 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling User Behavior from Adaptive Surveys with Supplemental Context
Jul 28, 2025



Modeling user behavior is critical across many industries where understanding preferences, intent, or decisions informs personalization, targeting, and strategic outcomes. Surveys have long served as a classical mechanism for collecting such behavioral data due to their interpretability, structure, and ease of deployment. However, surveys alone are inherently limited by user fatigue, incomplete responses, and practical constraints on their length making them insufficient for capturing user behavior. In this work, we present LANTERN (Late-Attentive Network for Enriched Response Modeling), a modular architecture for modeling user behavior by fusing adaptive survey responses with supplemental contextual signals. We demonstrate the architectural value of maintaining survey primacy through selective gating, residual connections and late fusion via cross-attention, treating survey data as the primary signal while incorporating external modalities only when relevant. LANTERN outperforms strong survey-only baselines in multi-label prediction of survey responses. We further investigate threshold sensitivity and the benefits of selective modality reliance through ablation and rare/frequent attribute analysis. LANTERN's modularity supports scalable integration of new encoders and evolving datasets. This work provides a practical and extensible blueprint for behavior modeling in survey-centric applications.
Automatic Speech Recognition in Sanskrit: A New Speech Corpus and Modelling Insights
Jun 02, 2021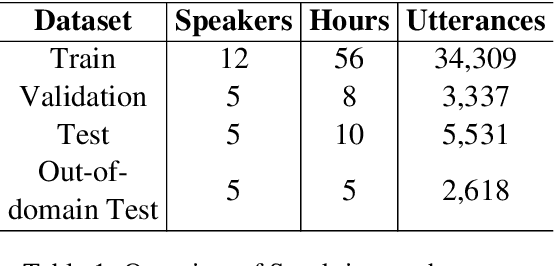
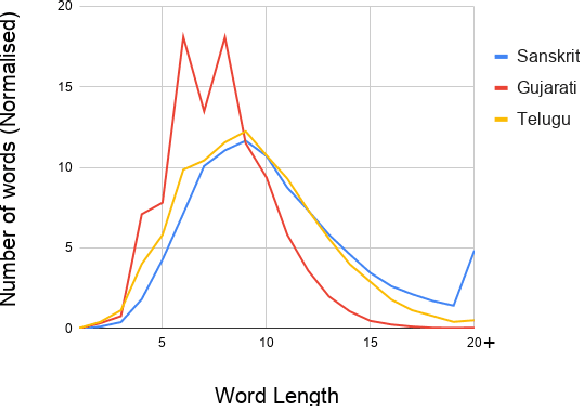
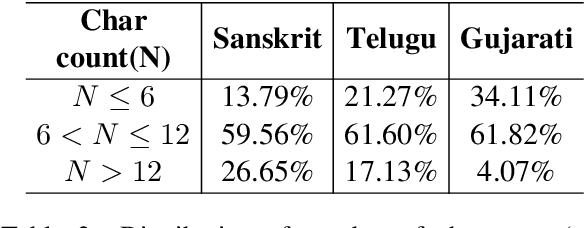

Automatic speech recognition (ASR) in Sanskrit is interesting, owing to the various linguistic peculiarities present in the language. The Sanskrit language is lexically productive, undergoes euphonic assimilation of phones at the word boundaries and exhibits variations in spelling conventions and in pronunciations. In this work, we propose the first large scale study of automatic speech recognition (ASR) in Sanskrit, with an emphasis on the impact of unit selection in Sanskrit ASR. In this work, we release a 78 hour ASR dataset for Sanskrit, which faithfully captures several of the linguistic characteristics expressed by the language. We investigate the role of different acoustic model and language model units in ASR systems for Sanskrit. We also propose a new modelling unit, inspired by the syllable level unit selection, that captures character sequences from one vowel in the word to the next vowel. We also highlight the importance of choosing graphemic representations for Sanskrit and show the impact of this choice on word error rates (WER). Finally, we extend these insights from Sanskrit ASR for building ASR systems in two other Indic languages, Gujarati and Telugu. For both these languages, our experimental results show that the use of phonetic based graphemic representations in ASR results in performance improvements as compared to ASR systems that use native scripts.