 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummary - TerpreT: A Probabilistic Programming Language for Program Induction
Dec 02, 2016
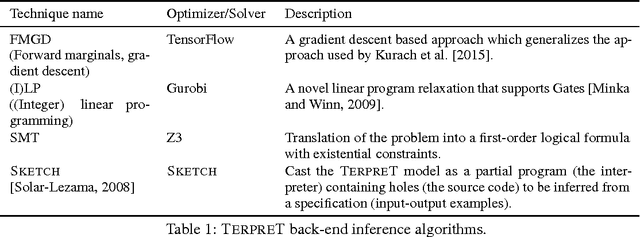
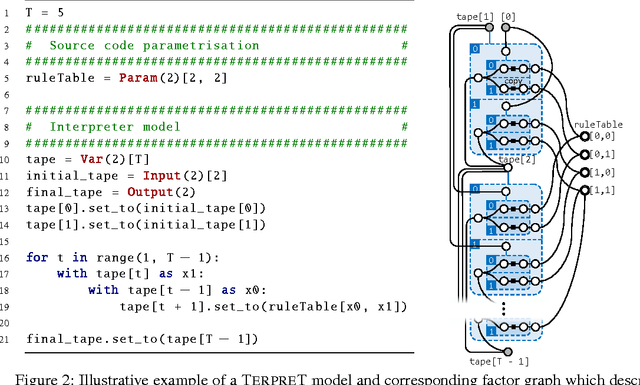
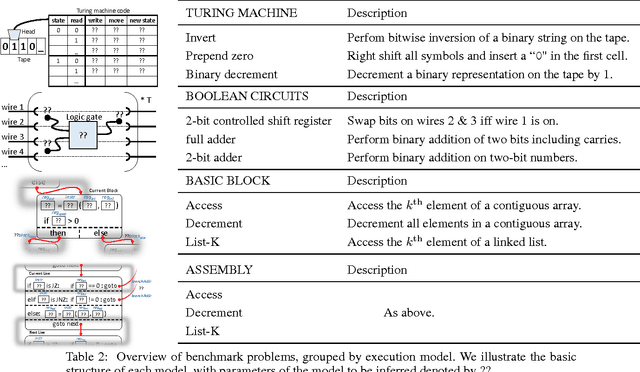
We study machine learning formulations of inductive program synthesis; that is, given input-output examples, synthesize source code that maps inputs to corresponding outputs. Our key contribution is TerpreT, a domain-specific language for expressing program synthesis problems. A TerpreT model is composed of a specification of a program representation and an interpreter that describes how programs map inputs to outputs. The inference task is to observe a set of input-output examples and infer the underlying program. From a TerpreT model we automatically perform inference using four different back-ends: gradient descent (thus each TerpreT model can be seen as defining a differentiable interpreter), linear program (LP) relaxations for graphical models, discrete satisfiability solving, and the Sketch program synthesis system. TerpreT has two main benefits. First, it enables rapid exploration of a range of domains, program representations, and interpreter models. Second, it separates the model specification from the inference algorithm, allowing proper comparisons between different approaches to inference. We illustrate the value of TerpreT by developing several interpreter models and performing an extensive empirical comparison between alternative inference algorithms on a variety of program models. To our knowledge, this is the first work to compare gradient-based search over program space to traditional search-based alternatives. Our key empirical finding is that constraint solvers dominate the gradient descent and LP-based formulations. This is a workshop summary of a longer report at arXiv:1608.04428
SyGuS-Comp 2016: Results and Analysis
Nov 23, 2016

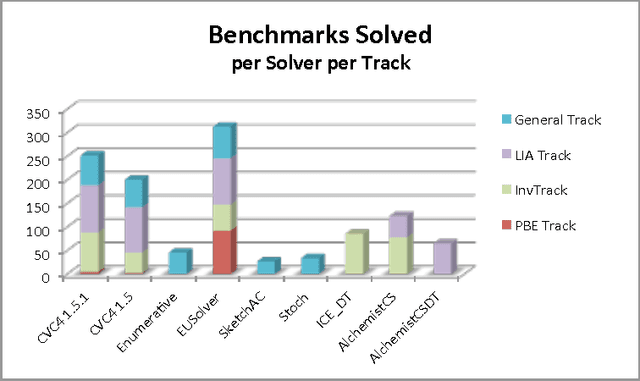
Syntax-Guided Synthesis (SyGuS) is the computational problem of finding an implementation f that meets both a semantic constraint given by a logical formula $\varphi$ in a background theory T, and a syntactic constraint given by a grammar G, which specifies the allowed set of candidate implementations. Such a synthesis problem can be formally defined in SyGuS-IF, a language that is built on top of SMT-LIB. The Syntax-Guided Synthesis Competition (SyGuS-Comp) is an effort to facilitate, bring together and accelerate research and development of efficient solvers for SyGuS by providing a platform for evaluating different synthesis techniques on a comprehensive set of benchmarks. In this year's competition we added a new track devoted to programming by examples. This track consisted of two categories, one using the theory of bit-vectors and one using the theory of strings. This paper presents and analyses the results of SyGuS-Comp'16.
* In Proceedings SYNT 2016, arXiv:1611.07178. arXiv admin note: text overlap with arXiv:1602.01170
Neuro-Symbolic Program Synthesis
Nov 06, 2016
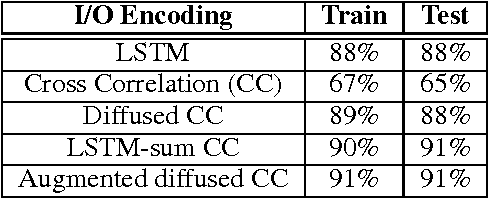
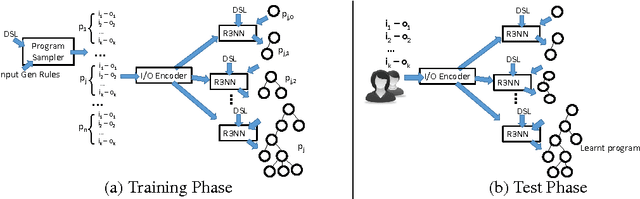
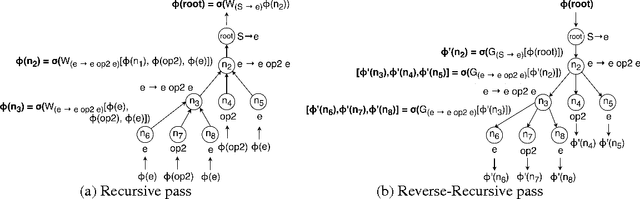
Recent years have seen the proposal of a number of neural architectures for the problem of Program Induction. Given a set of input-output examples, these architectures are able to learn mappings that generalize to new test inputs. While achieving impressive results, these approaches have a number of important limitations: (a) they are computationally expensive and hard to train, (b) a model has to be trained for each task (program) separately, and (c) it is hard to interpret or verify the correctness of the learnt mapping (as it is defined by a neural network). In this paper, we propose a novel technique, Neuro-Symbolic Program Synthesis, to overcome the above-mentioned problems. Once trained, our approach can automatically construct computer programs in a domain-specific language that are consistent with a set of input-output examples provided at test time. Our method is based on two novel neural modules. The first module, called the cross correlation I/O network, given a set of input-output examples, produces a continuous representation of the set of I/O examples. The second module, the Recursive-Reverse-Recursive Neural Network (R3NN), given the continuous representation of the examples, synthesizes a program by incrementally expanding partial programs. We demonstrate the effectiveness of our approach by applying it to the rich and complex domain of regular expression based string transformations. Experiments show that the R3NN model is not only able to construct programs from new input-output examples, but it is also able to construct new programs for tasks that it had never observed before during training.
TerpreT: A Probabilistic Programming Language for Program Induction
Aug 15, 2016We study machine learning formulations of inductive program synthesis; given input-output examples, we try to synthesize source code that maps inputs to corresponding outputs. Our aims are to develop new machine learning approaches based on neural networks and graphical models, and to understand the capabilities of machine learning techniques relative to traditional alternatives, such as those based on constraint solving from the programming languages community. Our key contribution is the proposal of TerpreT, a domain-specific language for expressing program synthesis problems. TerpreT is similar to a probabilistic programming language: a model is composed of a specification of a program representation (declarations of random variables) and an interpreter describing how programs map inputs to outputs (a model connecting unknowns to observations). The inference task is to observe a set of input-output examples and infer the underlying program. TerpreT has two main benefits. First, it enables rapid exploration of a range of domains, program representations, and interpreter models. Second, it separates the model specification from the inference algorithm, allowing like-to-like comparisons between different approaches to inference. From a single TerpreT specification we automatically perform inference using four different back-ends. These are based on gradient descent, linear program (LP) relaxations for graphical models, discrete satisfiability solving, and the Sketch program synthesis system. We illustrate the value of TerpreT by developing several interpreter models and performing an empirical comparison between alternative inference algorithms. Our key empirical finding is that constraint solvers dominate the gradient descent and LP-based formulations. We conclude with suggestions for the machine learning community to make progress on program synthesis.
Automated Correction for Syntax Errors in Programming Assignments using Recurrent Neural Networks
Mar 19, 2016
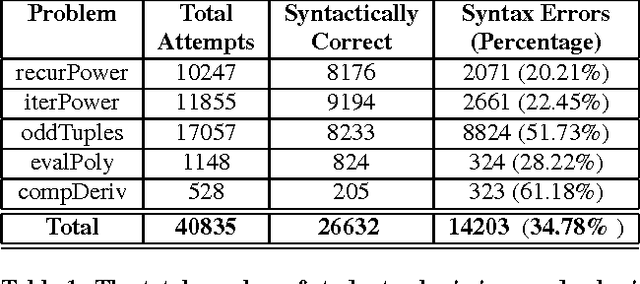
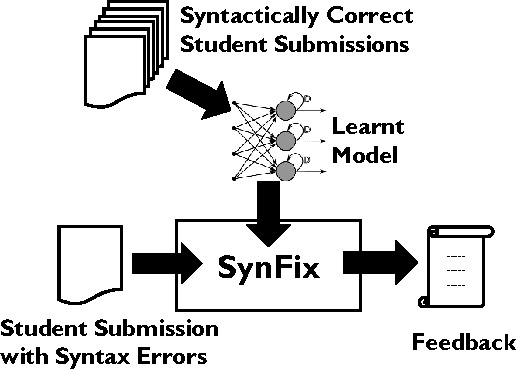
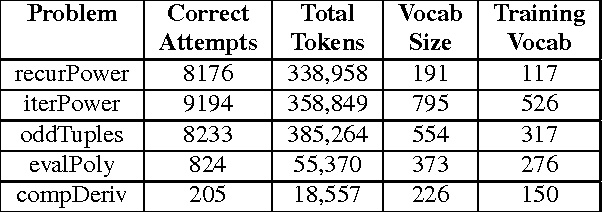
We present a method for automatically generating repair feedback for syntax errors for introductory programming problems. Syntax errors constitute one of the largest classes of errors (34%) in our dataset of student submissions obtained from a MOOC course on edX. The previous techniques for generating automated feed- back on programming assignments have focused on functional correctness and style considerations of student programs. These techniques analyze the program AST of the program and then perform some dynamic and symbolic analyses to compute repair feedback. Unfortunately, it is not possible to generate ASTs for student pro- grams with syntax errors and therefore the previous feedback techniques are not applicable in repairing syntax errors. We present a technique for providing feedback on syntax errors that uses Recurrent neural networks (RNNs) to model syntactically valid token sequences. Our approach is inspired from the recent work on learning language models from Big Code (large code corpus). For a given programming assignment, we first learn an RNN to model all valid token sequences using the set of syntactically correct student submissions. Then, for a student submission with syntax errors, we query the learnt RNN model with the prefix to- ken sequence to predict token sequences that can fix the error by either replacing or inserting the predicted token sequence at the error location. We evaluate our technique on over 14, 000 student submissions with syntax errors. Our technique can completely re- pair 31.69% (4501/14203) of submissions with syntax errors and in addition partially correct 6.39% (908/14203) of the submissions.
Automated Feedback Generation for Introductory Programming Assignments
Nov 16, 2012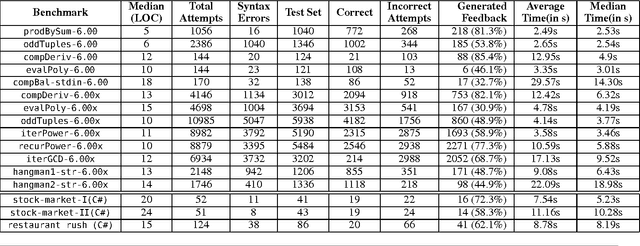

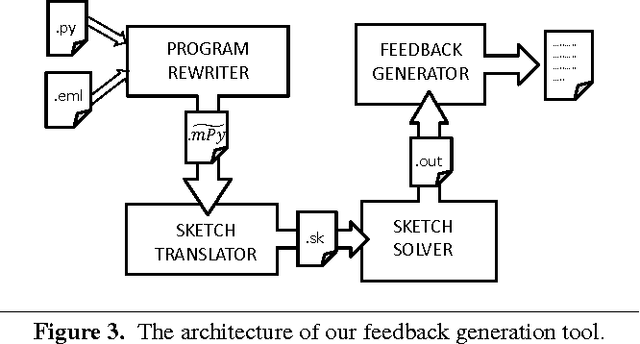

We present a new method for automatically providing feedback for introductory programming problems. In order to use this method, we need a reference implementation of the assignment, and an error model consisting of potential corrections to errors that students might make. Using this information, the system automatically derives minimal corrections to student's incorrect solutions, providing them with a quantifiable measure of exactly how incorrect a given solution was, as well as feedback about what they did wrong. We introduce a simple language for describing error models in terms of correction rules, and formally define a rule-directed translation strategy that reduces the problem of finding minimal corrections in an incorrect program to the problem of synthesizing a correct program from a sketch. We have evaluated our system on thousands of real student attempts obtained from 6.00 and 6.00x. Our results show that relatively simple error models can correct on average 65% of all incorrect submissions.