 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAnoGAN: Time Series Anomaly Detection with Generative Adversarial Networks
Sep 25, 2020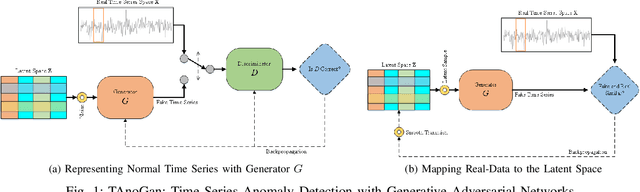
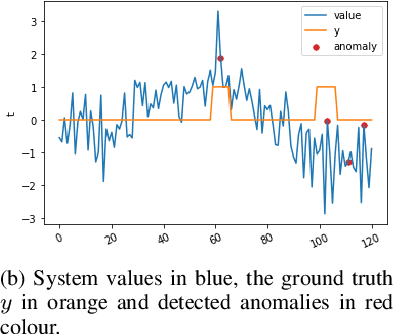
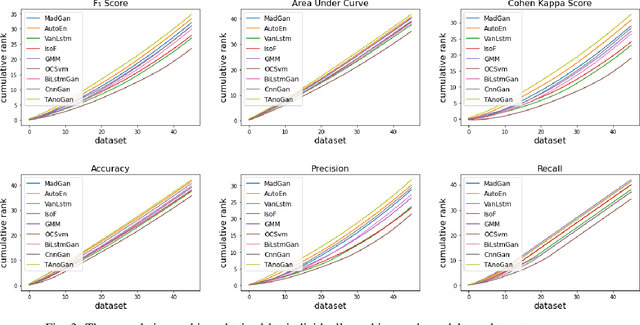
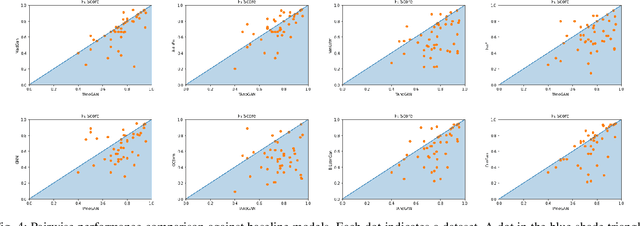
Anomaly detection in time series data is a significant problem faced in many application areas such as manufacturing, medical imaging and cyber-security. Recently, Generative Adversarial Networks (GAN) have gained attention for generation and anomaly detection in image domain. In this paper, we propose a novel GAN-based unsupervised method called TAnoGan for detecting anomalies in time series when a small number of data points are available. We evaluate TAnoGan with 46 real-world time series datasets that cover a variety of domains. Extensive experimental results show that TAnoGan performs better than traditional and neural network models.
Understanding the Spatio-temporal Topic Dynamics of Covid-19 using Nonnegative Tensor Factorization: A Case Study
Sep 19, 2020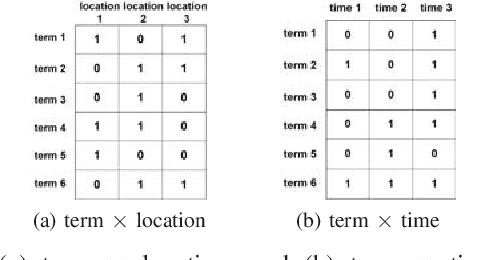
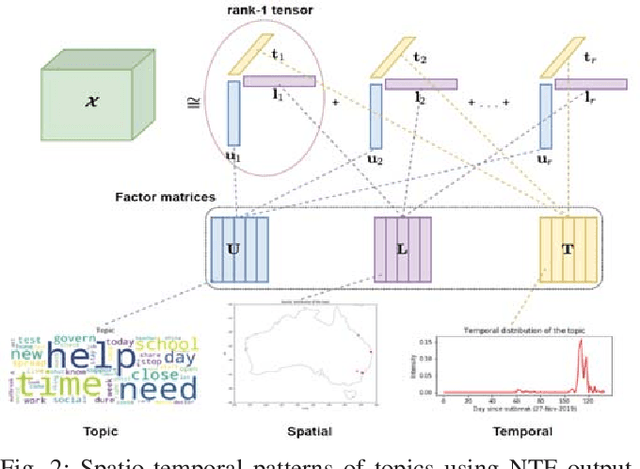
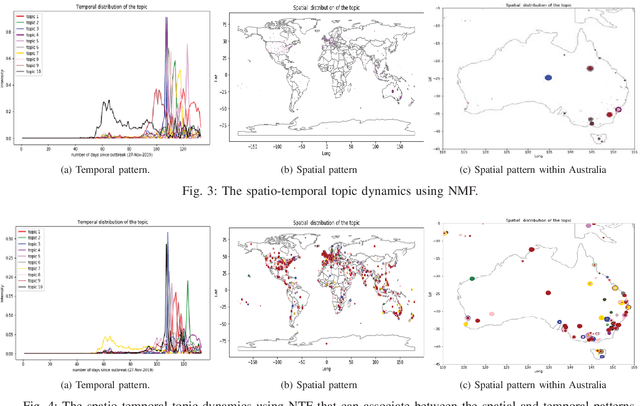
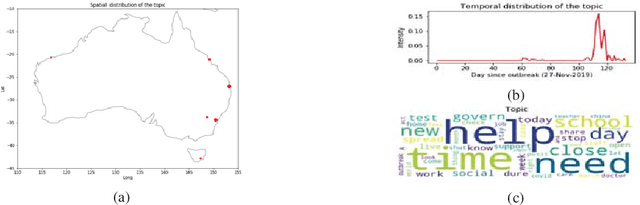
Social media platforms facilitate mankind a data-driven world by enabling billions of people to share their thoughts and activities ubiquitously. This huge collection of data, if analysed properly, can provide useful insights into people's behavior. More than ever, now is a crucial time under the Covid-19 pandemic to understand people's online behaviors detailing what topics are being discussed, and where (space) and when (time) they are discussed. Given the high complexity and poor quality of the huge social media data, an effective spatio-temporal topic detection method is needed. This paper proposes a tensor-based representation of social media data and Non-negative Tensor Factorization (NTF) to identify the topics discussed in social media data along with the spatio-temporal topic dynamics. A case study on Covid-19 related tweets from the Australia Twittersphere is presented to identify and visualize spatio-temporal topic dynamics on Covid-19
Learning Inter- and Intra-manifolds for Matrix Factorization-based Multi-Aspect Data Clustering
Sep 07, 2020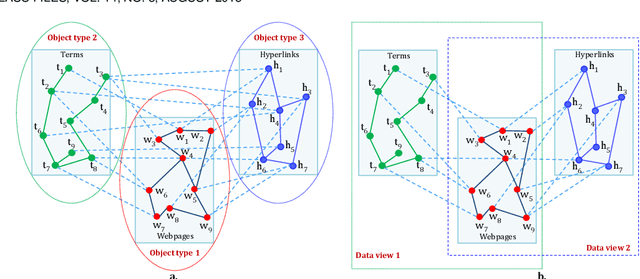
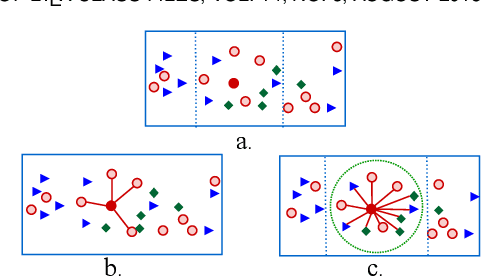
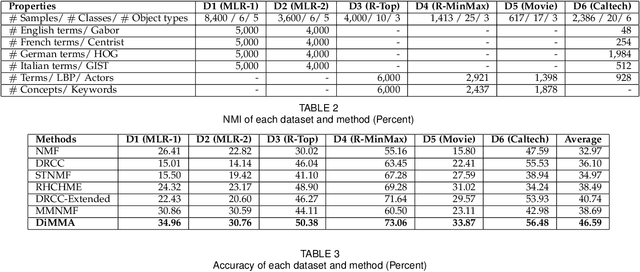
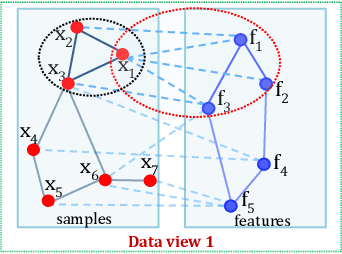
Clustering on the data with multiple aspects, such as multi-view or multi-type relational data, has become popular in recent years due to their wide applicability. The approach using manifold learning with the Non-negative Matrix Factorization (NMF) framework, that learns the accurate low-rank representation of the multi-dimensional data, has shown effectiveness. We propose to include the inter-manifold in the NMF framework, utilizing the distance information of data points of different data types (or views) to learn the diverse manifold for data clustering. Empirical analysis reveals that the proposed method can find partial representations of various interrelated types and select useful features during clustering. Results on several datasets demonstrate that the proposed method outperforms the state-of-the-art multi-aspect data clustering methods in both accuracy and efficiency.
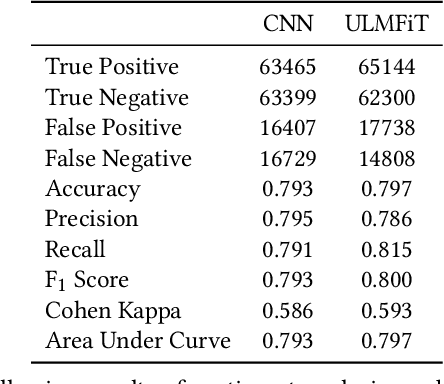
Misogynistic Tweet Detection: Modelling CNN with Small Datasets
Aug 28, 2020
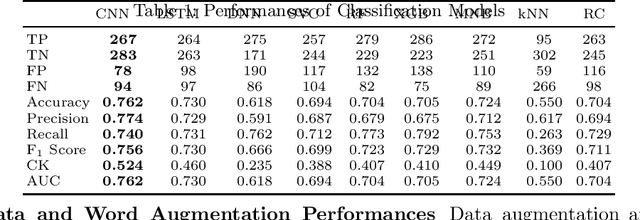
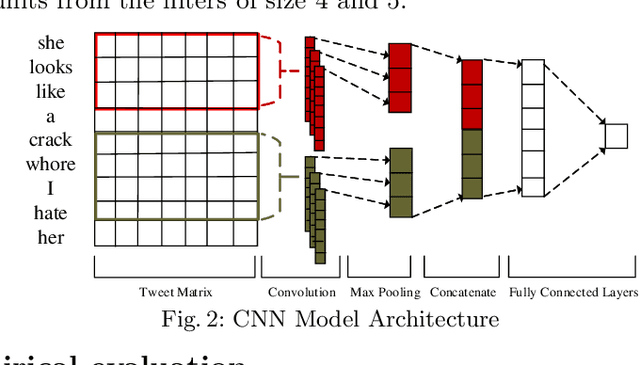
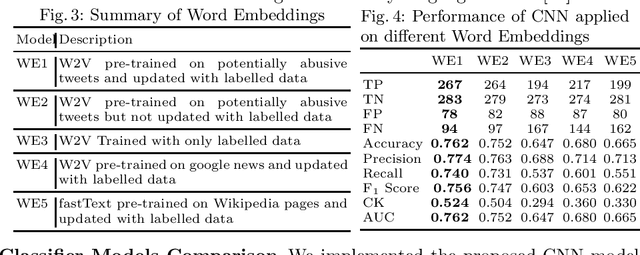
Online abuse directed towards women on the social media platform Twitter has attracted considerable attention in recent years. An automated method to effectively identify misogynistic abuse could improve our understanding of the patterns, driving factors, and effectiveness of responses associated with abusive tweets over a sustained time period. However, training a neural network (NN) model with a small set of labelled data to detect misogynistic tweets is difficult. This is partly due to the complex nature of tweets which contain misogynistic content, and the vast number of parameters needed to be learned in a NN model. We have conducted a series of experiments to investigate how to train a NN model to detect misogynistic tweets effectively. In particular, we have customised and regularised a Convolutional Neural Network (CNN) architecture and shown that the word vectors pre-trained on a task-specific domain can be used to train a CNN model effectively when a small set of labelled data is available. A CNN model trained in this way yields an improved accuracy over the state-of-the-art models.
QutNocturnal@HASOC'19: CNN for Hate Speech and Offensive Content Identification in Hindi Language
Aug 28, 2020
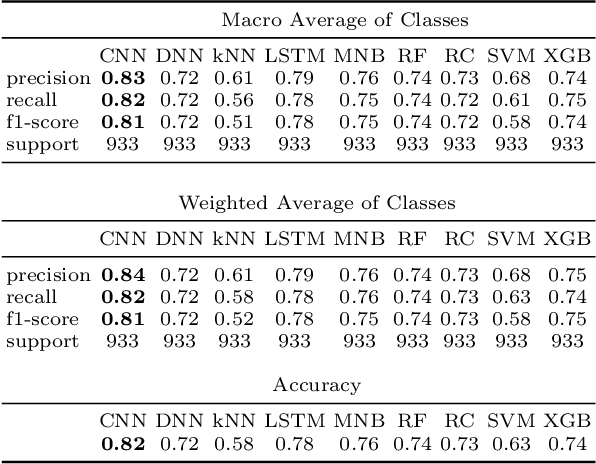
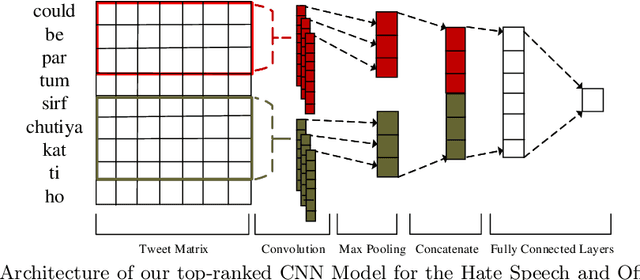
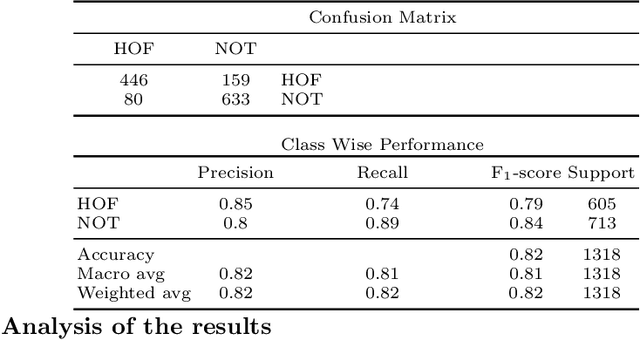
We describe our top-team solution to Task 1 for Hindi in the HASOC contest organised by FIRE 2019. The task is to identify hate speech and offensive language in Hindi. More specifically, it is a binary classification problem where a system is required to classify tweets into two classes: (a) \emph{Hate and Offensive (HOF)} and (b) \emph{Not Hate or Offensive (NOT)}. In contrast to the popular idea of pretraining word vectors (a.k.a. word embedding) with a large corpus from a general domain such as Wikipedia, we used a relatively small collection of relevant tweets (i.e. random and sarcasm tweets in Hindi and Hinglish) for pretraining. We trained a Convolutional Neural Network (CNN) on top of the pretrained word vectors. This approach allowed us to be ranked first for this task out of all teams. Our approach could easily be adapted to other applications where the goal is to predict class of a text when the provided context is limited.
Topic, Sentiment and Impact Analysis: COVID19 Information Seeking on Social Media
Aug 28, 2020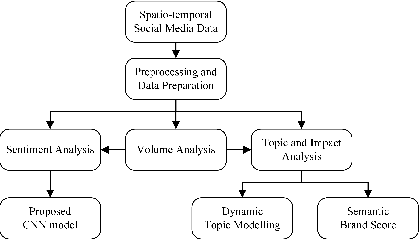
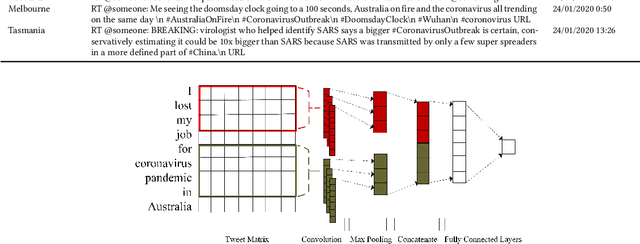

When people notice something unusual, they discuss it on social media. They leave traces of their emotions via text expressions. A systematic collection, analysis, and interpretation of social media data across time and space can give insights on local outbreaks, mental health, and social issues. Such timely insights can help in developing strategies and resources with an appropriate and efficient response. This study analysed a large Spatio-temporal tweet dataset of the Australian sphere related to COVID19. The methodology included a volume analysis, dynamic topic modelling, sentiment detection, and semantic brand score to obtain an insight on the COVID19 pandemic outbreak and public discussion in different states and cities of Australia over time. The obtained insights are compared with independently observed phenomena such as government reported instances.
Propensity-to-Pay: Machine Learning for Estimating Prediction Uncertainty
Aug 27, 2020
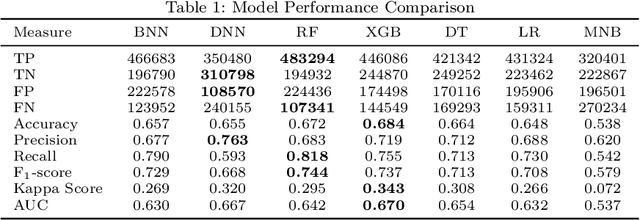
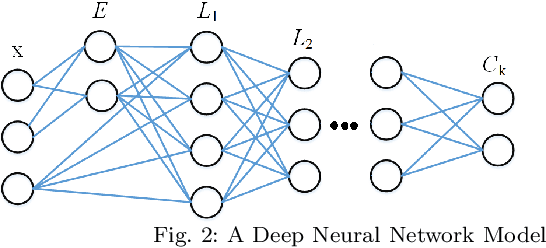
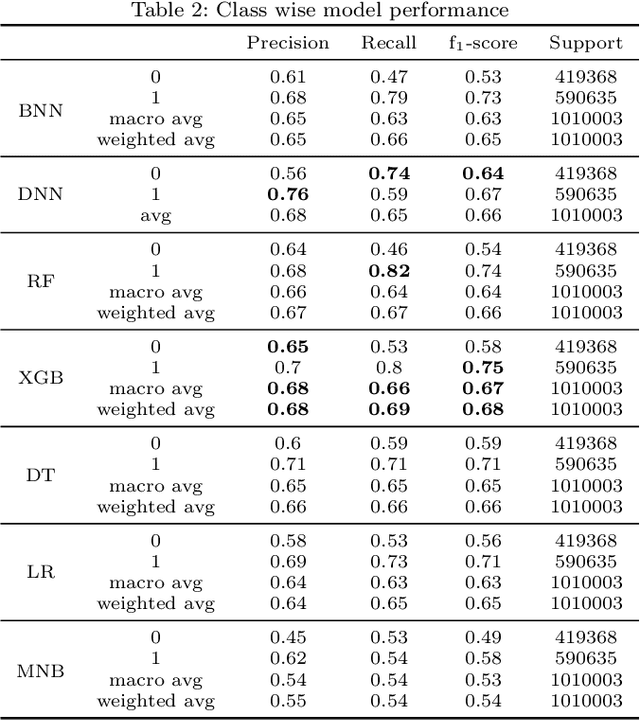
Predicting a customer's propensity-to-pay at an early point in the revenue cycle can provide organisations many opportunities to improve the customer experience, reduce hardship and reduce the risk of impaired cash flow and occurrence of bad debt. With the advancements in data science; machine learning techniques can be used to build models to accurately predict a customer's propensity-to-pay. Creating effective machine learning models without access to large and detailed datasets presents some significant challenges. This paper presents a case-study, conducted on a dataset from an energy organisation, to explore the uncertainty around the creation of machine learning models that are able to predict residential customers entering financial hardship which then reduces their ability to pay energy bills. Incorrect predictions can result in inefficient resource allocation and vulnerable customers not being proactively identified. This study investigates machine learning models' ability to consider different contexts and estimate the uncertainty in the prediction. Seven models from four families of machine learning algorithms are investigated for their novel utilisation. A novel concept of utilising a Baysian Neural Network to the binary classification problem of propensity-to-pay energy bills is proposed and explored for deployment.
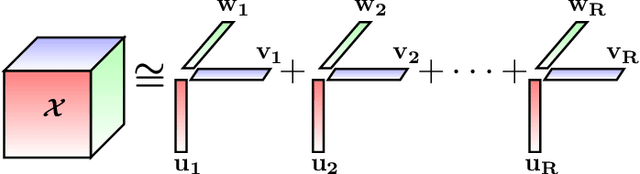
Efficient Nonnegative Tensor Factorization via Saturating Coordinate Descent
Mar 07, 2020
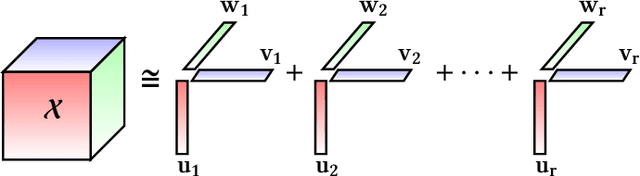

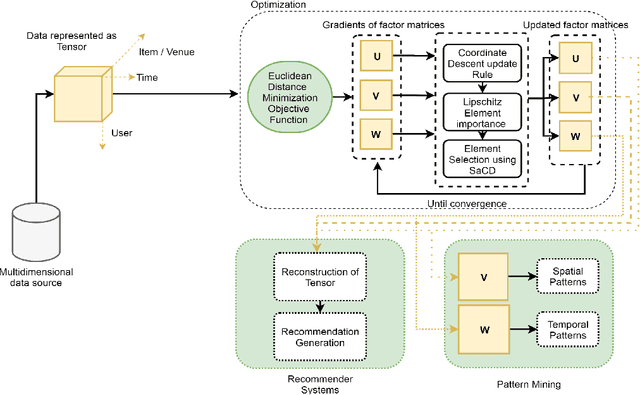
With the advancements in computing technology and web-based applications, data is increasingly generated in multi-dimensional form. This data is usually sparse due to the presence of a large number of users and fewer user interactions. To deal with this, the Nonnegative Tensor Factorization (NTF) based methods have been widely used. However existing factorization algorithms are not suitable to process in all three conditions of size, density, and rank of the tensor. Consequently, their applicability becomes limited. In this paper, we propose a novel fast and efficient NTF algorithm using the element selection approach. We calculate the element importance using Lipschitz continuity and propose a saturation point based element selection method that chooses a set of elements column-wise for updating to solve the optimization problem. Empirical analysis reveals that the proposed algorithm is scalable in terms of tensor size, density, and rank in comparison to the relevant state-of-the-art algorithms.
Columnwise Element Selection for Computationally Efficient Nonnegative Coupled Matrix Tensor Factorization
Mar 07, 2020
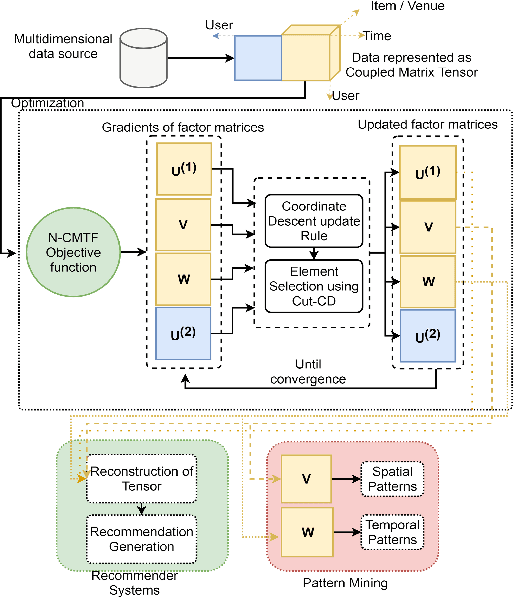
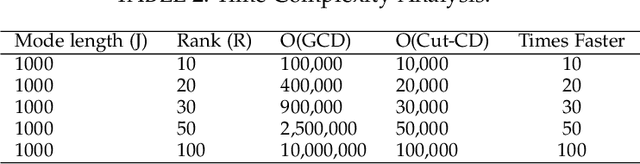
Coupled Matrix Tensor Factorization (CMTF) facilitates the integration and analysis of multiple data sources and helps discover meaningful information. Nonnegative CMTF (N-CMTF) has been employed in many applications for identifying latent patterns, prediction, and recommendation. However, due to the added complexity with coupling between tensor and matrix data, existing N-CMTF algorithms exhibit poor computation efficiency. In this paper, a computationally efficient N-CMTF factorization algorithm is presented based on the column-wise element selection, preventing frequent gradient updates. Theoretical and empirical analyses show that the proposed N-CMTF factorization algorithm is not only more accurate but also more computationally efficient than existing algorithms in approximating the tensor as well as in identifying the underlying nature of factors.
Parallel Streaming Signature EM-tree: A Clustering Algorithm for Web Scale Applications
May 21, 2015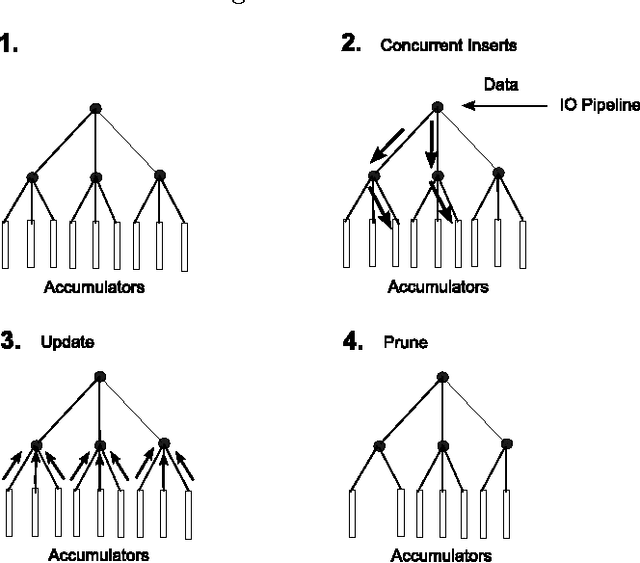
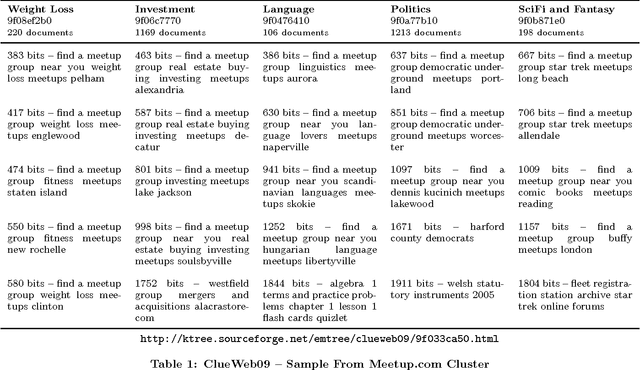

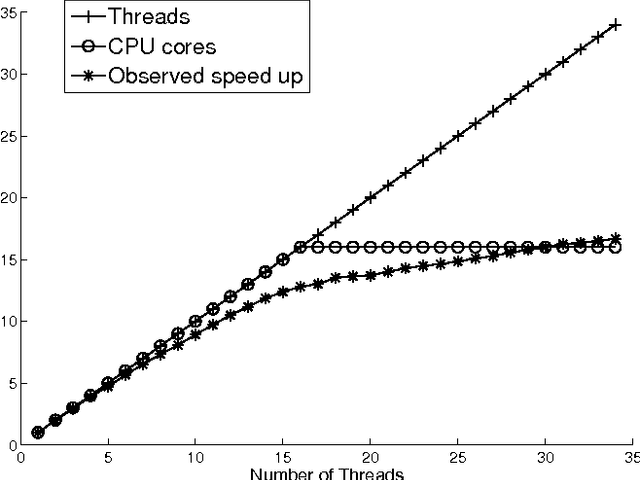
The proliferation of the web presents an unsolved problem of automatically analyzing billions of pages of natural language. We introduce a scalable algorithm that clusters hundreds of millions of web pages into hundreds of thousands of clusters. It does this on a single mid-range machine using efficient algorithms and compressed document representations. It is applied to two web-scale crawls covering tens of terabytes. ClueWeb09 and ClueWeb12 contain 500 and 733 million web pages and were clustered into 500,000 to 700,000 clusters. To the best of our knowledge, such fine grained clustering has not been previously demonstrated. Previous approaches clustered a sample that limits the maximum number of discoverable clusters. The proposed EM-tree algorithm uses the entire collection in clustering and produces several orders of magnitude more clusters than the existing algorithms. Fine grained clustering is necessary for meaningful clustering in massive collections where the number of distinct topics grows linearly with collection size. These fine-grained clusters show an improved cluster quality when assessed with two novel evaluations using ad hoc search relevance judgments and spam classifications for external validation. These evaluations solve the problem of assessing the quality of clusters where categorical labeling is unavailable and unfeasible.