 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Isotonic Regression
Oct 27, 2022In this paper, we consider the problem of differentially private (DP) algorithms for isotonic regression. For the most general problem of isotonic regression over a partially ordered set (poset) $\mathcal{X}$ and for any Lipschitz loss function, we obtain a pure-DP algorithm that, given $n$ input points, has an expected excess empirical risk of roughly $\mathrm{width}(\mathcal{X}) \cdot \log|\mathcal{X}| / n$, where $\mathrm{width}(\mathcal{X})$ is the width of the poset. In contrast, we also obtain a near-matching lower bound of roughly $(\mathrm{width}(\mathcal{X}) + \log |\mathcal{X}|) / n$, that holds even for approximate-DP algorithms. Moreover, we show that the above bounds are essentially the best that can be obtained without utilizing any further structure of the poset. In the special case of a totally ordered set and for $\ell_1$ and $\ell_2^2$ losses, our algorithm can be implemented in near-linear running time; we also provide extensions of this algorithm to the problem of private isotonic regression with additional structural constraints on the output function.
Anonymized Histograms in Intermediate Privacy Models
Oct 27, 2022We study the problem of privately computing the anonymized histogram (a.k.a. unattributed histogram), which is defined as the histogram without item labels. Previous works have provided algorithms with $\ell_1$- and $\ell_2^2$-errors of $O_\varepsilon(\sqrt{n})$ in the central model of differential privacy (DP). In this work, we provide an algorithm with a nearly matching error guarantee of $\tilde{O}_\varepsilon(\sqrt{n})$ in the shuffle DP and pan-private models. Our algorithm is very simple: it just post-processes the discrete Laplace-noised histogram! Using this algorithm as a subroutine, we show applications in privately estimating symmetric properties of distributions such as entropy, support coverage, and support size.
Algorithms with More Granular Differential Privacy Guarantees
Sep 08, 2022
Differential privacy is often applied with a privacy parameter that is larger than the theory suggests is ideal; various informal justifications for tolerating large privacy parameters have been proposed. In this work, we consider partial differential privacy (DP), which allows quantifying the privacy guarantee on a per-attribute basis. In this framework, we study several basic data analysis and learning tasks, and design algorithms whose per-attribute privacy parameter is smaller that the best possible privacy parameter for the entire record of a person (i.e., all the attributes).
Enhancement to Training of Bidirectional GAN : An Approach to Demystify Tax Fraud
Aug 16, 2022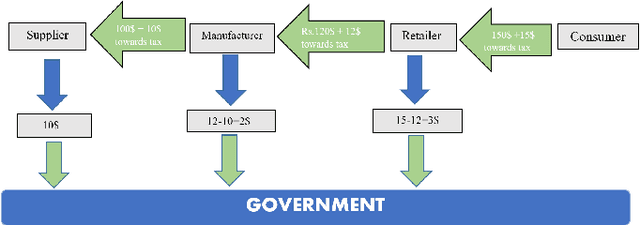
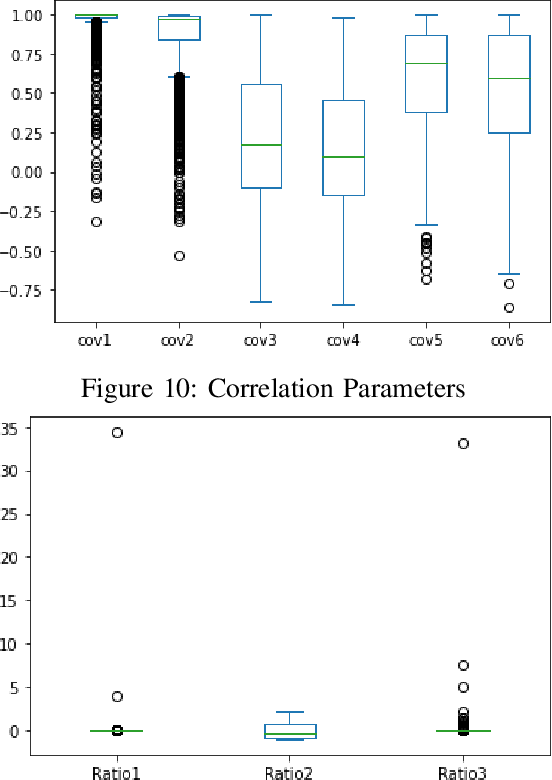
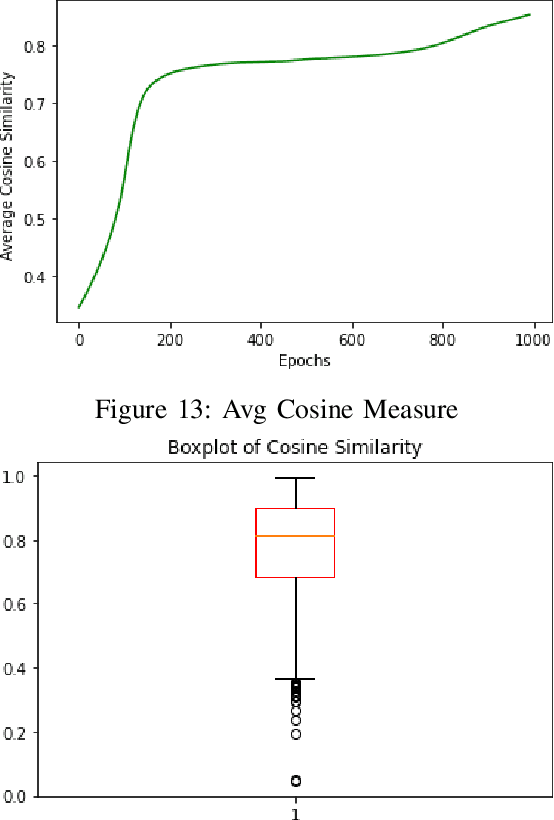
Outlier detection is a challenging activity. Several machine learning techniques are proposed in the literature for outlier detection. In this article, we propose a new training approach for bidirectional GAN (BiGAN) to detect outliers. To validate the proposed approach, we train a BiGAN with the proposed training approach to detect taxpayers, who are manipulating their tax returns. For each taxpayer, we derive six correlation parameters and three ratio parameters from tax returns submitted by him/her. We train a BiGAN with the proposed training approach on this nine-dimensional derived ground-truth data set. Next, we generate the latent representation of this data set using the $encoder$ (encode this data set using the $encoder$) and regenerate this data set using the $generator$ (decode back using the $generator$) by giving this latent representation as the input. For each taxpayer, compute the cosine similarity between his/her ground-truth data and regenerated data. Taxpayers with lower cosine similarity measures are potential return manipulators. We applied our method to analyze the iron and steel taxpayers data set provided by the Commercial Taxes Department, Government of Telangana, India.
Faster Privacy Accounting via Evolving Discretization
Jul 10, 2022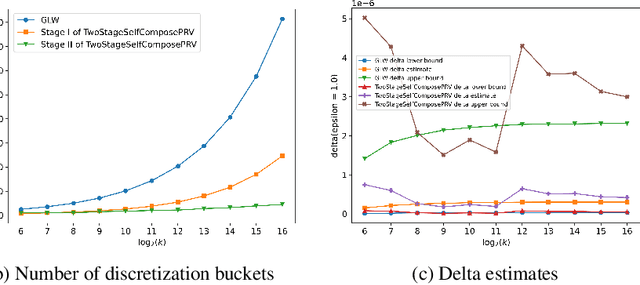
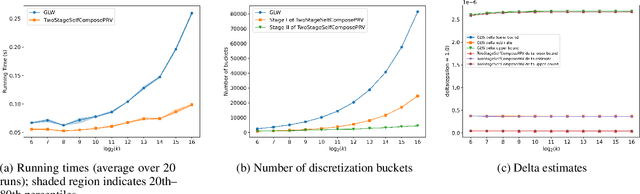
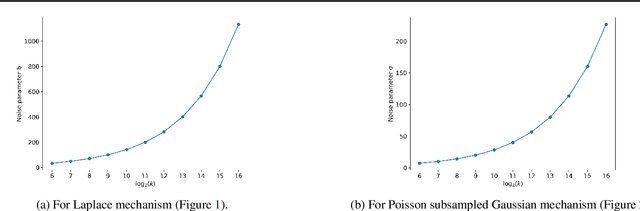
We introduce a new algorithm for numerical composition of privacy random variables, useful for computing the accurate differential privacy parameters for composition of mechanisms. Our algorithm achieves a running time and memory usage of $\mathrm{polylog}(k)$ for the task of self-composing a mechanism, from a broad class of mechanisms, $k$ times; this class, e.g., includes the sub-sampled Gaussian mechanism, that appears in the analysis of differentially private stochastic gradient descent. By comparison, recent work by Gopi et al. (NeurIPS 2021) has obtained a running time of $\widetilde{O}(\sqrt{k})$ for the same task. Our approach extends to the case of composing $k$ different mechanisms in the same class, improving upon their running time and memory usage from $\widetilde{O}(k^{1.5})$ to $\widetilde{O}(k)$.
Connect the Dots: Tighter Discrete Approximations of Privacy Loss Distributions
Jul 10, 2022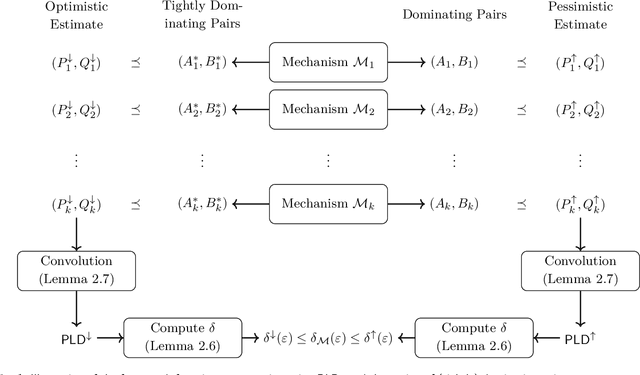
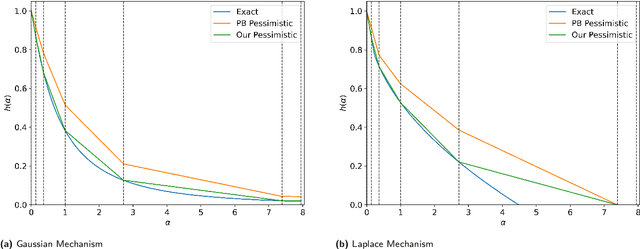
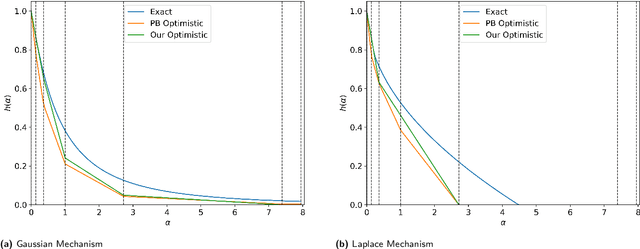
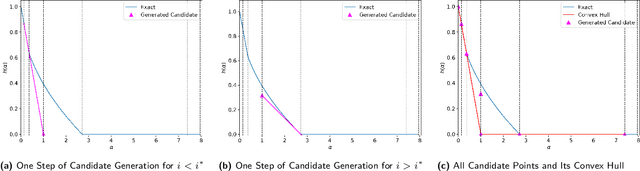
The privacy loss distribution (PLD) provides a tight characterization of the privacy loss of a mechanism in the context of differential privacy (DP). Recent work has shown that PLD-based accounting allows for tighter $(\varepsilon, \delta)$-DP guarantees for many popular mechanisms compared to other known methods. A key question in PLD-based accounting is how to approximate any (potentially continuous) PLD with a PLD over any specified discrete support. We present a novel approach to this problem. Our approach supports both pessimistic estimation, which overestimates the hockey-stick divergence (i.e., $\delta$) for any value of $\varepsilon$, and optimistic estimation, which underestimates the hockey-stick divergence. Moreover, we show that our pessimistic estimate is the best possible among all pessimistic estimates. Experimental evaluation shows that our approach can work with much larger discretization intervals while keeping a similar error bound compared to previous approaches and yet give a better approximation than existing methods.
Machine Learning based Framework for Robust Price-Sensitivity Estimation with Application to Airline Pricing
May 04, 2022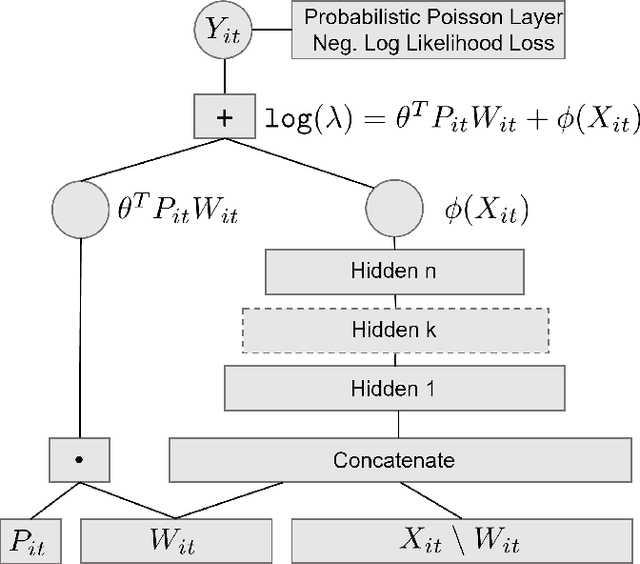
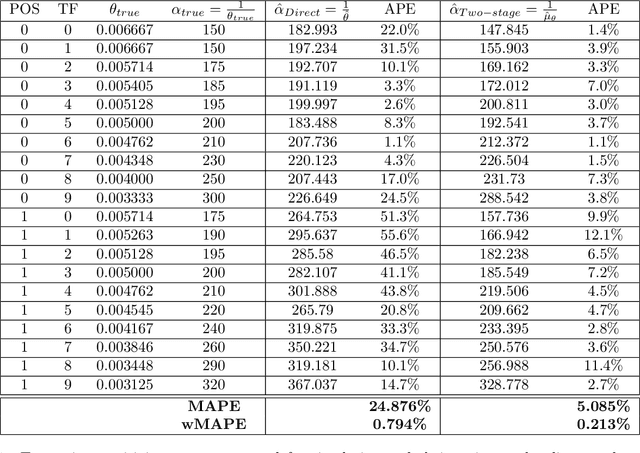
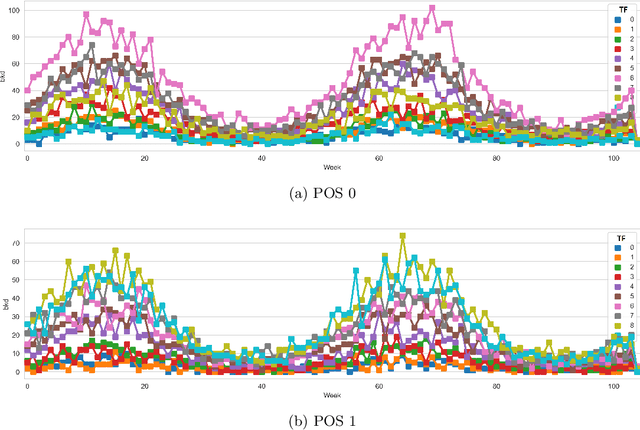
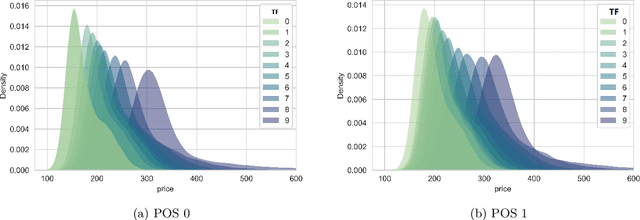
We consider the problem of dynamic pricing of a product in the presence of feature-dependent price sensitivity. Based on the Poisson semi-parametric approach, we construct a flexible yet interpretable demand model where the price related part is parametric while the remaining (nuisance) part of the model is non-parametric and can be modeled via sophisticated ML techniques. The estimation of price-sensitivity parameters of this model via direct one-stage regression techniques may lead to biased estimates. We propose a two-stage estimation methodology which makes the estimation of the price-sensitivity parameters robust to biases in the nuisance parameters of the model. In the first-stage we construct the estimators of observed purchases and price given the feature vector using sophisticated ML estimators like deep neural networks. Utilizing the estimators from the first-stage, in the second-stage we leverage a Bayesian dynamic generalized linear model to estimate the price-sensitivity parameters. We test the performance of the proposed estimation schemes on simulated and real sales transaction data from Airline industry. Our numerical studies demonstrate that the two-stage approach provides more accurate estimates of price-sensitivity parameters as compared to direct one-stage approach.
Parsimonious Learning-Augmented Caching
Feb 09, 2022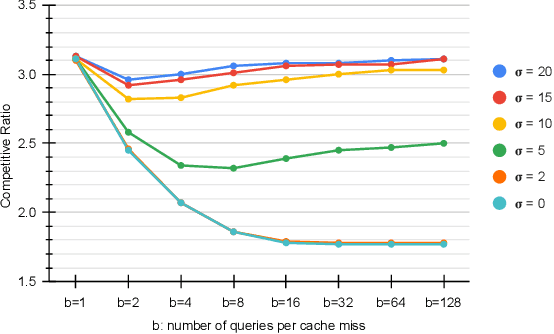
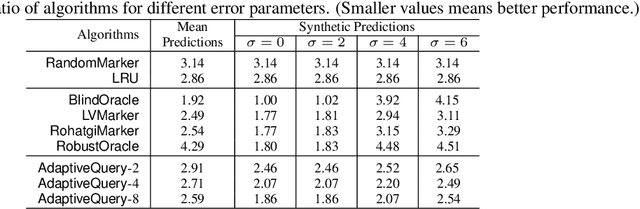
Learning-augmented algorithms -- in which, traditional algorithms are augmented with machine-learned predictions -- have emerged as a framework to go beyond worst-case analysis. The overarching goal is to design algorithms that perform near-optimally when the predictions are accurate yet retain certain worst-case guarantees irrespective of the accuracy of the predictions. This framework has been successfully applied to online problems such as caching where the predictions can be used to alleviate uncertainties. In this paper we introduce and study the setting in which the learning-augmented algorithm can utilize the predictions parsimoniously. We consider the caching problem -- which has been extensively studied in the learning-augmented setting -- and show that one can achieve quantitatively similar results but only using a sublinear number of predictions.
Logarithmic Regret from Sublinear Hints
Nov 09, 2021We consider the online linear optimization problem, where at every step the algorithm plays a point $x_t$ in the unit ball, and suffers loss $\langle c_t, x_t\rangle$ for some cost vector $c_t$ that is then revealed to the algorithm. Recent work showed that if an algorithm receives a hint $h_t$ that has non-trivial correlation with $c_t$ before it plays $x_t$, then it can achieve a regret guarantee of $O(\log T)$, improving on the bound of $\Theta(\sqrt{T})$ in the standard setting. In this work, we study the question of whether an algorithm really requires a hint at every time step. Somewhat surprisingly, we show that an algorithm can obtain $O(\log T)$ regret with just $O(\sqrt{T})$ hints under a natural query model; in contrast, we also show that $o(\sqrt{T})$ hints cannot guarantee better than $\Omega(\sqrt{T})$ regret. We give two applications of our result, to the well-studied setting of optimistic regret bounds and to the problem of online learning with abstention.
User-Level Private Learning via Correlated Sampling
Oct 21, 2021
Most works in learning with differential privacy (DP) have focused on the setting where each user has a single sample. In this work, we consider the setting where each user holds $m$ samples and the privacy protection is enforced at the level of each user's data. We show that, in this setting, we may learn with a much fewer number of users. Specifically, we show that, as long as each user receives sufficiently many samples, we can learn any privately learnable class via an $(\epsilon, \delta)$-DP algorithm using only $O(\log(1/\delta)/\epsilon)$ users. For $\epsilon$-DP algorithms, we show that we can learn using only $O_{\epsilon}(d)$ users even in the local model, where $d$ is the probabilistic representation dimension. In both cases, we show a nearly-matching lower bound on the number of users required. A crucial component of our results is a generalization of global stability [Bun et al., FOCS 2020] that allows the use of public randomness. Under this relaxed notion, we employ a correlated sampling strategy to show that the global stability can be boosted to be arbitrarily close to one, at a polynomial expense in the number of samples.