 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJunction Tree Variational Autoencoder for Molecular Graph Generation
Feb 19, 2018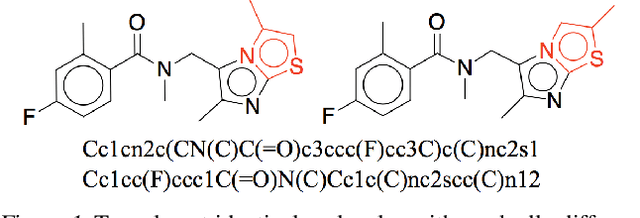
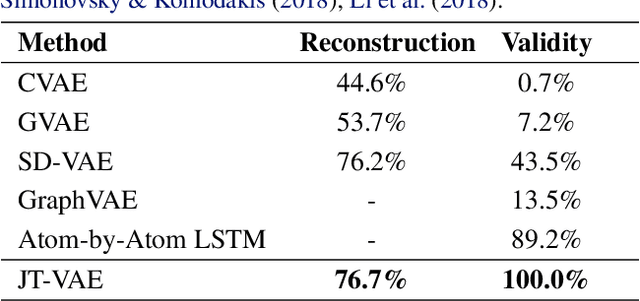
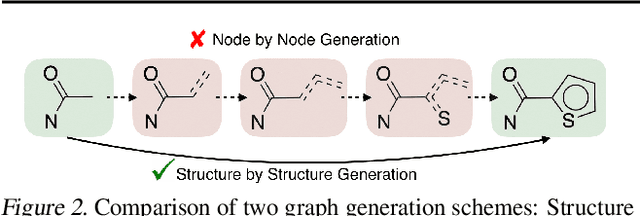
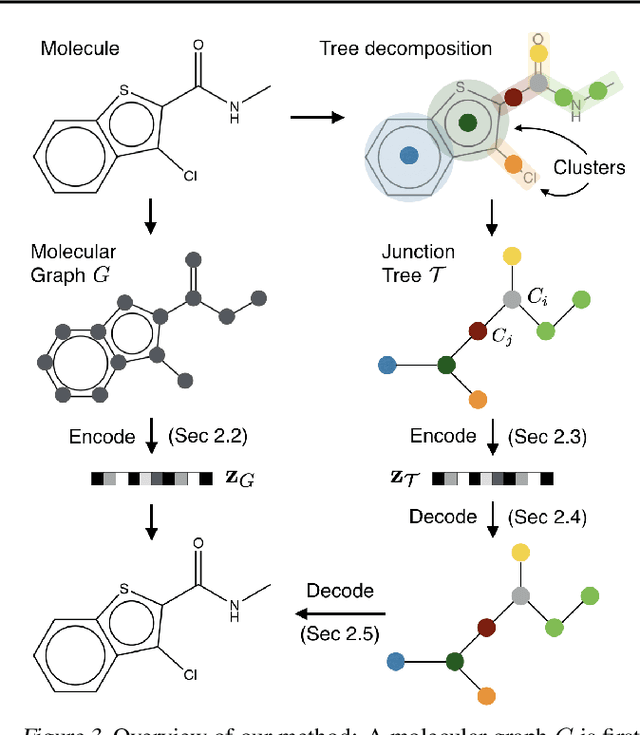
We seek to automate the design of molecules based on specific chemical properties. In computational terms, this task involves continuous embedding and generation of molecular graphs. Our primary contribution is the direct realization of molecular graphs, a task previously approached by generating linear SMILES strings instead of graphs. Our junction tree variational autoencoder generates molecular graphs in two phases, by first generating a tree-structured scaffold over chemical substructures, and then combining them into a molecule with a graph message passing network. This approach allows us to incrementally expand molecules while maintaining chemical validity at every step. We evaluate our model on multiple tasks ranging from molecular generation to optimization. Across these tasks, our model outperforms previous state-of-the-art baselines by a significant margin.
Predicting Organic Reaction Outcomes with Weisfeiler-Lehman Network
Dec 29, 2017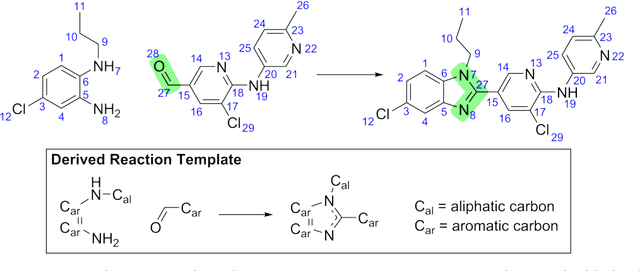
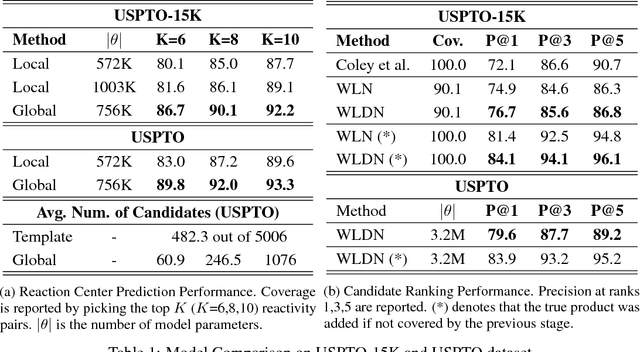
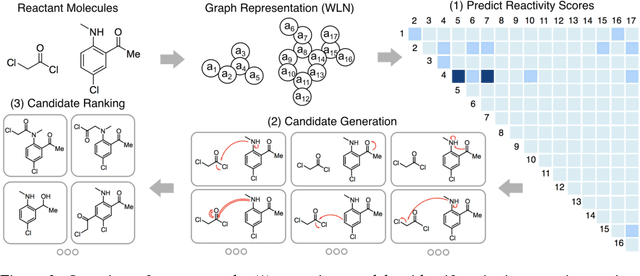
The prediction of organic reaction outcomes is a fundamental problem in computational chemistry. Since a reaction may involve hundreds of atoms, fully exploring the space of possible transformations is intractable. The current solution utilizes reaction templates to limit the space, but it suffers from coverage and efficiency issues. In this paper, we propose a template-free approach to efficiently explore the space of product molecules by first pinpointing the reaction center -- the set of nodes and edges where graph edits occur. Since only a small number of atoms contribute to reaction center, we can directly enumerate candidate products. The generated candidates are scored by a Weisfeiler-Lehman Difference Network that models high-order interactions between changes occurring at nodes across the molecule. Our framework outperforms the top-performing template-based approach with a 10\% margin, while running orders of magnitude faster. Finally, we demonstrate that the model accuracy rivals the performance of domain experts.
Representation Learning for Grounded Spatial Reasoning
Nov 11, 2017The interpretation of spatial references is highly contextual, requiring joint inference over both language and the environment. We consider the task of spatial reasoning in a simulated environment, where an agent can act and receive rewards. The proposed model learns a representation of the world steered by instruction text. This design allows for precise alignment of local neighborhoods with corresponding verbalizations, while also handling global references in the instructions. We train our model with reinforcement learning using a variant of generalized value iteration. The model outperforms state-of-the-art approaches on several metrics, yielding a 45% reduction in goal localization error.
Style Transfer from Non-Parallel Text by Cross-Alignment
Nov 06, 2017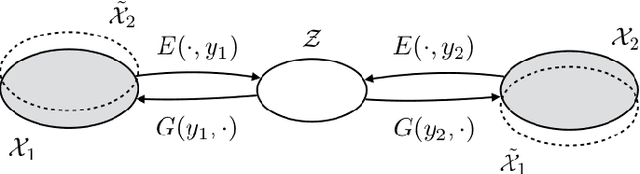


This paper focuses on style transfer on the basis of non-parallel text. This is an instance of a broad family of problems including machine translation, decipherment, and sentiment modification. The key challenge is to separate the content from other aspects such as style. We assume a shared latent content distribution across different text corpora, and propose a method that leverages refined alignment of latent representations to perform style transfer. The transferred sentences from one style should match example sentences from the other style as a population. We demonstrate the effectiveness of this cross-alignment method on three tasks: sentiment modification, decipherment of word substitution ciphers, and recovery of word order.
Deriving Neural Architectures from Sequence and Graph Kernels
Oct 30, 2017
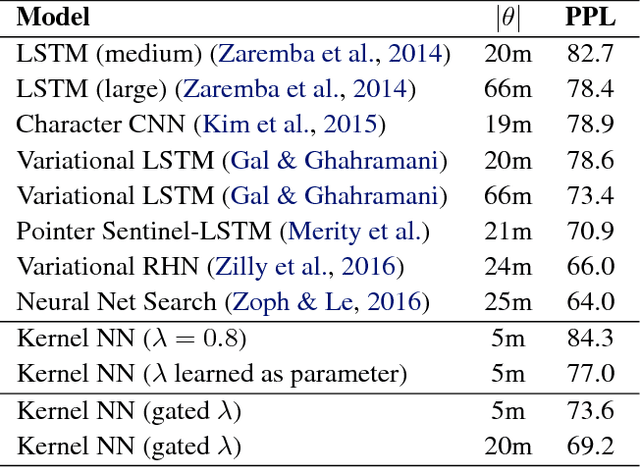
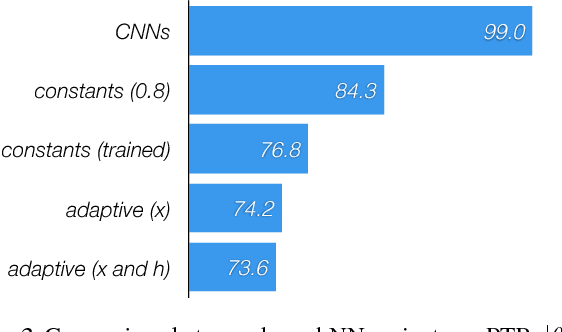
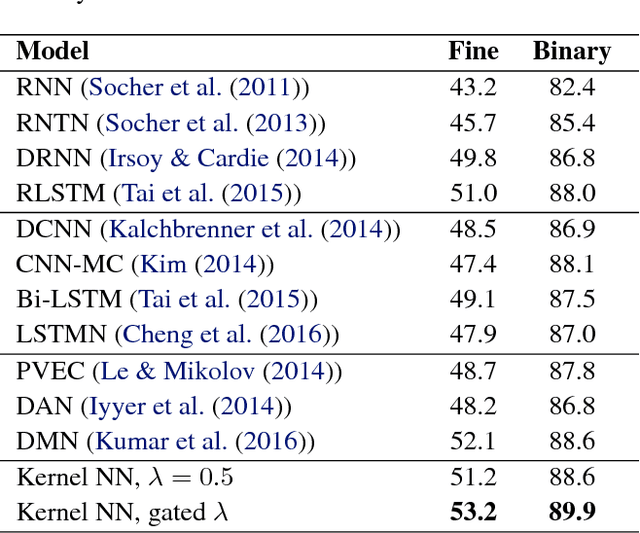
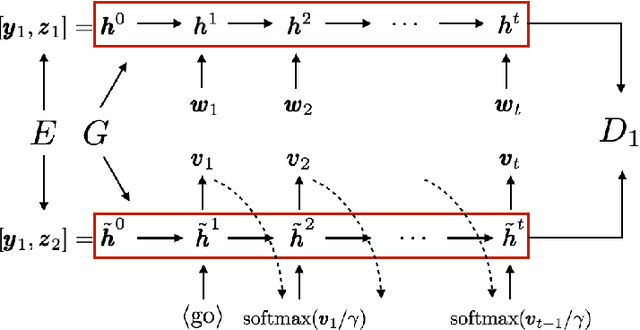
The design of neural architectures for structured objects is typically guided by experimental insights rather than a formal process. In this work, we appeal to kernels over combinatorial structures, such as sequences and graphs, to derive appropriate neural operations. We introduce a class of deep recurrent neural operations and formally characterize their associated kernel spaces. Our recurrent modules compare the input to virtual reference objects (cf. filters in CNN) via the kernels. Similar to traditional neural operations, these reference objects are parameterized and directly optimized in end-to-end training. We empirically evaluate the proposed class of neural architectures on standard applications such as language modeling and molecular graph regression, achieving state-of-the-art results across these applications.
Aspect-augmented Adversarial Networks for Domain Adaptation
Sep 25, 2017We introduce a neural method for transfer learning between two (source and target) classification tasks or aspects over the same domain. Rather than training on target labels, we use a few keywords pertaining to source and target aspects indicating sentence relevance instead of document class labels. Documents are encoded by learning to embed and softly select relevant sentences in an aspect-dependent manner. A shared classifier is trained on the source encoded documents and labels, and applied to target encoded documents. We ensure transfer through aspect-adversarial training so that encoded documents are, as sets, aspect-invariant. Experimental results demonstrate that our approach outperforms different baselines and model variants on two datasets, yielding an improvement of 27% on a pathology dataset and 5% on a review dataset.
Deep Transfer in Reinforcement Learning by Language Grounding
Aug 01, 2017



In this paper, we explore the utilization of natural language to drive transfer for reinforcement learning (RL). Despite the wide-spread application of deep RL techniques, learning generalized policy representations that work across domains remains a challenging problem. We demonstrate that textual descriptions of environments provide a compact intermediate channel to facilitate effective policy transfer. We employ a model-based RL approach consisting of a differentiable planning module, a model-free component and a factorized representation to effectively utilize entity descriptions. Our model outperforms prior work on both transfer and multi-task scenarios in a variety of different environments.
Unsupervised Learning of Morphological Forests
Feb 22, 2017This paper focuses on unsupervised modeling of morphological families, collectively comprising a forest over the language vocabulary. This formulation enables us to capture edgewise properties reflecting single-step morphological derivations, along with global distributional properties of the entire forest. These global properties constrain the size of the affix set and encourage formation of tight morphological families. The resulting objective is solved using Integer Linear Programming (ILP) paired with contrastive estimation. We train the model by alternating between optimizing the local log-linear model and the global ILP objective. We evaluate our system on three tasks: root detection, clustering of morphological families and segmentation. Our experiments demonstrate that our model yields consistent gains in all three tasks compared with the best published results.
Rationalizing Neural Predictions
Nov 02, 2016

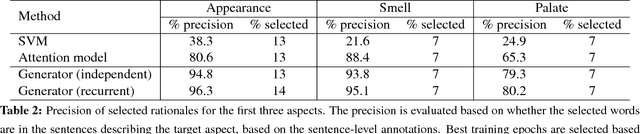
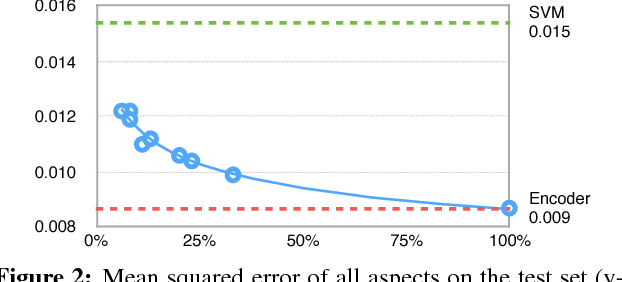
Prediction without justification has limited applicability. As a remedy, we learn to extract pieces of input text as justifications -- rationales -- that are tailored to be short and coherent, yet sufficient for making the same prediction. Our approach combines two modular components, generator and encoder, which are trained to operate well together. The generator specifies a distribution over text fragments as candidate rationales and these are passed through the encoder for prediction. Rationales are never given during training. Instead, the model is regularized by desiderata for rationales. We evaluate the approach on multi-aspect sentiment analysis against manually annotated test cases. Our approach outperforms attention-based baseline by a significant margin. We also successfully illustrate the method on the question retrieval task.
Improving Information Extraction by Acquiring External Evidence with Reinforcement Learning
Sep 27, 2016



Most successful information extraction systems operate with access to a large collection of documents. In this work, we explore the task of acquiring and incorporating external evidence to improve extraction accuracy in domains where the amount of training data is scarce. This process entails issuing search queries, extraction from new sources and reconciliation of extracted values, which are repeated until sufficient evidence is collected. We approach the problem using a reinforcement learning framework where our model learns to select optimal actions based on contextual information. We employ a deep Q-network, trained to optimize a reward function that reflects extraction accuracy while penalizing extra effort. Our experiments on two databases -- of shooting incidents, and food adulteration cases -- demonstrate that our system significantly outperforms traditional extractors and a competitive meta-classifier baseline.