 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Joint Compression and Synchronisation in Federated Split Learning for IoT Rainfall Prediction
Jun 23, 2026Federated split learning (FSL) enables collaborative training across bandwidth-constrained IoT devices, but repeated activation and gradient exchange creates a communication bot-tleneck. Prior work optimises either activation compression or synchronisation frequency in isolation. This paper presents an FSL framework for IoT rainfall prediction that jointly regulates activation compression and the synchronisation interval \r{ho} via a latency driven scheduler on a server with per client EMA smoothing. The system is evaluated on hourly ERA5 data from 11 weather stations through a 17 scenario simulation matrix and a four scenario Raspberry Pi deployment over a real wide-area link. The simulation matrix validates scheduler switching across low, high, and mixed latency profiles, while the Pi deployment validates the high latency endpoint selected by the same policy. AUPRC varies only slightly across configurations (0.6381-0.6484 in simulation; within 0.011 on Pi), indicating that aggressive quantisation and sparser aggregation do not materially degrade predictive quality in this setting. On Pi, the selected endpoint (int8 with rho=3) achieves an 87% reduction in activation upload payload and a 54% reduction in synchronisation traffic relative to the float32 baseline, while reducing runtime jitter from +/-688 s to +/-10 s.
Privacy-Preserving Federated Autoencoder for ECG Anomaly Detection on Edge Devices
Jun 10, 2026Continuous electrocardiography (ECG) monitoring could surface rhythm abnormalities before they escalate into cardiovascular events. However, a deployable system must satisfy three requirements simultaneously: legal-grade privacy (GDPR, HIPAA), real-time inference on constrained edge hardware, and detection quality under non-IID cross-hospital data. We design and evaluate an end-to-end federated system addressing all three for unsupervised 12-lead ECG anomaly detection on PTB-XL dataset, combining three autoencoder families (VanillaAE, ConvAE, VAE), Flower-based federated averaging (FedAvg) across ten simulated hospitals, client-side differentially private SGD (DP-SGD) with a Rényi-DP accountant, and 8-bit integer (INT8) post-training quantization with Raspberry Pi 4 benchmarking. Our main contributions are: an empirical characterization of how these mechanisms compose, practical DP-specific recommendations, and technical and security insights for a clinically sensitive setting. Federated learning matches or exceeds the centralized baseline across all architectures (ConvAE federated area under the ROC curve, AUROC, $0.782$), and an $\varepsilon$ sweep identifies $\varepsilon=4$ as the recommended clinical operating point. INT8 quantization roughly halves model size and cuts Pi 4 latency by up to $44%$ with $<0.12%$ AUROC loss. Crucially, DP and quantization penalties are empirically independent, so practitioners need not trade a strong privacy guarantee for a compact edge footprint. To our knowledge, this is the first system combining federated learning, formal $(\varepsilon,δ)$-DP, unsupervised reconstruction-based detection, and quantized AArch64 deployment.
FedFly: Towards Migration in Edge-based Distributed Federated Learning
Nov 02, 2021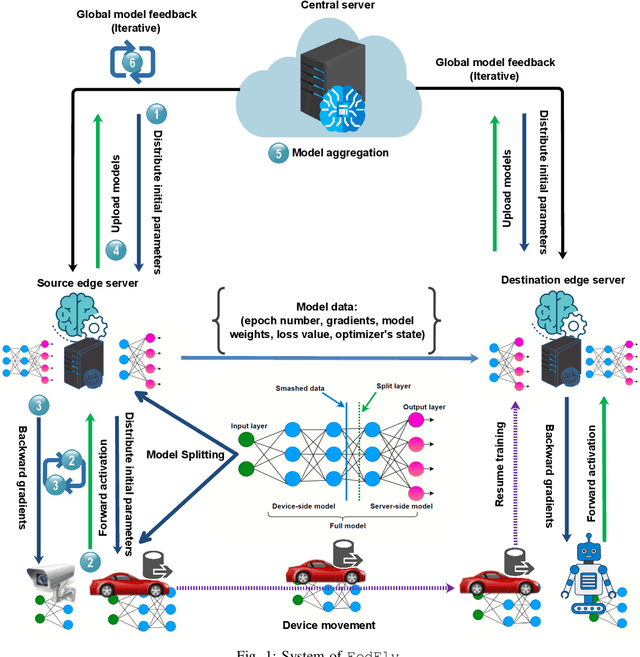
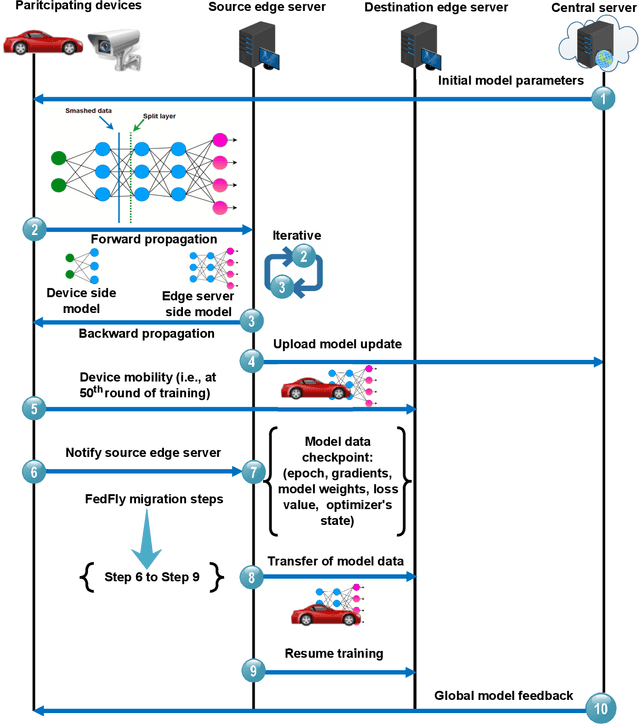
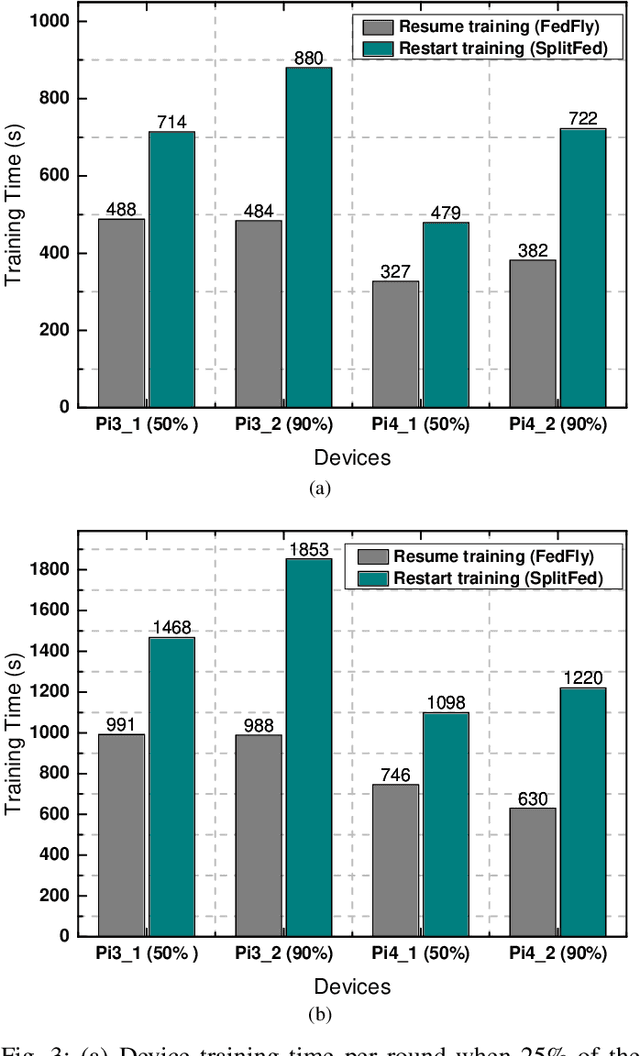
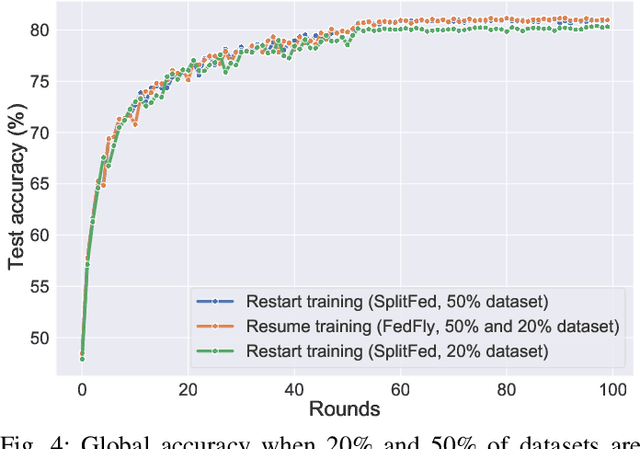
Federated learning (FL) is a privacy-preserving distributed machine learning technique that trains models without having direct access to the original data generated on devices. Since devices may be resource constrained, offloading can be used to improve FL performance by transferring computational workload from devices to edge servers. However, due to mobility, devices participating in FL may leave the network during training and need to connect to a different edge server. This is challenging because the offloaded computations from edge server need to be migrated. In line with this assertion, we present FedFly, which is, to the best of our knowledge, the first work to migrate a deep neural network (DNN) when devices move between edge servers during FL training. Our empirical results on the CIFAR-10 dataset, with both balanced and imbalanced data distribution support our claims that FedFly can reduce training time by up to 33% when a device moves after 50% of the training is completed, and by up to 45% when 90% of the training is completed when compared to state-of-the-art offloading approach in FL. FedFly has negligible overhead of 2 seconds and does not compromise accuracy. Finally, we highlight a number of open research issues for further investigation. FedFly can be downloaded from https://github.com/qub-blesson/FedFly
FedAdapt: Adaptive Offloading for IoT Devices in Federated Learning
Jul 09, 2021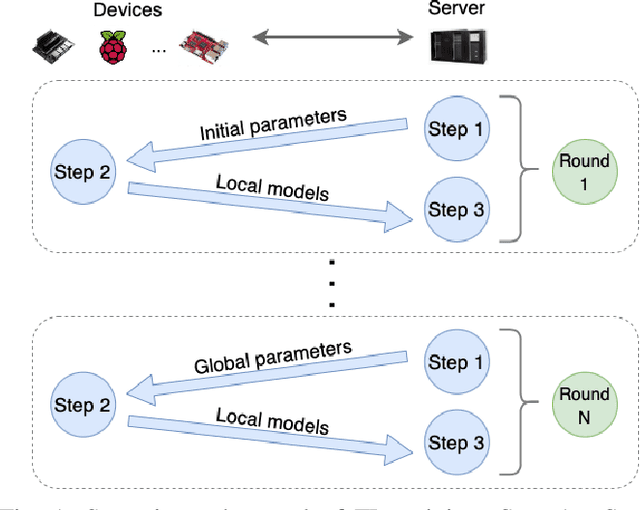
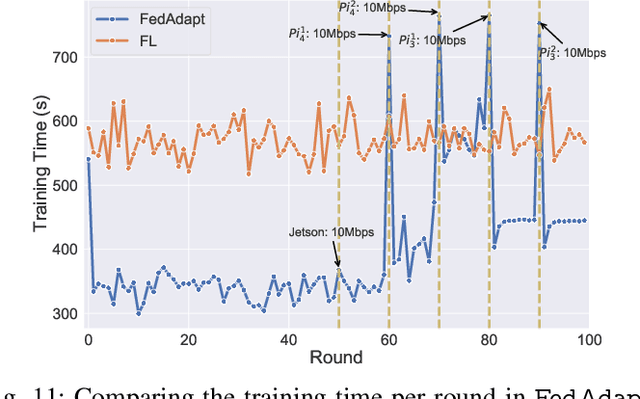
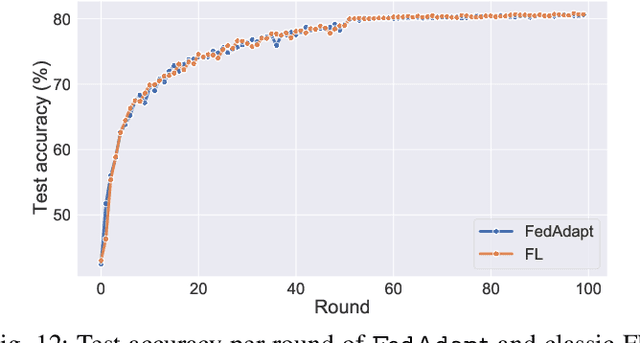
Applying Federated Learning (FL) on Internet-of-Things devices is necessitated by the large volumes of data they produce and growing concerns of data privacy. However, there are three challenges that need to be addressed to make FL efficient: (i) execute on devices with limited computational capabilities, (ii) account for stragglers due to computational heterogeneity of devices, and (iii) adapt to the changing network bandwidths. This paper presents FedAdapt, an adaptive offloading FL framework to mitigate the aforementioned challenges. FedAdapt accelerates local training in computationally constrained devices by leveraging layer offloading of deep neural networks (DNNs) to servers. Further, FedAdapt adopts reinforcement learning-based optimization and clustering to adaptively identify which layers of the DNN should be offloaded for each individual device on to a server to tackle the challenges of computational heterogeneity and changing network bandwidth. Experimental studies are carried out on a lab-based testbed comprising five IoT devices. By offloading a DNN from the device to the server FedAdapt reduces the training time of a typical IoT device by over half compared to classic FL. The training time of extreme stragglers and the overall training time can be reduced by up to 57%. Furthermore, with changing network bandwidth, FedAdapt is demonstrated to reduce the training time by up to 40% when compared to classic FL, without sacrificing accuracy. FedAdapt can be downloaded from https://github.com/qub-blesson/FedAdapt.
An Experimental Analysis of Attack Classification Using Machine Learning in IoT Networks
Jan 10, 2021

In recent years, there has been a massive increase in the amount of Internet of Things (IoT) devices as well as the data generated by such devices. The participating devices in IoT networks can be problematic due to their resource-constrained nature, and integrating security on these devices is often overlooked. This has resulted in attackers having an increased incentive to target IoT devices. As the number of attacks possible on a network increases, it becomes more difficult for traditional intrusion detection systems (IDS) to cope with these attacks efficiently. In this paper, we highlight several machine learning (ML) methods such as k-nearest neighbour (KNN), support vector machine (SVM), decision tree (DT), naive Bayes (NB), random forest (RF), artificial neural network (ANN), and logistic regression (LR) that can be used in IDS. In this work, ML algorithms are compared for both binary and multi-class classification on Bot-IoT dataset. Based on several parameters such as accuracy, precision, recall, F1 score, and log loss, we experimentally compared the aforementioned ML algorithms. In the case of HTTP distributed denial-of-service (DDoS) attack, the accuracy of RF is 99%. Furthermore, other simulation results-based precision, recall, F1 score, and log loss metric reveal that RF outperforms on all types of attacks in binary classification. However, in multi-class classification, KNN outperforms other ML algorithms with an accuracy of 99%, which is 4% higher than RF.