 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Datasets for Neural Program Synthesis
Dec 27, 2019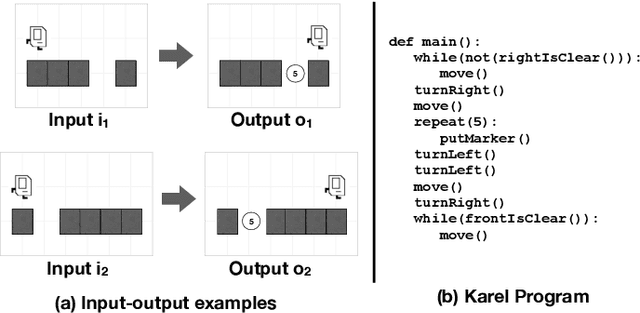



The goal of program synthesis is to automatically generate programs in a particular language from corresponding specifications, e.g. input-output behavior. Many current approaches achieve impressive results after training on randomly generated I/O examples in limited domain-specific languages (DSLs), as with string transformations in RobustFill. However, we empirically discover that applying test input generation techniques for languages with control flow and rich input space causes deep networks to generalize poorly to certain data distributions; to correct this, we propose a new methodology for controlling and evaluating the bias of synthetic data distributions over both programs and specifications. We demonstrate, using the Karel DSL and a small Calculator DSL, that training deep networks on these distributions leads to improved cross-distribution generalization performance.
RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers
Nov 10, 2019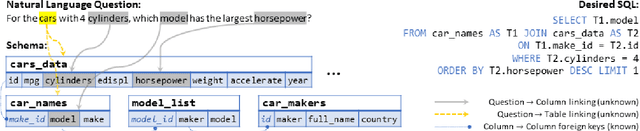
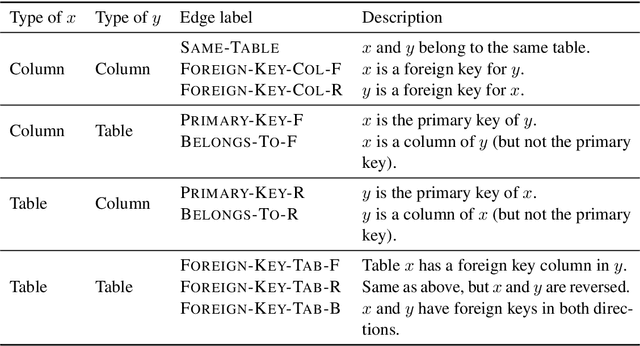
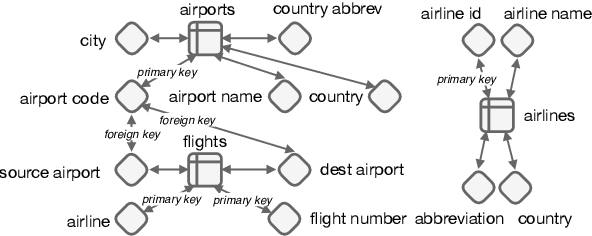
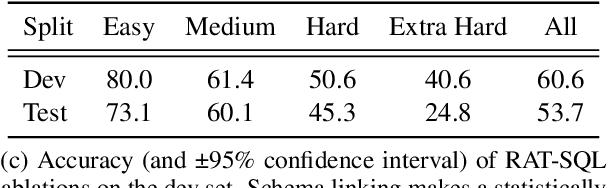
When translating natural language questions into SQL queries to answer questions from a database, contemporary semantic parsing models struggle to generalize to unseen database schemas. The generalization challenge lies in (a) encoding the database relations in an accessible way for the semantic parser, and (b) modeling alignment between database columns and their mentions in a given query. We present a unified framework, based on the relation-aware self-attention mechanism, to address schema encoding, schema linking, and feature representation within a text-to-SQL encoder. On the challenging Spider dataset this framework boosts the exact match accuracy to 53.7%, compared to 47.4% for the state-of-the-art model unaugmented with BERT embeddings. In addition, we observe qualitative improvements in the model's understanding of schema linking and alignment.
Program Synthesis and Semantic Parsing with Learned Code Idioms
Jul 23, 2019
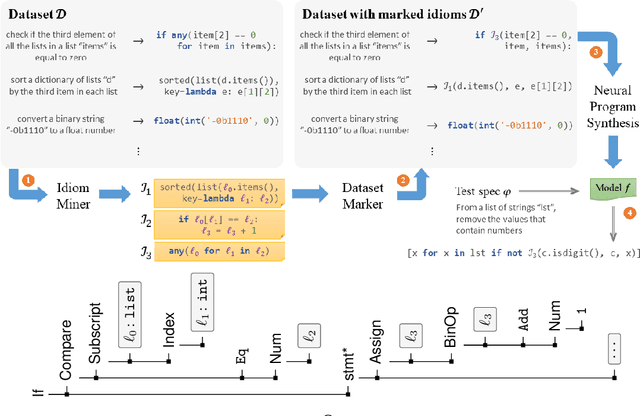
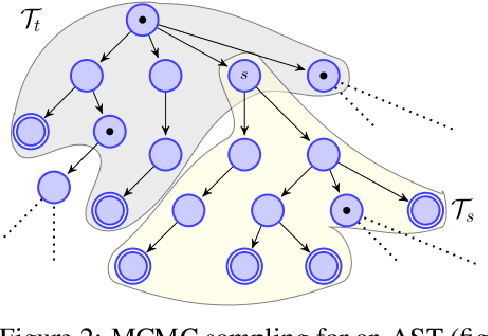
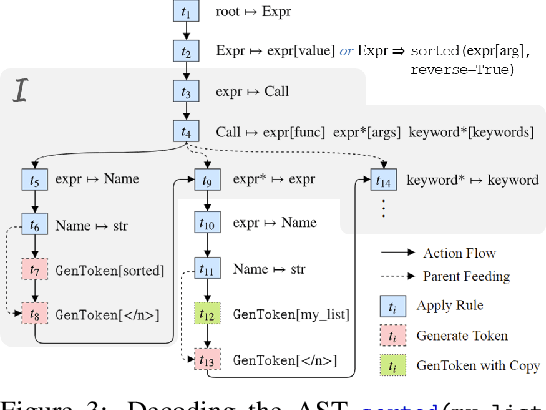
Program synthesis of general-purpose source code from natural language specifications is challenging due to the need to reason about high-level patterns in the target program and low-level implementation details at the same time. In this work, we present PATOIS, a system that allows a neural program synthesizer to explicitly interleave high-level and low-level reasoning at every generation step. It accomplishes this by automatically mining common code idioms from a given corpus, incorporating them into the underlying language for neural synthesis, and training a tree-based neural synthesizer to use these idioms during code generation. We evaluate PATOIS on two complex semantic parsing datasets and show that using learned code idioms improves the synthesizer's accuracy.
Encoding Database Schemas with Relation-Aware Self-Attention for Text-to-SQL Parsers
Jun 27, 2019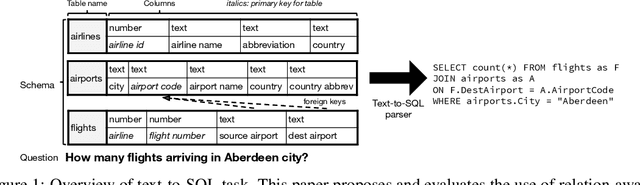
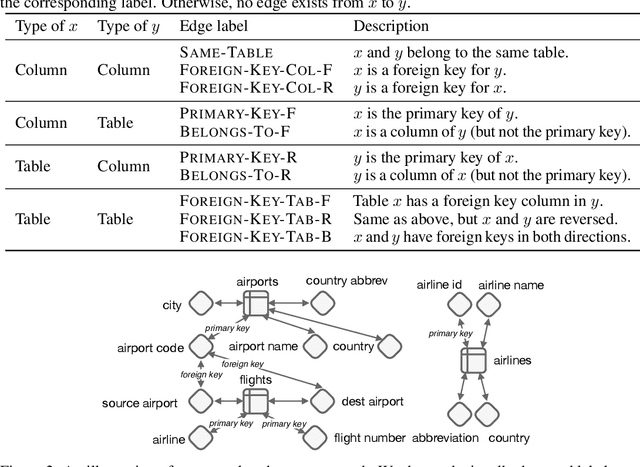
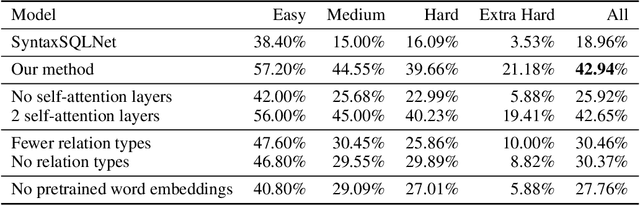
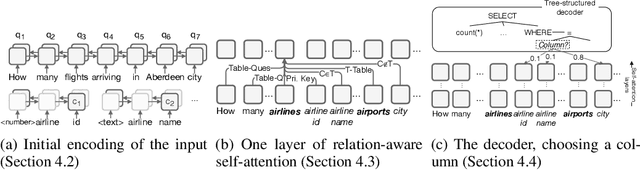
When translating natural language questions into SQL queries to answer questions from a database, we would like our methods to generalize to domains and database schemas outside of the training set. To handle complex questions and database schemas with a neural encoder-decoder paradigm, it is critical to properly encode the schema as part of the input with the question. In this paper, we use relation-aware self-attention within the encoder so that it can reason about how the tables and columns in the provided schema relate to each other and use this information in interpreting the question. We achieve significant gains on the recently-released Spider dataset with 42.94% exact match accuracy, compared to the 18.96% reported in published work.
Making Neural Programming Architectures Generalize via Recursion
Apr 21, 2017


Empirically, neural networks that attempt to learn programs from data have exhibited poor generalizability. Moreover, it has traditionally been difficult to reason about the behavior of these models beyond a certain level of input complexity. In order to address these issues, we propose augmenting neural architectures with a key abstraction: recursion. As an application, we implement recursion in the Neural Programmer-Interpreter framework on four tasks: grade-school addition, bubble sort, topological sort, and quicksort. We demonstrate superior generalizability and interpretability with small amounts of training data. Recursion divides the problem into smaller pieces and drastically reduces the domain of each neural network component, making it tractable to prove guarantees about the overall system's behavior. Our experience suggests that in order for neural architectures to robustly learn program semantics, it is necessary to incorporate a concept like recursion.
Latent Attention For If-Then Program Synthesis
Nov 07, 2016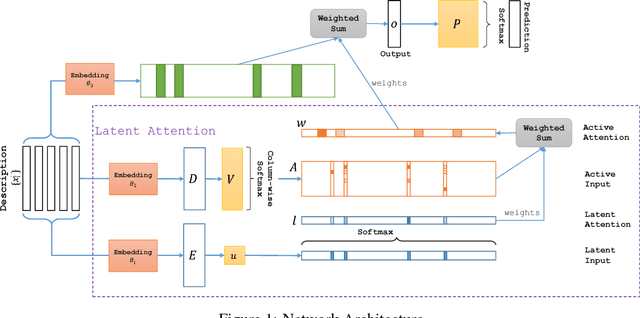
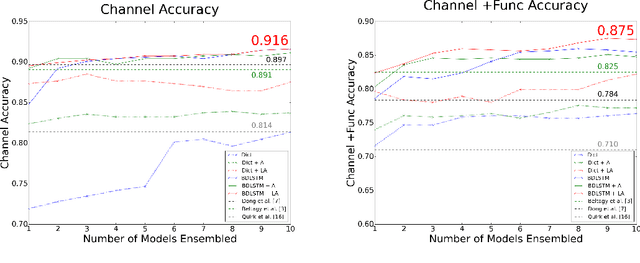
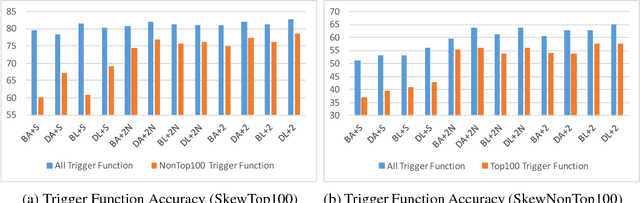
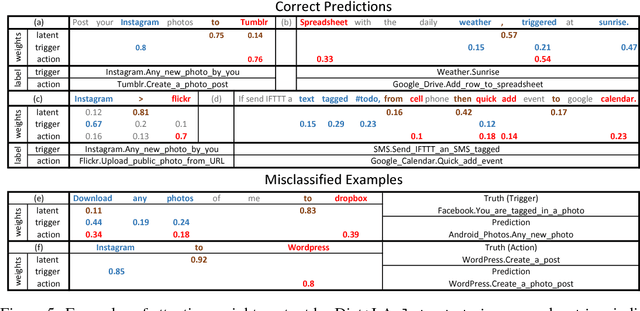
Automatic translation from natural language descriptions into programs is a longstanding challenging problem. In this work, we consider a simple yet important sub-problem: translation from textual descriptions to If-Then programs. We devise a novel neural network architecture for this task which we train end-to-end. Specifically, we introduce Latent Attention, which computes multiplicative weights for the words in the description in a two-stage process with the goal of better leveraging the natural language structures that indicate the relevant parts for predicting program elements. Our architecture reduces the error rate by 28.57% compared to prior art. We also propose a one-shot learning scenario of If-Then program synthesis and simulate it with our existing dataset. We demonstrate a variation on the training procedure for this scenario that outperforms the original procedure, significantly closing the gap to the model trained with all data.