 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUET -- Dual User Embedding Transformers for Offsite Conversion Prediction
Jun 08, 2026Offsite conversion rate (OCVR) prediction is an important ranking problem in computational recommendation systems. This task presents a modeling challenge: click signals are abundant and exhibit short temporal horizons, whereas conversion signals are inherently sparse, long-delayed, and frequently unattributed. Despite these statistical disparities, both signal types must inform models that operate within strict serving-latency constraints. Prior pre-training approaches address this heterogeneity with a single, undifferentiated encoder applied uniformly across both data streams. We propose DUET (Dual User Embedding Transformers), a framework that explicitly partitions user behavioral data into two domain-coherent streams -- clicks and conversions -- and pre-trains dedicated transformer encoders with architectures tailored to each stream's statistical characteristics: multi-layer self-attention for the dense click stream and interleaved cross- and self-attention for the sparse conversion stream. The resulting complementary embeddings are jointly consumed by a downstream ranker without exceeding serving-latency budgets. Evaluation demonstrates up to 0.38% normalized entropy (NE) reduction relative to the strongest baseline, and A/B test shows consistent improvements in OCVR prediction accuracy.
Synthetic Data from Cross-Domain Events for Large-Scale Recommendation Systems
May 29, 2026Large-scale recommendation systems operate across diverse domains, yet they face the challenges of data sparsity and noisy implicit feedback. Traditional approaches mitigate this via model-specific knowledge distillation from source domains to a target domain. Inspired by the transformative success of synthetic data generation in large language models (LLMs), we introduce Synthetic Cross-domain Augmentation and Learning for Recommendation (SCALR), a framework that generates synthetic user-item interaction events for a target recommendation domain by leveraging observed events from a source domain. SCALR decomposes cross-domain learning into two modular stages. First, it translates observed user events in source domains by framing event generation as estimating the likelihood that a user would interact with a target-domain item, conditioned on their observed interactions in a source domain. Second, downstream models train on these synthetic events as cross-domain learning objectives, where the synthetic events augment the target domain's training data in a model-agnostic manner. Our approach yields statistically significant improvements in online A/B tests on an industrial recommendation platform. To the best of our knowledge, this is among the first works to explicitly frame cross-domain event transfer as synthetic data generation for recommendation systems.
Snorkel DryBell: A Case Study in Deploying Weak Supervision at Industrial Scale
Dec 02, 2018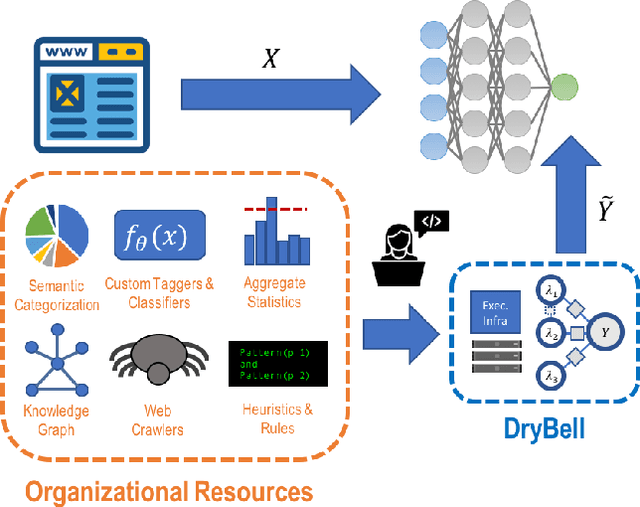

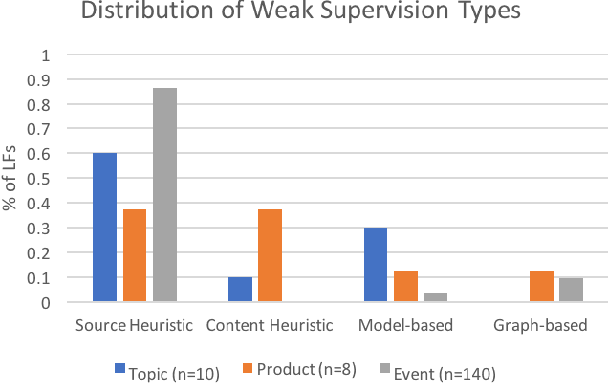

Labeling training data is one of the most costly bottlenecks in developing or modifying machine learning-based applications. We survey how resources from across an organization can be used as weak supervision sources for three classification tasks at Google, in order to bring development time and cost down by an order of magnitude. We build on the Snorkel framework, extending it as a new system, Snorkel DryBell, which integrates with Google's distributed production systems and enables engineers to develop and execute weak supervision strategies over millions of examples in less than thirty minutes. We find that Snorkel DryBell creates classifiers of comparable quality to ones trained using up to tens of thousands of hand-labeled examples, in part by leveraging organizational resources not servable in production which contribute an average 52% performance improvement to the weakly supervised classifiers.