 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Adaptive Agent Training in Open-Ended Simulators by Targeting Diversity
Nov 07, 2024The wider application of end-to-end learning methods to embodied decision-making domains remains bottlenecked by their reliance on a superabundance of training data representative of the target domain. Meta-reinforcement learning (meta-RL) approaches abandon the aim of zero-shot generalization--the goal of standard reinforcement learning (RL)--in favor of few-shot adaptation, and thus hold promise for bridging larger generalization gaps. While learning this meta-level adaptive behavior still requires substantial data, efficient environment simulators approaching real-world complexity are growing in prevalence. Even so, hand-designing sufficiently diverse and numerous simulated training tasks for these complex domains is prohibitively labor-intensive. Domain randomization (DR) and procedural generation (PG), offered as solutions to this problem, require simulators to possess carefully-defined parameters which directly translate to meaningful task diversity--a similarly prohibitive assumption. In this work, we present DIVA, an evolutionary approach for generating diverse training tasks in such complex, open-ended simulators. Like unsupervised environment design (UED) methods, DIVA can be applied to arbitrary parameterizations, but can additionally incorporate realistically-available domain knowledge--thus inheriting the flexibility and generality of UED, and the supervised structure embedded in well-designed simulators exploited by DR and PG. Our empirical results showcase DIVA's unique ability to overcome complex parameterizations and successfully train adaptive agent behavior, far outperforming competitive baselines from prior literature. These findings highlight the potential of such semi-supervised environment design (SSED) approaches, of which DIVA is the first humble constituent, to enable training in realistic simulated domains, and produce more robust and capable adaptive agents.
ALMA: Hierarchical Learning for Composite Multi-Agent Tasks
May 27, 2022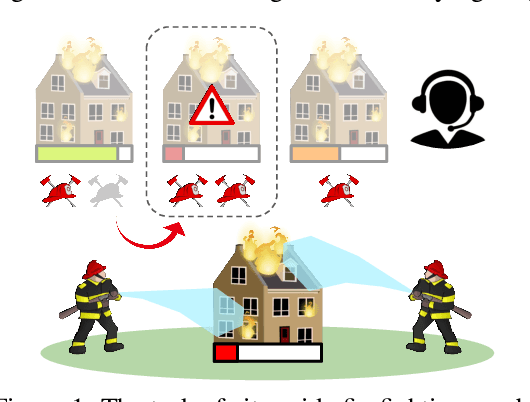

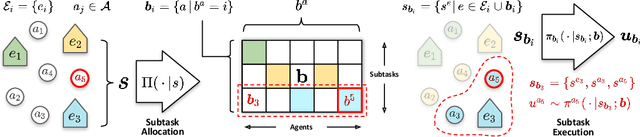
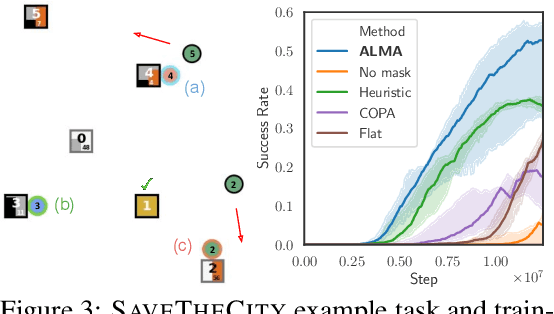
Despite significant progress on multi-agent reinforcement learning (MARL) in recent years, coordination in complex domains remains a challenge. Work in MARL often focuses on solving tasks where agents interact with all other agents and entities in the environment; however, we observe that real-world tasks are often composed of several isolated instances of local agent interactions (subtasks), and each agent can meaningfully focus on one subtask to the exclusion of all else in the environment. In these composite tasks, successful policies can often be decomposed into two levels of decision-making: agents are allocated to specific subtasks and each agent acts productively towards their assigned subtask alone. This decomposed decision making provides a strong structural inductive bias, significantly reduces agent observation spaces, and encourages subtask-specific policies to be reused and composed during training, as opposed to treating each new composition of subtasks as unique. We introduce ALMA, a general learning method for taking advantage of these structured tasks. ALMA simultaneously learns a high-level subtask allocation policy and low-level agent policies. We demonstrate that ALMA learns sophisticated coordination behavior in a number of challenging environments, outperforming strong baselines. ALMA's modularity also enables it to better generalize to new environment configurations. Finally, we find that while ALMA can integrate separately trained allocation and action policies, the best performance is obtained only by training all components jointly.
Possibility Before Utility: Learning And Using Hierarchical Affordances
Mar 23, 2022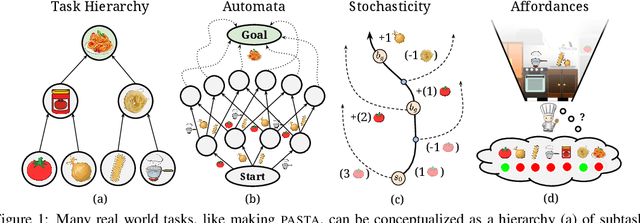
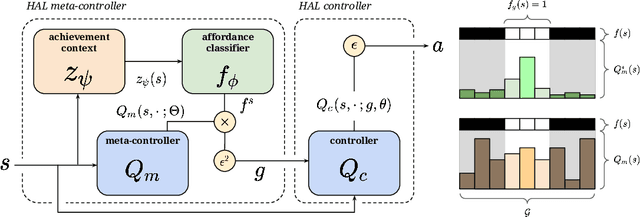
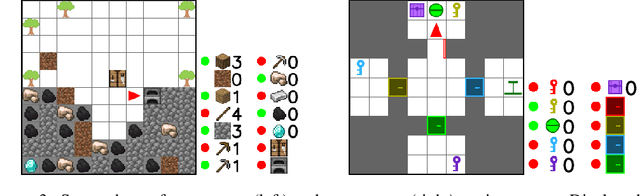
Reinforcement learning algorithms struggle on tasks with complex hierarchical dependency structures. Humans and other intelligent agents do not waste time assessing the utility of every high-level action in existence, but instead only consider ones they deem possible in the first place. By focusing only on what is feasible, or "afforded", at the present moment, an agent can spend more time both evaluating the utility of and acting on what matters. To this end, we present Hierarchical Affordance Learning (HAL), a method that learns a model of hierarchical affordances in order to prune impossible subtasks for more effective learning. Existing works in hierarchical reinforcement learning provide agents with structural representations of subtasks but are not affordance-aware, and by grounding our definition of hierarchical affordances in the present state, our approach is more flexible than the multitude of approaches that ground their subtask dependencies in a symbolic history. While these logic-based methods often require complete knowledge of the subtask hierarchy, our approach is able to utilize incomplete and varying symbolic specifications. Furthermore, we demonstrate that relative to non-affordance-aware methods, HAL agents are better able to efficiently learn complex tasks, navigate environment stochasticity, and acquire diverse skills in the absence of extrinsic supervision -- all of which are hallmarks of human learning.
Live Trojan Attacks on Deep Neural Networks
May 27, 2020
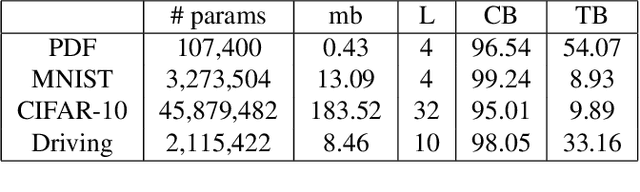
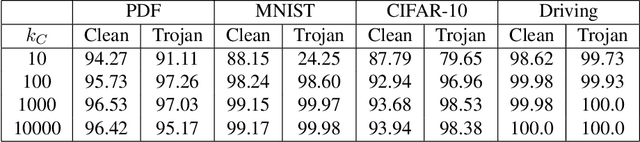
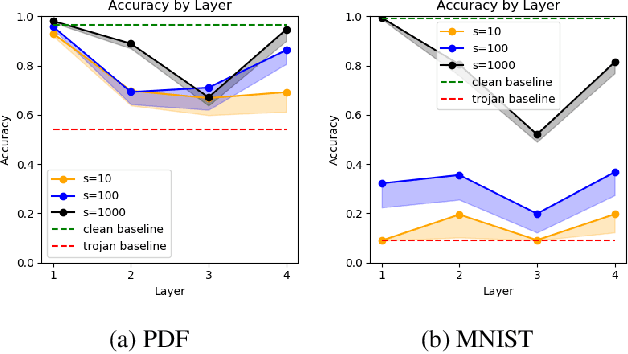
Like all software systems, the execution of deep learning models is dictated in part by logic represented as data in memory. For decades, attackers have exploited traditional software programs by manipulating this data. We propose a live attack on deep learning systems that patches model parameters in memory to achieve predefined malicious behavior on a certain set of inputs. By minimizing the size and number of these patches, the attacker can reduce the amount of network communication and memory overwrites, with minimal risk of system malfunctions or other detectable side effects. We demonstrate the feasibility of this attack by computing efficient patches on multiple deep learning models. We show that the desired trojan behavior can be induced with a few small patches and with limited access to training data. We describe the details of how this attack is carried out on real systems and provide sample code for patching TensorFlow model parameters in Windows and in Linux. Lastly, we present a technique for effectively manipulating entropy on perturbed inputs to bypass STRIP, a state-of-the-art run-time trojan detection technique.