 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketchEmbedNet: Learning Novel Concepts by Imitating Drawings
Aug 27, 2020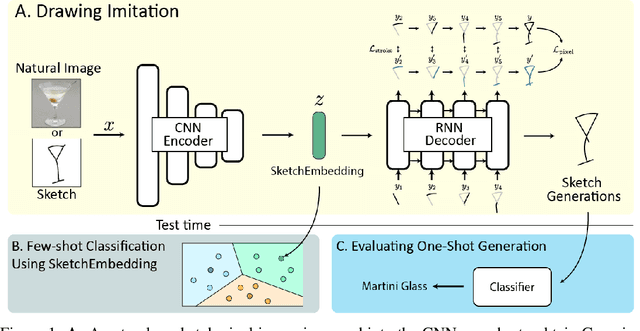
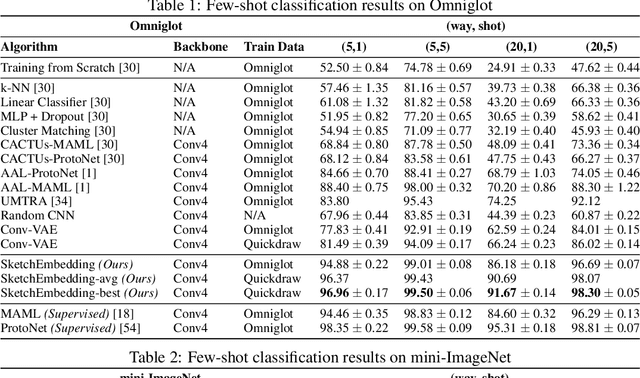

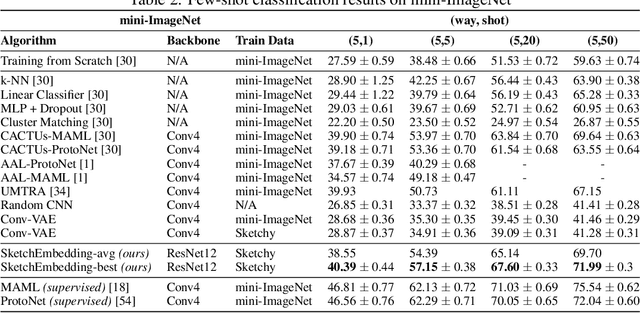
Sketch drawings are an intuitive visual domain that generally preserves semantics. Previous work has shown that recurrent neural networks are capable of producing sketch drawings of a single or few classes at a time. In this work we focus on the representations developed by training a generative model to produce sketches from pixel images across many classes in a sketch domain. We find that the embeddings learned by this sketching model are extremely informative for visual tasks and infer compositional information. We then use them to exceed state-of-the-art performance in unsupervised few-shot classification on the Omniglot and mini-ImageNet benchmarks. We also leverage the generative capacity of our model to produce high quality sketches of novel classes based on just a single example.
Optimizing Long-term Social Welfare in Recommender Systems: A Constrained Matching Approach
Aug 18, 2020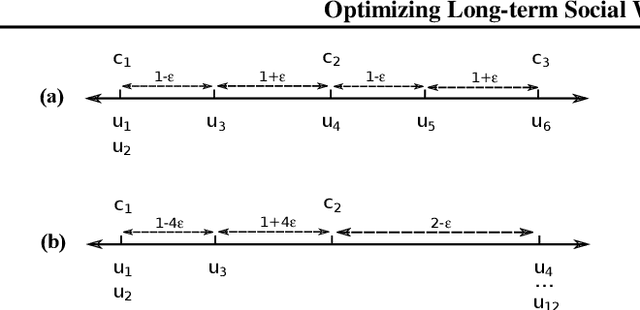
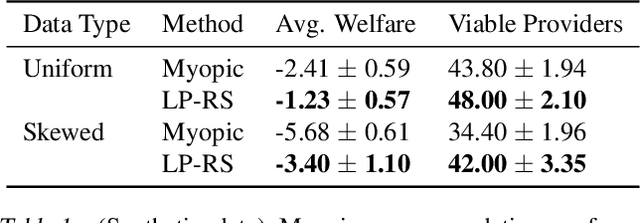
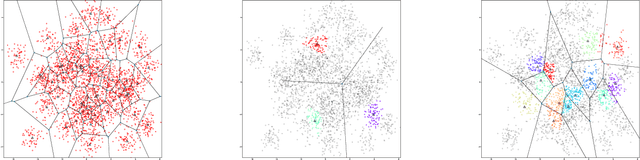
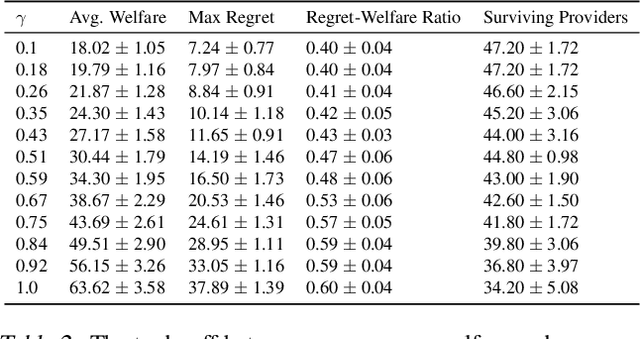
Most recommender systems (RS) research assumes that a user's utility can be maximized independently of the utility of the other agents (e.g., other users, content providers). In realistic settings, this is often not true---the dynamics of an RS ecosystem couple the long-term utility of all agents. In this work, we explore settings in which content providers cannot remain viable unless they receive a certain level of user engagement. We formulate the recommendation problem in this setting as one of equilibrium selection in the induced dynamical system, and show that it can be solved as an optimal constrained matching problem. Our model ensures the system reaches an equilibrium with maximal social welfare supported by a sufficiently diverse set of viable providers. We demonstrate that even in a simple, stylized dynamical RS model, the standard myopic approach to recommendation---always matching a user to the best provider---performs poorly. We develop several scalable techniques to solve the matching problem, and also draw connections to various notions of user regret and fairness, arguing that these outcomes are fairer in a utilitarian sense.
Bayesian Few-Shot Classification with One-vs-Each Pólya-Gamma Augmented Gaussian Processes
Jul 20, 2020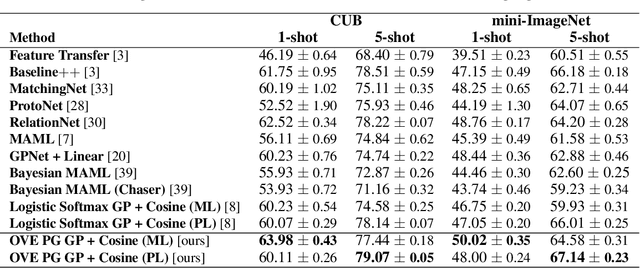
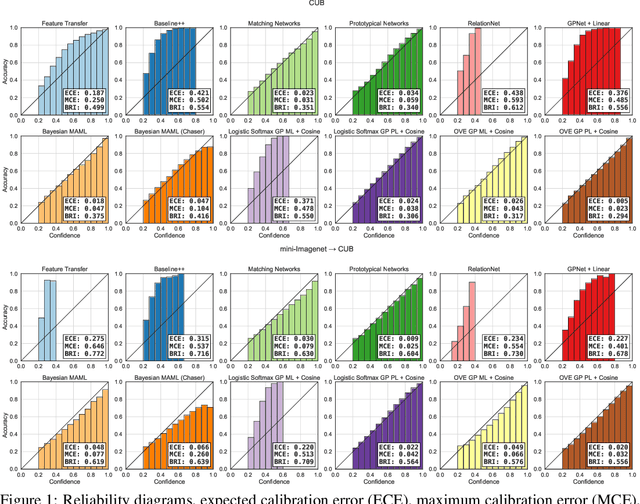
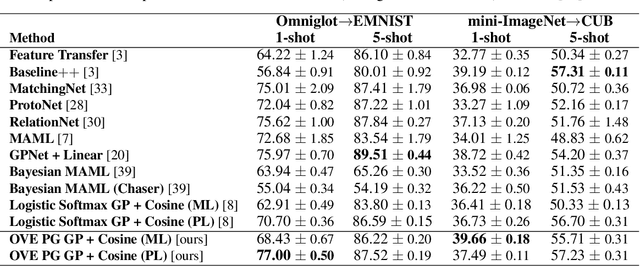
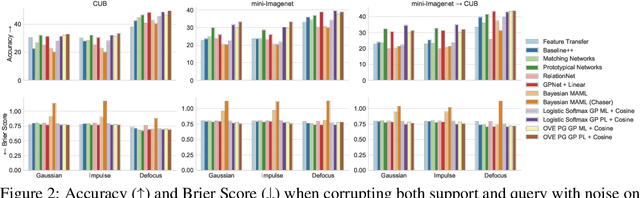
Few-shot classification (FSC), the task of adapting a classifier to unseen classes given a small labeled dataset, is an important step on the path toward human-like machine learning. Bayesian methods are well-suited to tackling the fundamental issue of overfitting in the few-shot scenario because they allow practitioners to specify prior beliefs and update those beliefs in light of observed data. Contemporary approaches to Bayesian few-shot classification maintain a posterior distribution over model parameters, which is slow and requires storage that scales with model size. Instead, we propose a Gaussian process classifier based on a novel combination of P\'olya-gamma augmentation and the one-vs-each softmax approximation that allows us to efficiently marginalize over functions rather than model parameters. We demonstrate improved accuracy and uncertainty quantification on both standard few-shot classification benchmarks and few-shot domain transfer tasks.
Amortized Causal Discovery: Learning to Infer Causal Graphs from Time-Series Data
Jun 18, 2020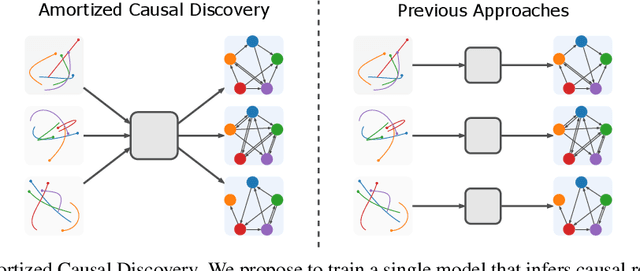
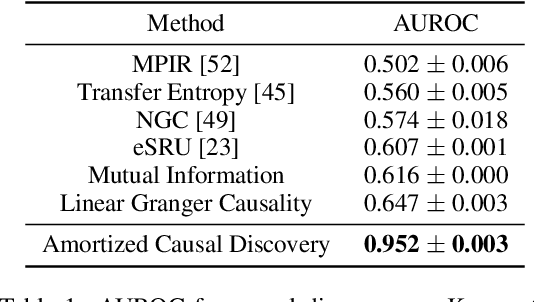
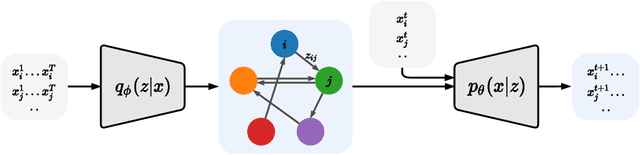
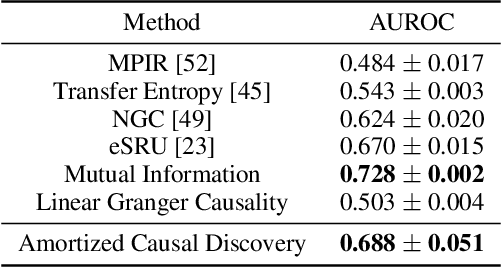
Standard causal discovery methods must fit a new model whenever they encounter samples from a new underlying causal graph. However, these samples often share relevant information - for instance, the dynamics describing the effects of causal relations - which is lost when following this approach. We propose Amortized Causal Discovery, a novel framework that leverages such shared dynamics to learn to infer causal relations from time-series data. This enables us to train a single, amortized model that infers causal relations across samples with different underlying causal graphs, and thus makes use of the information that is shared. We demonstrate experimentally that this approach, implemented as a variational model, leads to significant improvements in causal discovery performance, and show how it can be extended to perform well under hidden confounding.
Shortcut Learning in Deep Neural Networks
May 20, 2020
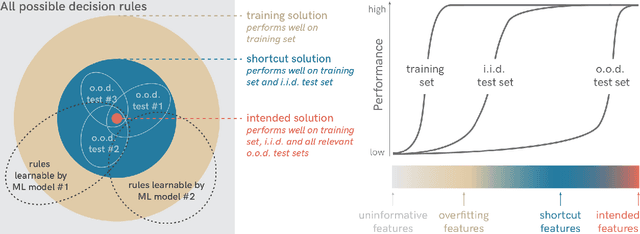

Deep learning has triggered the current rise of artificial intelligence and is the workhorse of today's machine intelligence. Numerous success stories have rapidly spread all over science, industry and society, but its limitations have only recently come into focus. In this perspective we seek to distil how many of deep learning's problem can be seen as different symptoms of the same underlying problem: shortcut learning. Shortcuts are decision rules that perform well on standard benchmarks but fail to transfer to more challenging testing conditions, such as real-world scenarios. Related issues are known in Comparative Psychology, Education and Linguistics, suggesting that shortcut learning may be a common characteristic of learning systems, biological and artificial alike. Based on these observations, we develop a set of recommendations for model interpretation and benchmarking, highlighting recent advances in machine learning to improve robustness and transferability from the lab to real-world applications.
Cutting out the Middle-Man: Training and Evaluating Energy-Based Models without Sampling
Feb 14, 2020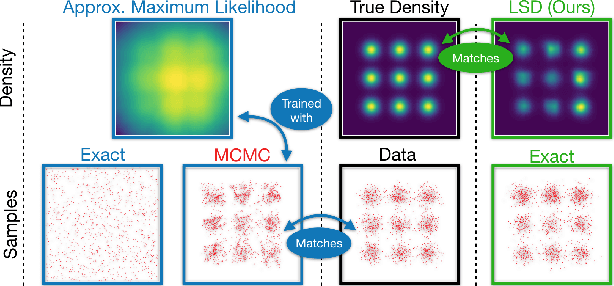
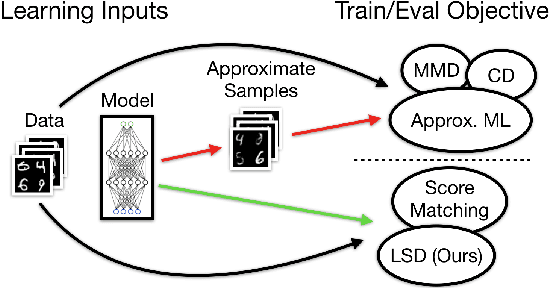
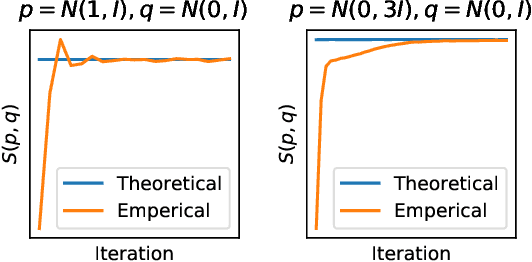
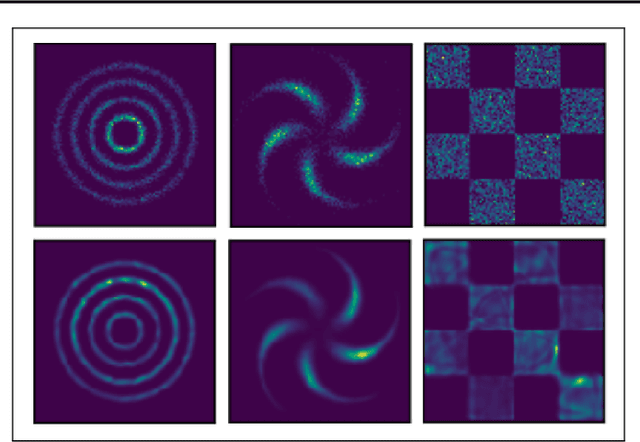
We present a new method for evaluating and training unnormalized density models. Our approach only requires access to the gradient of the unnormalized model's log-density. We estimate the Stein discrepancy between the data density p(x) and the model density q(x) defined by a vector function of the data. We parameterize this function with a neural network and fit its parameters to maximize the discrepancy. This yields a novel goodness-of-fit test which outperforms existing methods on high dimensional data. Furthermore, optimizing $q(x)$ to minimize this discrepancy produces a novel method for training unnormalized models which scales more gracefully than existing methods. The ability to both learn and compare models is a unique feature of the proposed method.
A Divergence Minimization Perspective on Imitation Learning Methods
Nov 06, 2019
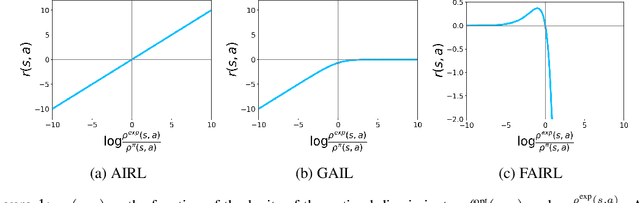
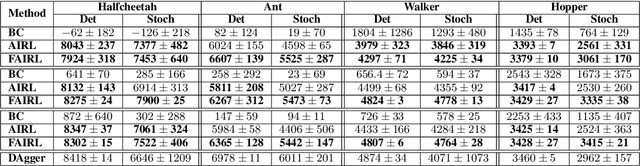
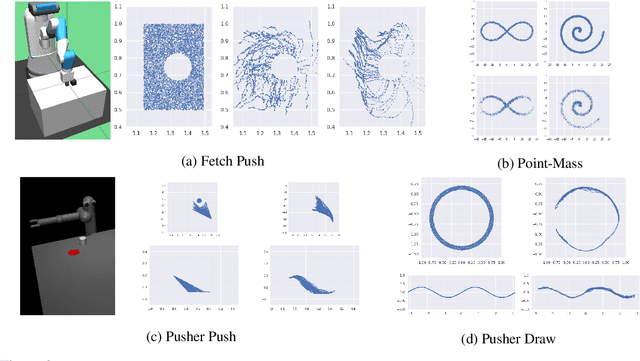
In many settings, it is desirable to learn decision-making and control policies through learning or bootstrapping from expert demonstrations. The most common approaches under this Imitation Learning (IL) framework are Behavioural Cloning (BC), and Inverse Reinforcement Learning (IRL). Recent methods for IRL have demonstrated the capacity to learn effective policies with access to a very limited set of demonstrations, a scenario in which BC methods often fail. Unfortunately, due to multiple factors of variation, directly comparing these methods does not provide adequate intuition for understanding this difference in performance. In this work, we present a unified probabilistic perspective on IL algorithms based on divergence minimization. We present $f$-MAX, an $f$-divergence generalization of AIRL [Fu et al., 2018], a state-of-the-art IRL method. $f$-MAX enables us to relate prior IRL methods such as GAIL [Ho & Ermon, 2016] and AIRL [Fu et al., 2018], and understand their algorithmic properties. Through the lens of divergence minimization we tease apart the differences between BC and successful IRL approaches, and empirically evaluate these nuances on simulated high-dimensional continuous control domains. Our findings conclusively identify that IRL's state-marginal matching objective contributes most to its superior performance. Lastly, we apply our new understanding of IL methods to the problem of state-marginal matching, where we demonstrate that in simulated arm pushing environments we can teach agents a diverse range of behaviours using simply hand-specified state distributions and no reward functions or expert demonstrations. For datasets and reproducing results please refer to https://github.com/KamyarGh/rl_swiss/blob/master/reproducing/fmax_paper.md .
Causal Modeling for Fairness in Dynamical Systems
Sep 18, 2019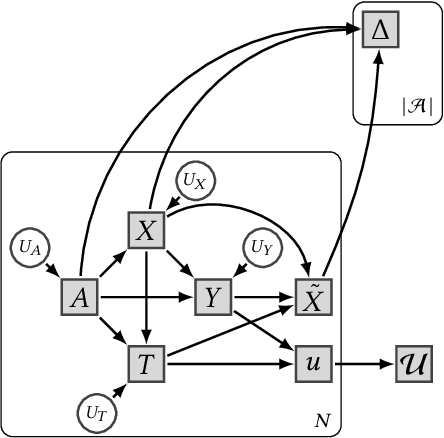
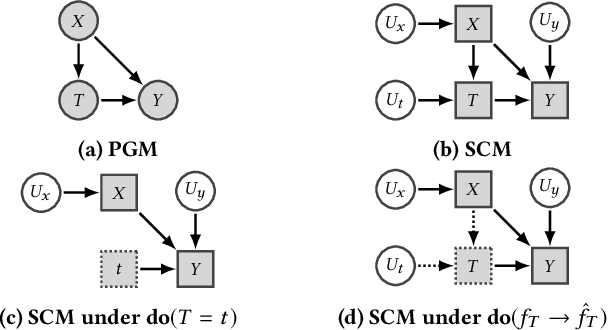
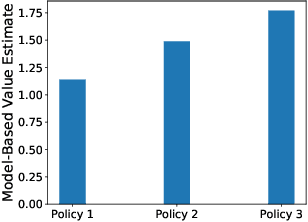
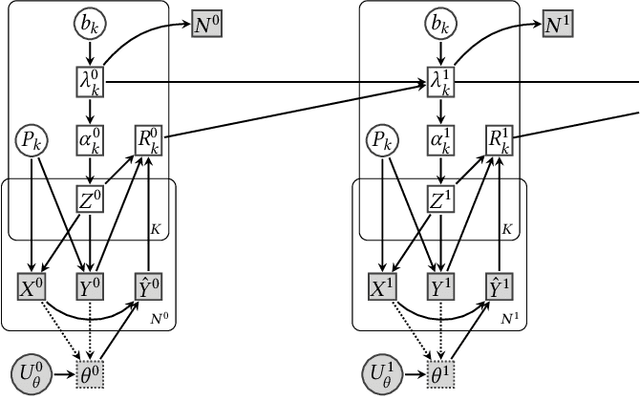
In this work, we present causal directed acyclic graphs (DAGs) as a unifying framework for the recent literature on fairness in dynamical systems. We advocate for the use of causal DAGs as a tool in both designing equitable policies and estimating their impacts. By visualizing models of dynamic unfairness graphically, we expose implicit causal assumptions which can then be more easily interpreted and scrutinized by domain experts. We demonstrate that this method of reinterpretation can be used to critique the robustness of an existing model/policy, or uncover new policy evaluation questions. Causal models also enable a rich set of options for evaluating a new candidate policy without incurring the risk of implementing the policy in the real world. We close the paper with causal analyses of several models from the recent literature, and provide an in-depth case study to demonstrate the utility of causal DAGs for modeling fairness in dynamical systems.
Alchemy: A Quantum Chemistry Dataset for Benchmarking AI Models
Jun 22, 2019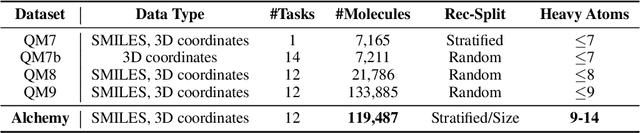
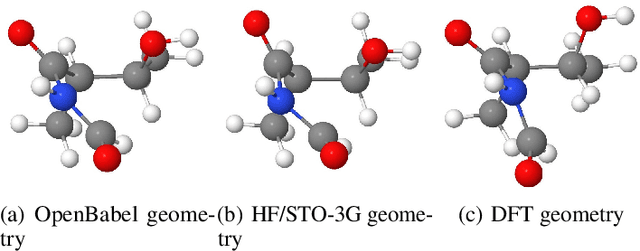
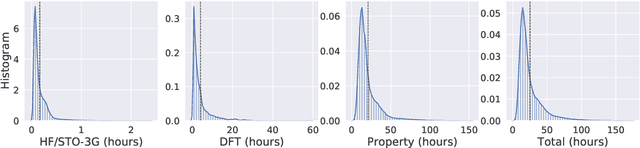
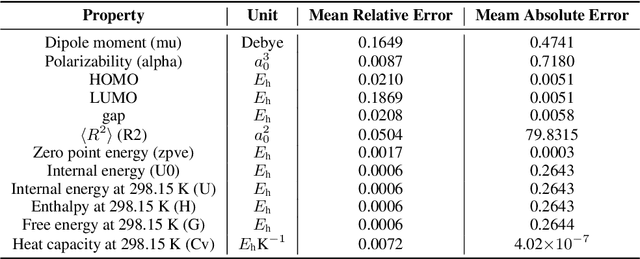
We introduce a new molecular dataset, named Alchemy, for developing machine learning models useful in chemistry and material science. As of June 20th 2019, the dataset comprises of 12 quantum mechanical properties of 119,487 organic molecules with up to 14 heavy atoms, sampled from the GDB MedChem database. The Alchemy dataset expands the volume and diversity of existing molecular datasets. Our extensive benchmarks of the state-of-the-art graph neural network models on Alchemy clearly manifest the usefulness of new data in validating and developing machine learning models for chemistry and material science. We further launch a contest to attract attentions from researchers in the related fields. More details can be found on the contest website \footnote{https://alchemy.tencent.com}. At the time of benchamrking experiment, we have generated 119,487 molecules in our Alchemy dataset. More molecular samples are generated since then. Hence, we provide a list of molecules used in the reported benchmarks.
Flexibly Fair Representation Learning by Disentanglement
Jun 06, 2019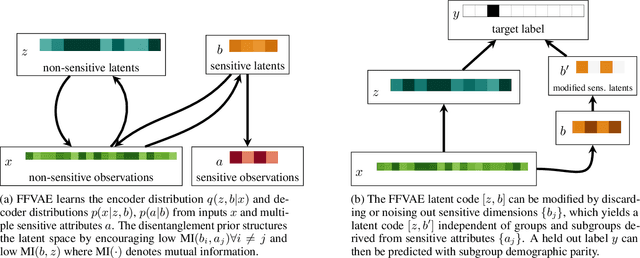
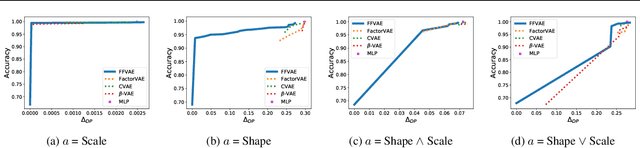
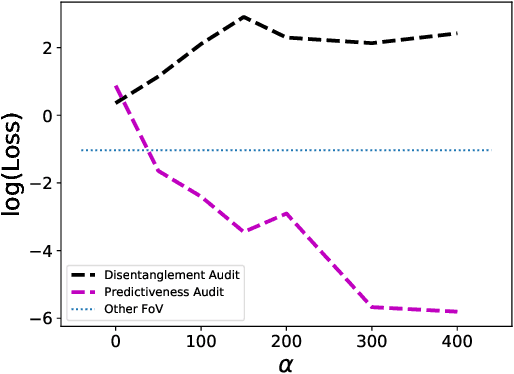
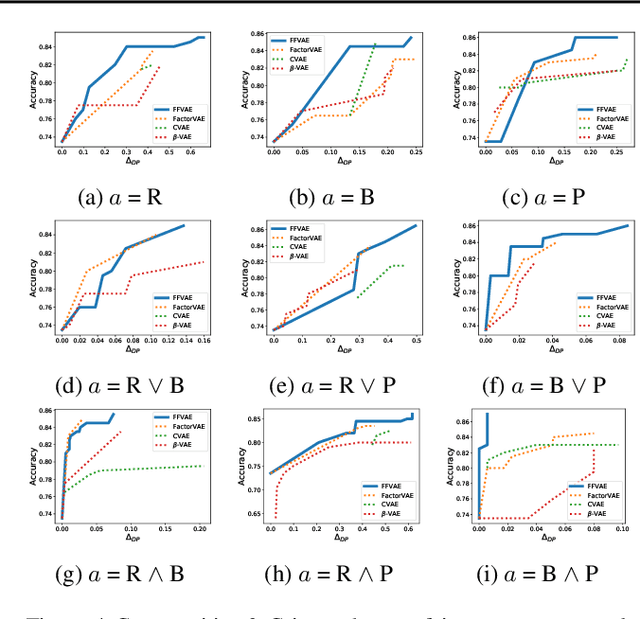
We consider the problem of learning representations that achieve group and subgroup fairness with respect to multiple sensitive attributes. Taking inspiration from the disentangled representation learning literature, we propose an algorithm for learning compact representations of datasets that are useful for reconstruction and prediction, but are also \emph{flexibly fair}, meaning they can be easily modified at test time to achieve subgroup demographic parity with respect to multiple sensitive attributes and their conjunctions. We show empirically that the resulting encoder---which does not require the sensitive attributes for inference---enables the adaptation of a single representation to a variety of fair classification tasks with new target labels and subgroup definitions.