 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Greater Context for Question Generation
Oct 22, 2019
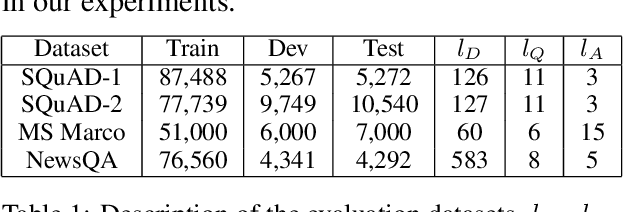
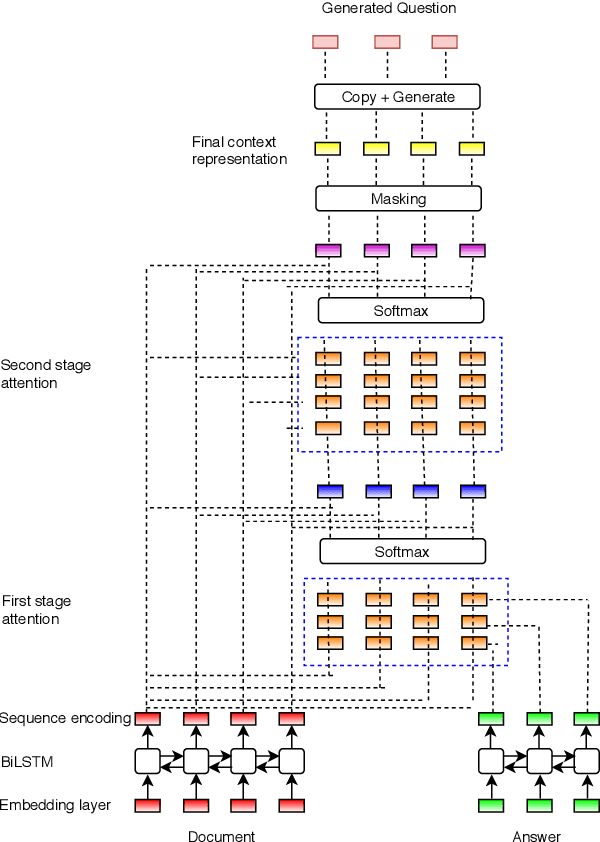
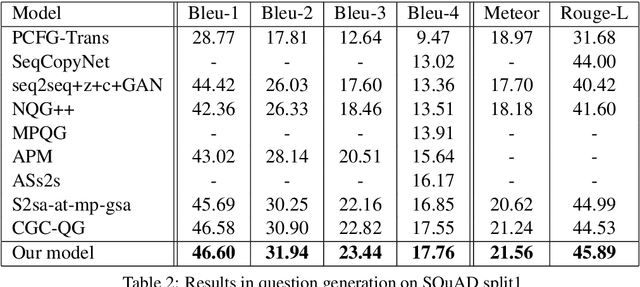
Automatic question generation can benefit many applications ranging from dialogue systems to reading comprehension. While questions are often asked with respect to long documents, there are many challenges with modeling such long documents. Many existing techniques generate questions by effectively looking at one sentence at a time, leading to questions that are easy and not reflective of the human process of question generation. Our goal is to incorporate interactions across multiple sentences to generate realistic questions for long documents. In order to link a broad document context to the target answer, we represent the relevant context via a multi-stage attention mechanism, which forms the foundation of a sequence to sequence model. We outperform state-of-the-art methods on question generation on three question-answering datasets -- SQuAD, MS MARCO and NewsQA.
Learning to Make Generalizable and Diverse Predictions for Retrosynthesis
Oct 21, 2019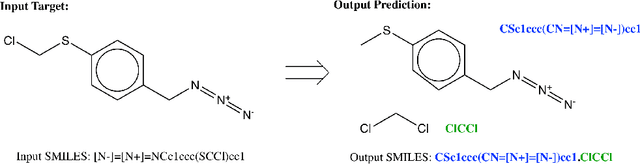
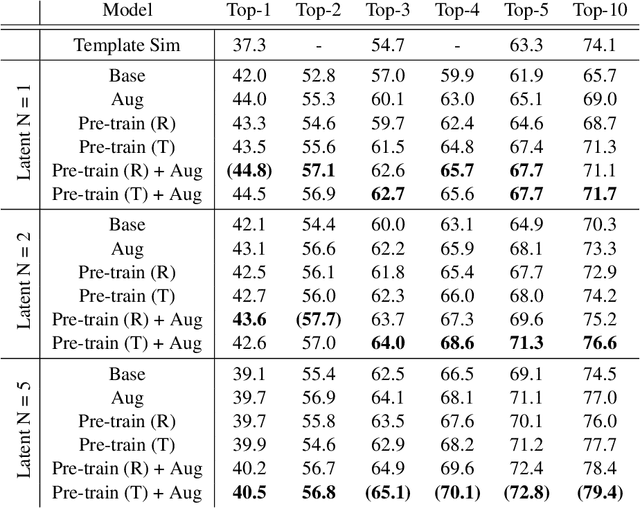
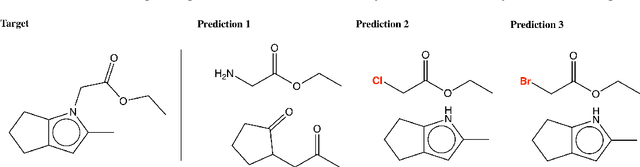

We propose a new model for making generalizable and diverse retrosynthetic reaction predictions. Given a target compound, the task is to predict the likely chemical reactants to produce the target. This generative task can be framed as a sequence-to-sequence problem by using the SMILES representations of the molecules. Building on top of the popular Transformer architecture, we propose two novel pre-training methods that construct relevant auxiliary tasks (plausible reactions) for our problem. Furthermore, we incorporate a discrete latent variable model into the architecture to encourage the model to produce a diverse set of alternative predictions. On the 50k subset of reaction examples from the United States patent literature (USPTO-50k) benchmark dataset, our model greatly improves performance over the baseline, while also generating predictions that are more diverse.
Automatic Fact-guided Sentence Modification
Sep 30, 2019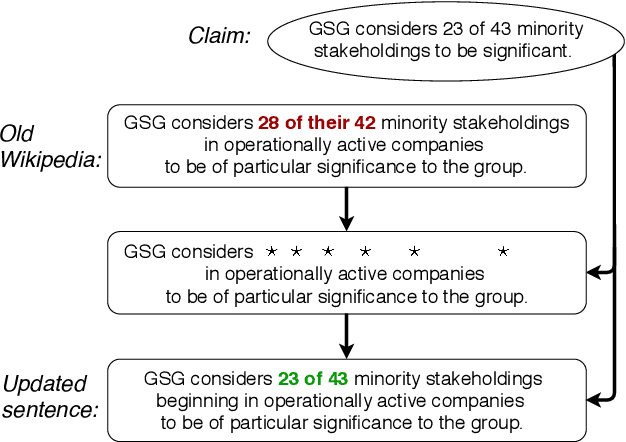
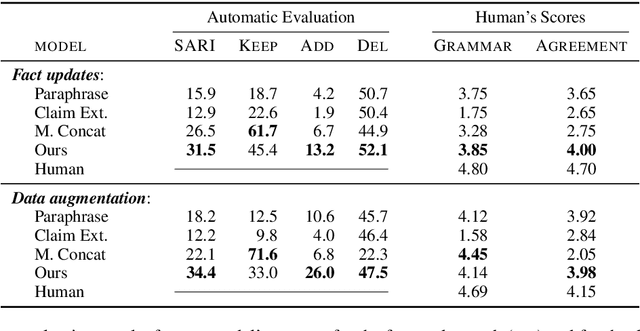
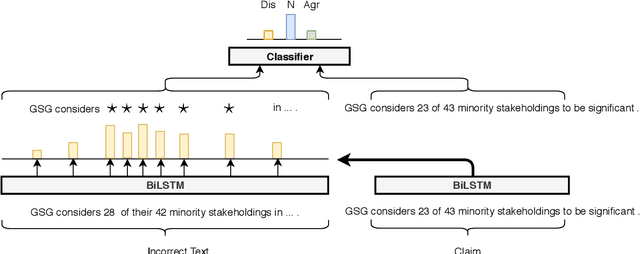
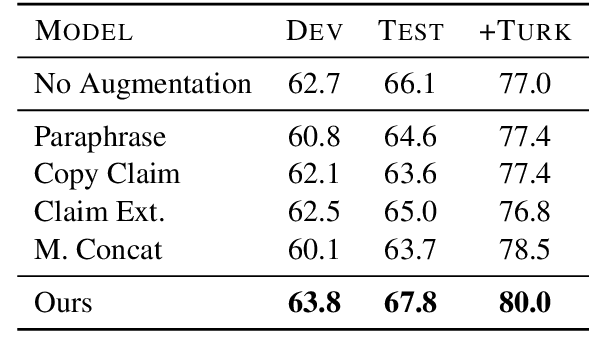
Online encyclopediae like Wikipedia contain large amounts of text that need frequent corrections and updates. The new information may contradict existing content in encyclopediae. In this paper, we focus on rewriting such dynamically changing articles. This is a challenging constrained generation task, as the output must be consistent with the new information and fit into the rest of the existing document. To this end, we propose a two-step solution: (1) We identify and remove the contradicting components in a target text for a given claim, using a neutralizing stance model; (2) We expand the remaining text to be consistent with the given claim, using a novel two-encoder sequence-to-sequence model with copy attention. Applied to a Wikipedia fact update dataset, our method successfully generates updated sentences for new claims, achieving the highest SARI score. Furthermore, we demonstrate that generating synthetic data through such rewritten sentences can successfully augment the FEVER fact-checking training dataset, leading to a relative error reduction of 13%.
Working Hard or Hardly Working: Challenges of Integrating Typology into Neural Dependency Parsers
Sep 20, 2019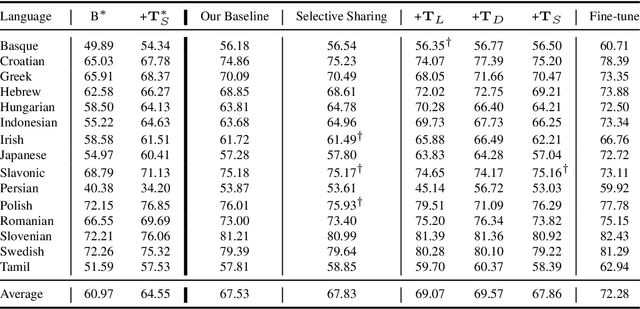
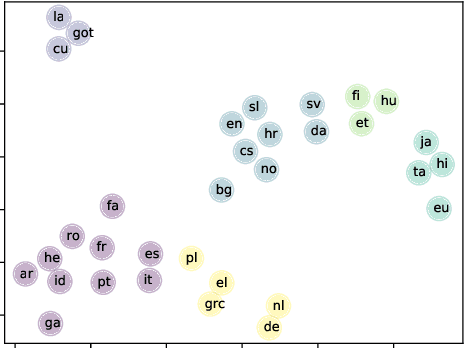
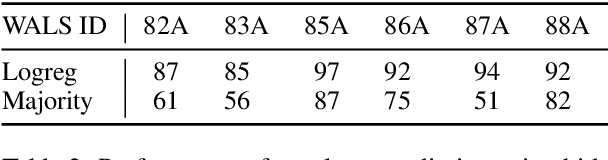
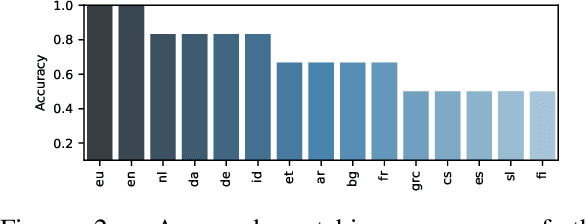
This paper explores the task of leveraging typology in the context of cross-lingual dependency parsing. While this linguistic information has shown great promise in pre-neural parsing, results for neural architectures have been mixed. The aim of our investigation is to better understand this state-of-the-art. Our main findings are as follows: 1) The benefit of typological information is derived from coarsely grouping languages into syntactically-homogeneous clusters rather than from learning to leverage variations along individual typological dimensions in a compositional manner; 2) Typology consistent with the actual corpus statistics yields better transfer performance; 3) Typological similarity is only a rough proxy of cross-lingual transferability with respect to parsing.
Towards Debiasing Fact Verification Models
Aug 31, 2019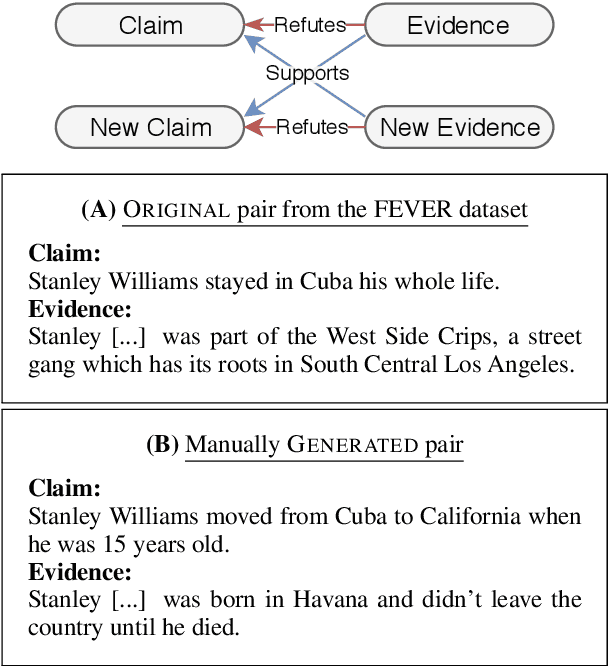
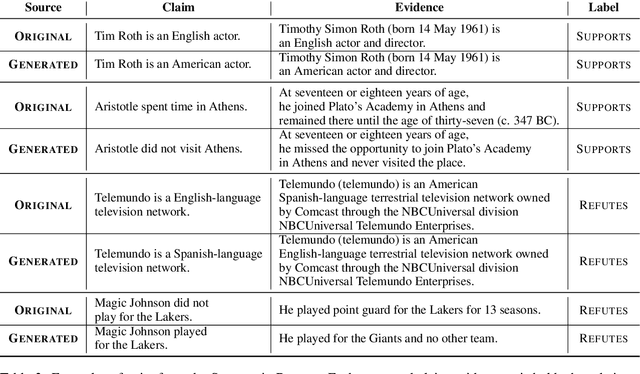
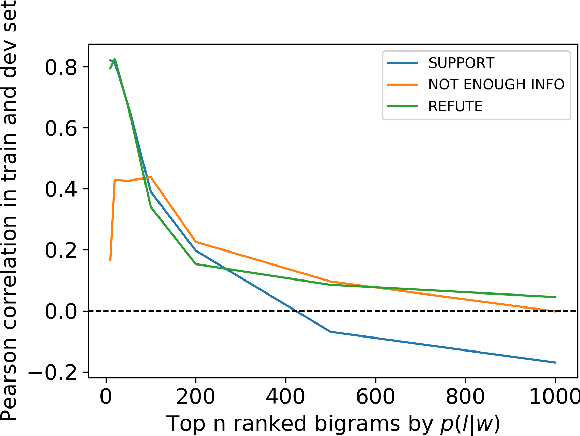
Fact verification requires validating a claim in the context of evidence. We show, however, that in the popular FEVER dataset this might not necessarily be the case. Claim-only classifiers perform competitively with top evidence-aware models. In this paper, we investigate the cause of this phenomenon, identifying strong cues for predicting labels solely based on the claim, without considering any evidence. We create an evaluation set that avoids those idiosyncrasies. The performance of FEVER-trained models significantly drops when evaluated on this test set. Therefore, we introduce a regularization method which alleviates the effect of bias in the training data, obtaining improvements on the newly created test set. This work is a step towards a more sound evaluation of reasoning capabilities in fact verification models.
Are We Safe Yet? The Limitations of Distributional Features for Fake News Detection
Aug 26, 2019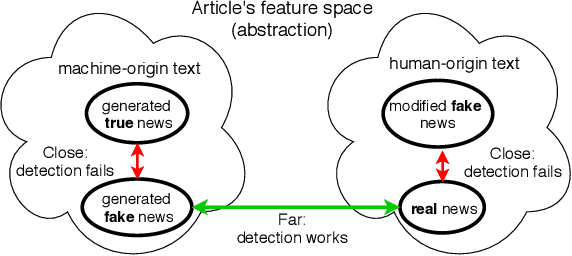


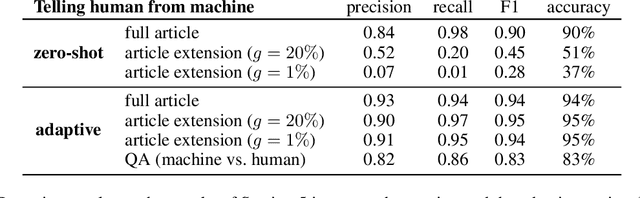
Automatic detection of fake news --- texts that are deceitful and misleading --- is a long outstanding and largely unsolved problem. Worse yet, recent developments in language modeling allow for the automatic generation of such texts. One approach that has recently gained attention detects these fake news using stylometry-based provenance, i.e. tracing a text's writing style back to its producing source and determining whether the source is malicious. This was shown to be highly effective under the assumption that legitimate text is produced by humans, and fake text is produced by a language model. In this work, we identify a fundamental problem with provenance-based approaches against attackers that auto-generate fake news: fake and legitimate texts can originate from nearly identical sources. First, a legitimate text might be auto-generated in a similar process to that of fake text, and second, attackers can automatically corrupt articles originating from legitimate human sources. We demonstrate these issues by simulating attacks in such settings, and find that the provenance approach fails to defend against them. Our findings highlight the importance of assessing the veracity of the text rather than solely relying on its style or source. We also open up a discussion on the types of benchmarks that should be used to evaluate neural fake news detectors.
Few-shot Text Classification with Distributional Signatures
Aug 16, 2019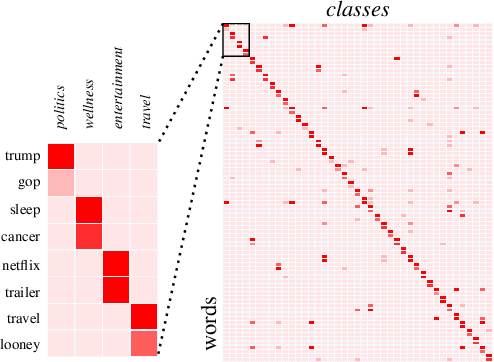
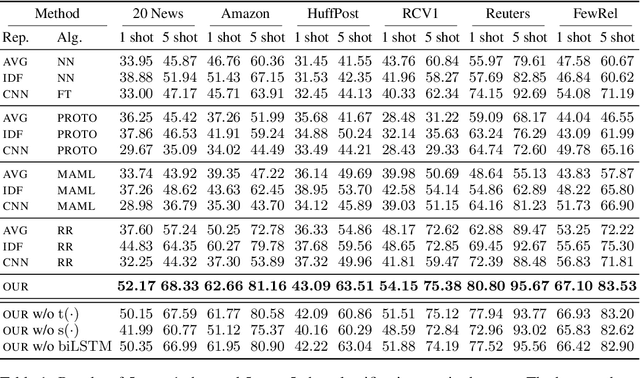

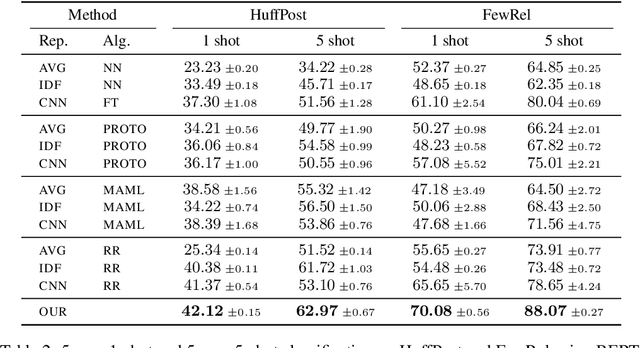
In this paper, we explore meta-learning for few-shot text classification. Meta-learning has shown strong performance in computer vision, where low-level patterns are transferable across learning tasks. However, directly applying this approach to text is challenging--words highly informative for one task may have little significance for another. Thus, rather than learning solely from words, our model also leverages their distributional signatures, which encode pertinent word occurrence patterns. Our model is trained within a meta-learning framework to map these signatures into attention scores, which are then used to weight the lexical representations of words. We demonstrate that our model consistently outperforms prototypical networks in both few-shot text classification and relation classification by a significant margin across six benchmark datasets (19.96% on average in 1-shot classification). Our code is available at https://github.com/YujiaBao/Distributional-Signatures.
Neural Decipherment via Minimum-Cost Flow: from Ugaritic to Linear B
Jun 16, 2019

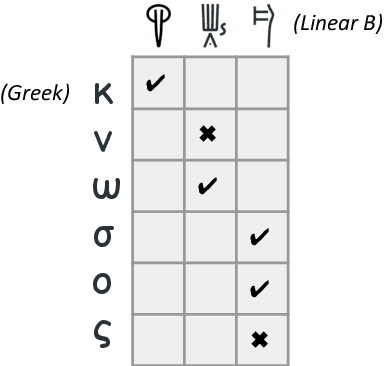
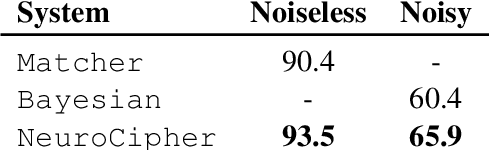
In this paper we propose a novel neural approach for automatic decipherment of lost languages. To compensate for the lack of strong supervision signal, our model design is informed by patterns in language change documented in historical linguistics. The model utilizes an expressive sequence-to-sequence model to capture character-level correspondences between cognates. To effectively train the model in an unsupervised manner, we innovate the training procedure by formalizing it as a minimum-cost flow problem. When applied to the decipherment of Ugaritic, we achieve a 5.5% absolute improvement over state-of-the-art results. We also report the first automatic results in deciphering Linear B, a syllabic language related to ancient Greek, where our model correctly translates 67.3% of cognates.
Multi-resolution Autoregressive Graph-to-Graph Translation for Molecules
Jun 11, 2019
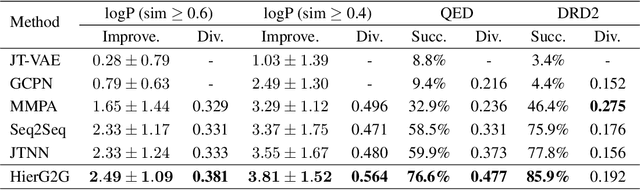
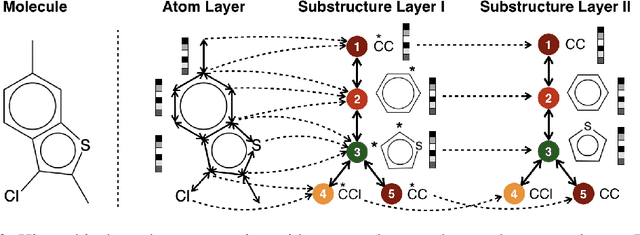
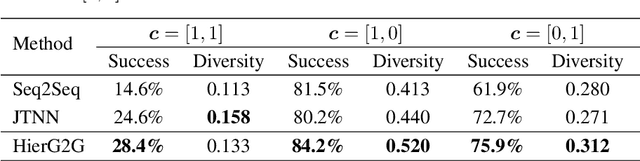
The problem of accelerating drug discovery relies heavily on automatic tools to optimize precursor molecules to afford them with better biochemical properties. Our work in this paper substantially extends prior state-of-the-art on graph-to-graph translation methods for molecular optimization. In particular, we realize coherent multi-resolution representations by interweaving trees over substructures with the atom-level encoding of the original molecular graph. Moreover, our graph decoder is fully autoregressive, and interleaves each step of adding a new substructure with the process of resolving its connectivity to the emerging molecule. We evaluate our model on multiple molecular optimization tasks and show that our model outperforms previous state-of-the-art baselines by a large margin.
Latent Space Secrets of Denoising Text-Autoencoders
May 29, 2019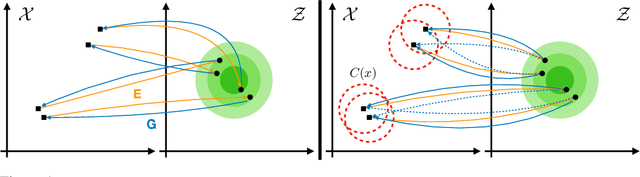
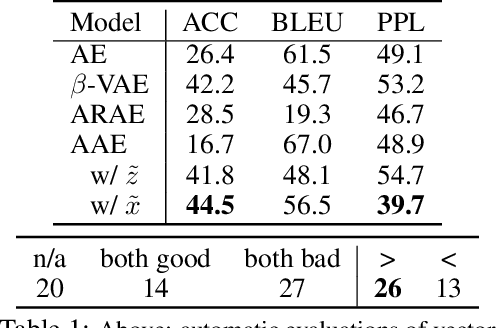
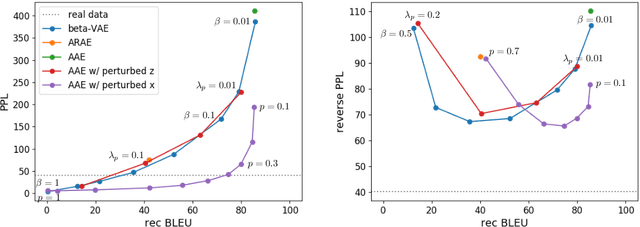
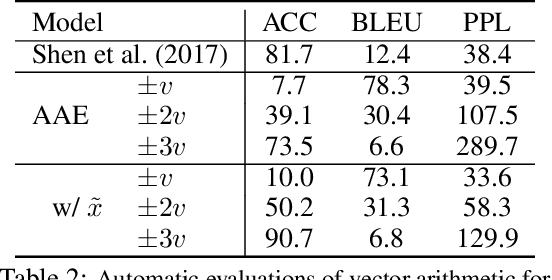
While neural language models have recently demonstrated impressive performance in unconditional text generation, controllable generation and manipulation of text remain challenging. Latent variable generative models provide a natural approach for control, but their application to text has proven more difficult than to images. Models such as variational autoencoders may suffer from posterior collapse or learning an irregular latent geometry. We propose to instead employ adversarial autoencoders (AAEs) and add local perturbations by randomly replacing/removing words from input sentences during training. Within the prior enforced by the adversary, structured perturbations in the data space begin to carve and organize the latent space. Theoretically, we prove that perturbations encourage similar sentences to map to similar latent representations. Experimentally, we investigate the trade-off between text-generation and autoencoder-reconstruction capabilities. Our straightforward approach significantly improves over regular AAEs as well as other autoencoders, and enables altering the tense/sentiment of sentences through simple addition of a fixed vector offset to their latent representation.