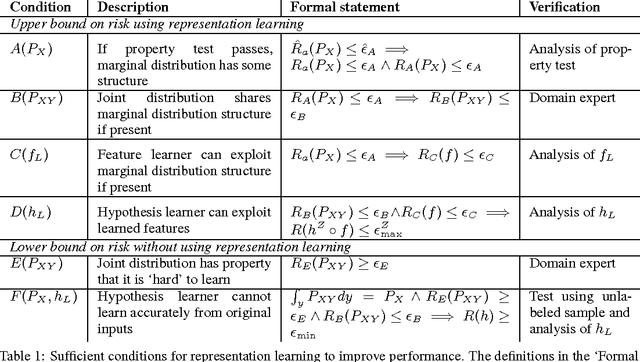
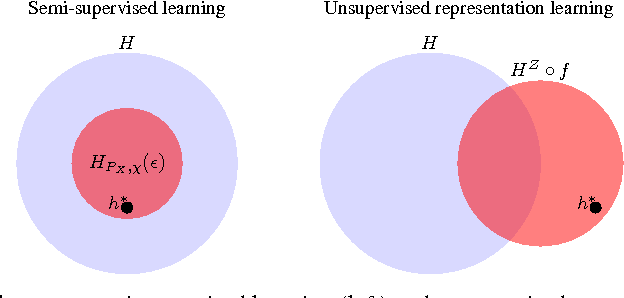
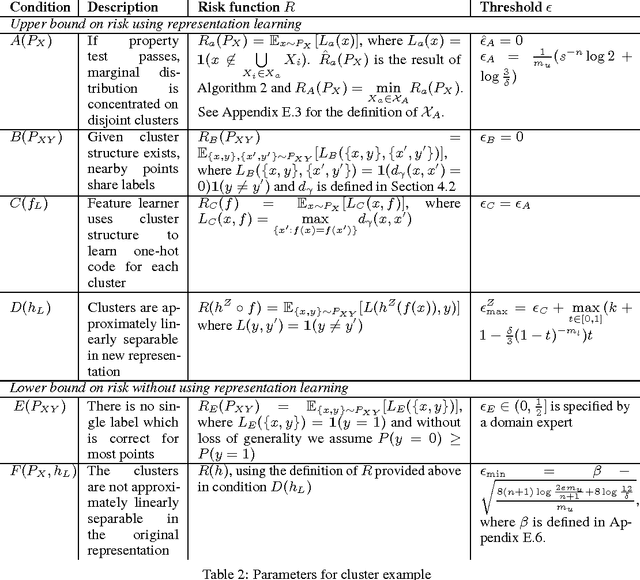
Learning representations of data, and in particular learning features for a subsequent prediction task, has been a fruitful area of research delivering impressive empirical results in recent years. However, relatively little is understood about what makes a representation `good'. We propose the idea of a risk gap induced by representation learning for a given prediction context, which measures the difference in the risk of some learner using the learned features as compared to the original inputs. We describe a set of sufficient conditions for unsupervised representation learning to provide a benefit, as measured by this risk gap. These conditions decompose the problem of when representation learning works into its constituent parts, which can be separately evaluated using an unlabeled sample, suitable domain-specific assumptions about the joint distribution, and analysis of the feature learner and subsequent supervised learner. We provide two examples of such conditions in the context of specific properties of the unlabeled distribution, namely when the data lies close to a low-dimensional manifold and when it forms clusters. We compare our approach to a recently proposed analysis of semi-supervised learning.