 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting person-level injury severity using crash narratives: A balanced approach with roadway classification and natural language process techniques
Sep 09, 2025Predicting injuries and fatalities in traffic crashes plays a critical role in enhancing road safety, improving emergency response, and guiding public health interventions. This study investigates the added value of unstructured crash narratives (written by police officers at the scene) when combined with structured crash data to predict injury severity. Two widely used Natural Language Processing (NLP) techniques, Term Frequency-Inverse Document Frequency (TF-IDF) and Word2Vec, were employed to extract semantic meaning from the narratives, and their effectiveness was compared. To address the challenge of class imbalance, a K-Nearest Neighbors-based oversampling method was applied to the training data prior to modeling. The dataset consists of crash records from Kentucky spanning 2019 to 2023. To account for roadway heterogeneity, three road classification schemes were used: (1) eight detailed functional classes (e.g., Urban Two-Lane, Rural Interstate, Urban Multilane Divided), (2) four broader paired categories (e.g., Urban vs. Rural, Freeway vs. Non-Freeway), and (3) a unified dataset without classification. A total of 102 machine learning models were developed by combining structured features and narrative-based features using the two NLP techniques alongside three ensemble algorithms: XGBoost, Random Forest, and AdaBoost. Results demonstrate that models incorporating narrative data consistently outperform those relying solely on structured data. Among all combinations, TF-IDF coupled with XGBoost yielded the most accurate predictions in most subgroups. The findings highlight the power of integrating textual and structured crash information to enhance person-level injury prediction. This work offers a practical and adaptable framework for transportation safety professionals to improve crash severity modeling, guide policy decisions, and design more effective countermeasures.
FARSA: Fully Automated Roadway Safety Assessment
Jan 17, 2019
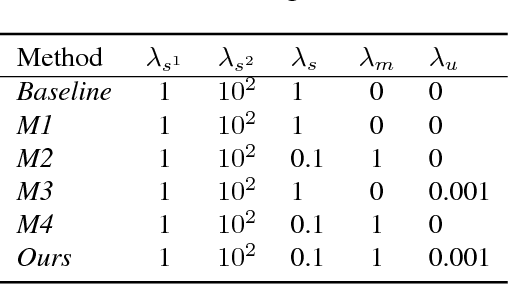

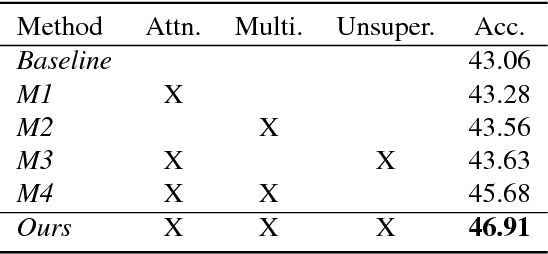
This paper addresses the task of road safety assessment. An emerging approach for conducting such assessments in the United States is through the US Road Assessment Program (usRAP), which rates roads from highest risk (1 star) to lowest (5 stars). Obtaining these ratings requires manual, fine-grained labeling of roadway features in street-level panoramas, a slow and costly process. We propose to automate this process using a deep convolutional neural network that directly estimates the star rating from a street-level panorama, requiring milliseconds per image at test time. Our network also estimates many other road-level attributes, including curvature, roadside hazards, and the type of median. To support this, we incorporate task-specific attention layers so the network can focus on the panorama regions that are most useful for a particular task. We evaluated our approach on a large dataset of real-world images from two US states. We found that incorporating additional tasks, and using a semi-supervised training approach, significantly reduced overfitting problems, allowed us to optimize more layers of the network, and resulted in higher accuracy.