 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenefits of Jointly Training Autoencoders: An Improved Neural Tangent Kernel Analysis
Nov 27, 2019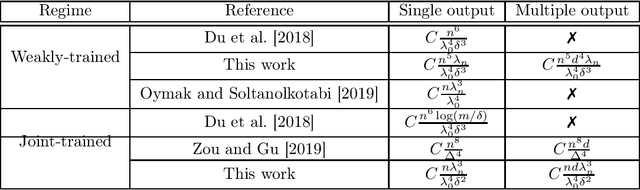
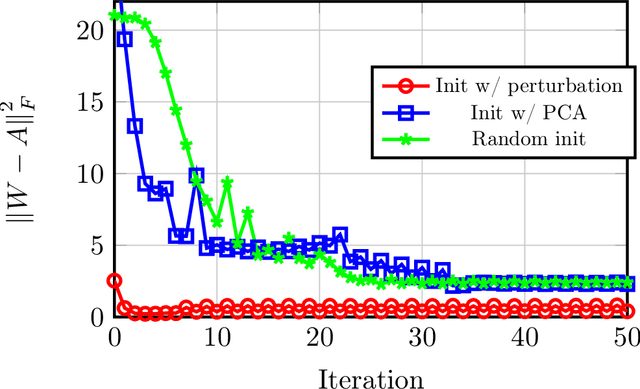
A remarkable recent discovery in machine learning has been that deep neural networks can achieve impressive performance (in terms of both lower training error and higher generalization capacity) in the regime where they are massively over-parameterized. Consequently, over the last several months, the community has devoted growing interest in analyzing optimization and generalization properties of over-parameterized networks, and several breakthrough works have led to important theoretical progress. However, the majority of existing work only applies to supervised learning scenarios and hence are limited to settings such as classification and regression. In contrast, the role of over-parameterization in the unsupervised setting has gained far less attention. In this paper, we study the gradient dynamics of two-layer over-parameterized autoencoders with ReLU activation. We make very few assumptions about the given training dataset (other than mild non-degeneracy conditions). Starting from a randomly initialized autoencoder network, we rigorously prove the linear convergence of gradient descent in two learning regimes, namely: (i) the weakly-trained regime where only the encoder is trained, and (ii) the jointly-trained regime where both the encoder and the decoder are trained. Our results indicate the considerable benefits of joint training over weak training for finding global optima, achieving a dramatic decrease in the required level of over-parameterization. We also analyze the case of weight-tied autoencoders (which is a commonly used architectural choice in practical settings) and prove that in the over-parameterized setting, training such networks from randomly initialized points leads to certain unexpected degeneracies.
Matrix Completion under Low-Rank Missing Mechanism
Dec 19, 2018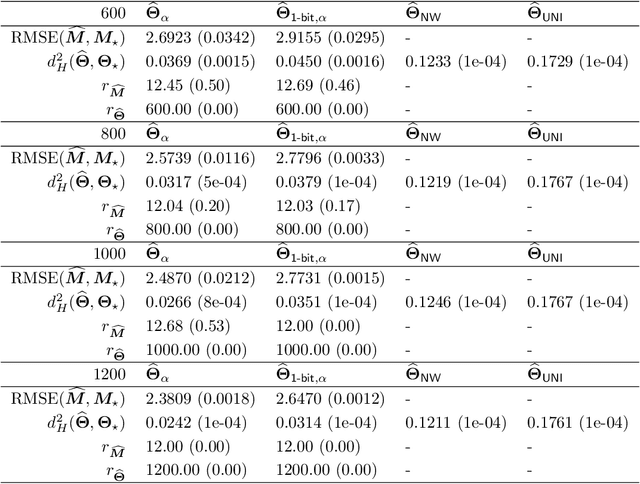
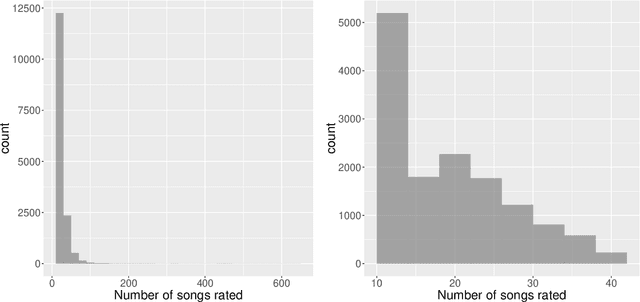
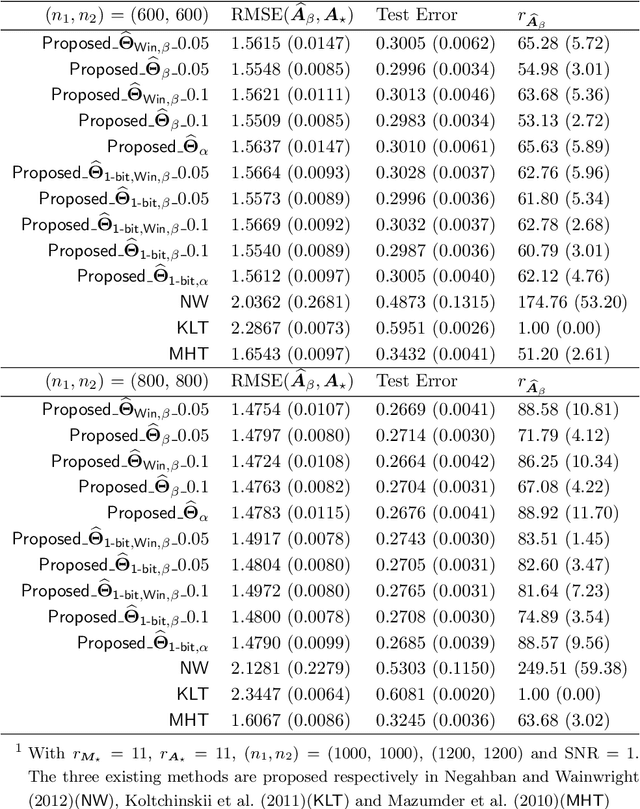
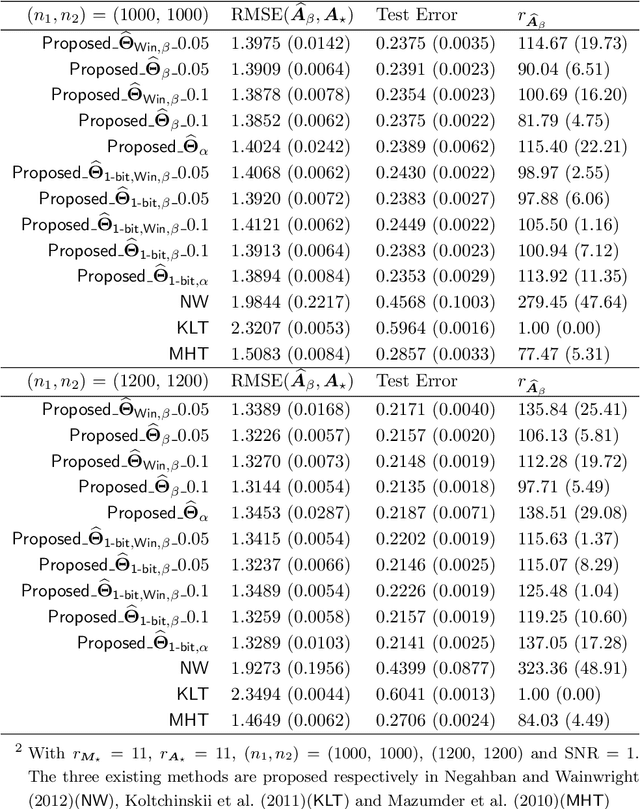
This paper investigates the problem of matrix completion from corrupted data, when a low-rank missing mechanism is considered. The better recovery of missing mechanism often helps completing the unobserved entries of the high-dimensional target matrix. Instead of the widely used uniform risk function, we weight the observations by inverse probabilities of observation, which are estimated through a specifically designed high-dimensional estimation procedure. Asymptotic convergence rates of the proposed estimators for both the observation probabilities and the target matrix are studied. The empirical performance of the proposed methodology is illustrated via both numerical experiments and a real data application.
Autoencoders Learn Generative Linear Models
Jun 02, 2018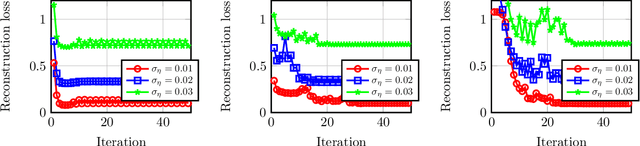
Recent progress in learning theory has led to the emergence of provable algorithms for training certain families of neural networks. Under the assumption that the training data is sampled from a suitable generative model, the weights of the trained networks obtained by these algorithms recover (either exactly or approximately) the generative model parameters. However, the large majority of these results are only applicable to supervised learning architectures. In this paper, we complement this line of work by providing a series of results for unsupervised learning with neural networks. Specifically, we study the familiar setting of shallow autoencoder architectures with shared weights. We focus on three generative models for the data: (i) the mixture-of-gaussians model, (ii) the sparse coding model, and (iii) the non-negative sparsity model. All three models are widely studied in the machine learning literature. For each of these models, we rigorously prove that under suitable choices of hyperparameters, architectures, and initialization, the autoencoder weights learned by gradient descent % -based training can successfully recover the parameters of the corresponding model. To our knowledge, this is the first result that rigorously studies the dynamics of gradient descent for weight-sharing autoencoders. Our analysis can be viewed as theoretical evidence that shallow autoencoder modules indeed can be used as unsupervised feature training mechanisms for a wide range of datasets, and may shed insight on how to train larger stacked architectures with autoencoders as basic building blocks.
Matrix Completion with Noisy Entries and Outliers
Dec 27, 2017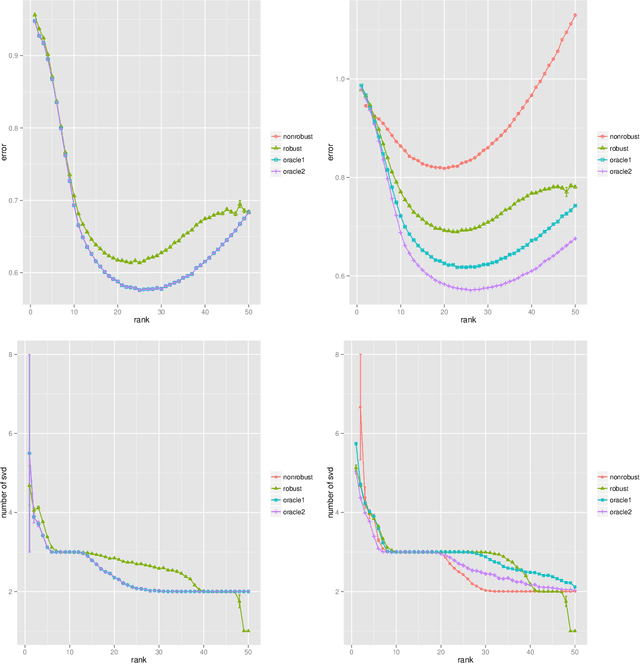


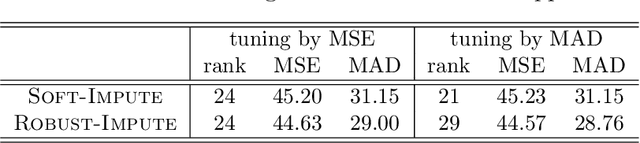
This paper considers the problem of matrix completion when the observed entries are noisy and contain outliers. It begins with introducing a new optimization criterion for which the recovered matrix is defined as its solution. This criterion uses the celebrated Huber function from the robust statistics literature to downweigh the effects of outliers. A practical algorithm is developed to solve the optimization involved. This algorithm is fast, straightforward to implement, and monotonic convergent. Furthermore, the proposed methodology is theoretically shown to be stable in a well defined sense. Its promising empirical performance is demonstrated via a sequence of simulation experiments, including image inpainting.
Provably Accurate Double-Sparse Coding
Dec 12, 2017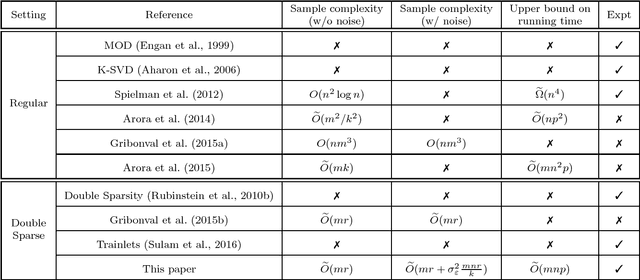
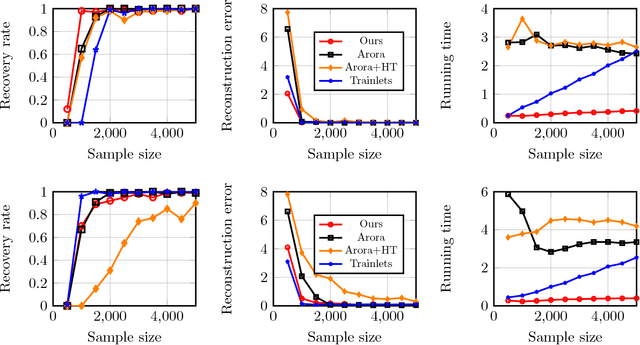
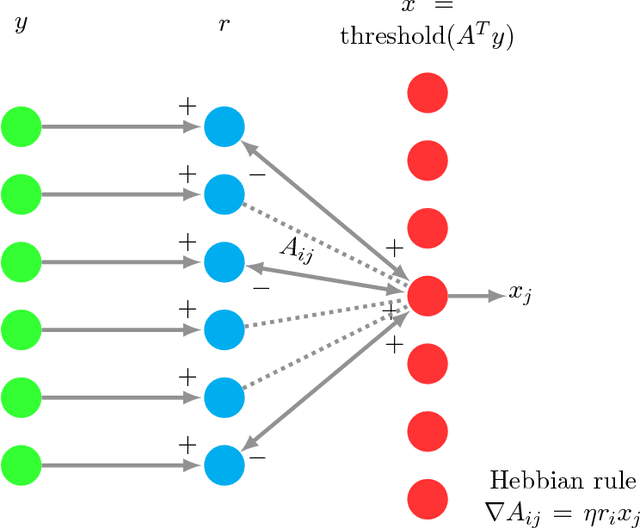
Sparse coding is a crucial subroutine in algorithms for various signal processing, deep learning, and other machine learning applications. The central goal is to learn an overcomplete dictionary that can sparsely represent a given input dataset. However, a key challenge is that storage, transmission, and processing of the learned dictionary can be untenably high if the data dimension is high. In this paper, we consider the double-sparsity model introduced by Rubinstein et al. (2010b) where the dictionary itself is the product of a fixed, known basis and a data-adaptive sparse component. First, we introduce a simple algorithm for double-sparse coding that can be amenable to efficient implementation via neural architectures. Second, we theoretically analyze its performance and demonstrate asymptotic sample complexity and running time benefits over existing (provable) approaches for sparse coding. To our knowledge, our work introduces the first computationally efficient algorithm for double-sparse coding that enjoys rigorous statistical guarantees. Finally, we support our analysis via several numerical experiments on simulated data, confirming that our method can indeed be useful in problem sizes encountered in practical applications.