Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Hierarchical Clustering
Paper and Code
Jun 19, 2020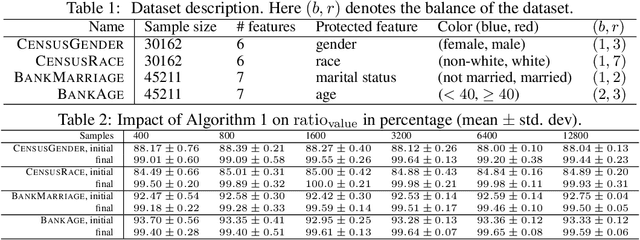
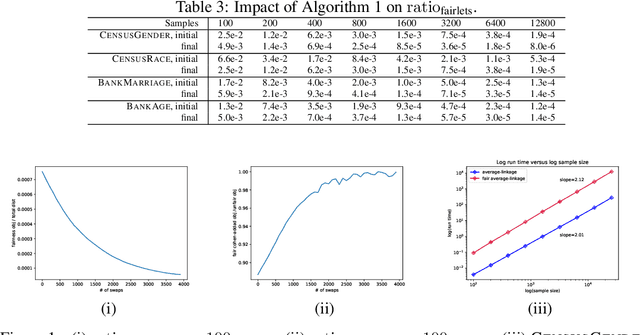
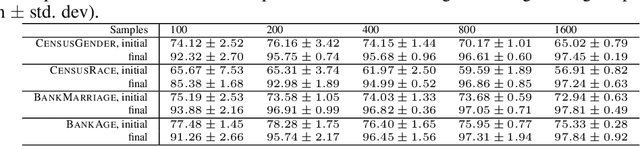

As machine learning has become more prevalent, researchers have begun to recognize the necessity of ensuring machine learning systems are fair. Recently, there has been an interest in defining a notion of fairness that mitigates over-representation in traditional clustering. In this paper we extend this notion to hierarchical clustering, where the goal is to recursively partition the data to optimize a specific objective. For various natural objectives, we obtain simple, efficient algorithms to find a provably good fair hierarchical clustering. Empirically, we show that our algorithms can find a fair hierarchical clustering, with only a negligible loss in the objective.
View paper on