 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Face Recognition from Part of a Facial Image based on Image Stitching
Mar 10, 2022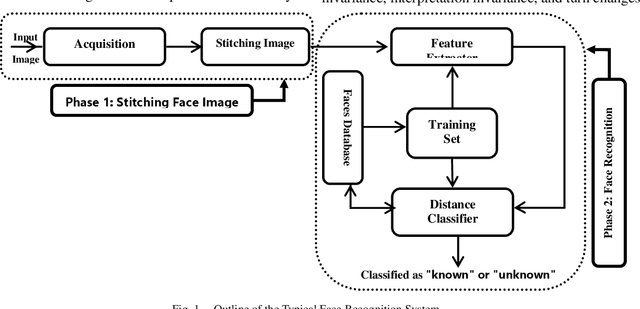
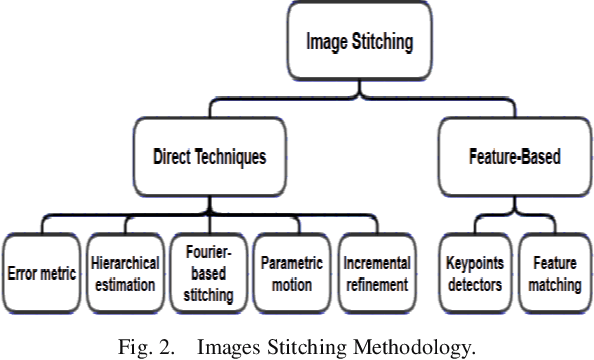


Most of the current techniques for face recognition require the presence of a full face of the person to be recognized, and this situation is difficult to achieve in practice, the required person may appear with a part of his face, which requires prediction of the part that did not appear. Most of the current forecasting processes are done by what is known as image interpolation, which does not give reliable results, especially if the missing part is large. In this work, we adopted the process of stitching the face by completing the missing part with the flipping of the part shown in the picture, depending on the fact that the human face is characterized by symmetry in most cases. To create a complete model, two facial recognition methods were used to prove the efficiency of the algorithm. The selected face recognition algorithms that are applied here are Eigenfaces and geometrical methods. Image stitching is the process during which distinctive photographic images are combined to make a complete scene or a high-resolution image. Several images are integrated to form a wide-angle panoramic image. The quality of the image stitching is determined by calculating the similarity among the stitched image and original images and by the presence of the seam lines through the stitched images. The Eigenfaces approach utilizes PCA calculation to reduce the feature vector dimensions. It provides an effective approach for discovering the lower-dimensional space. In addition, to enable the proposed algorithm to recognize the face, it also ensures a fast and effective way of classifying faces. The phase of feature extraction is followed by the classifier phase.
Real Time Monitoring and Control of Neonatal Incubator using IOT
Nov 27, 2021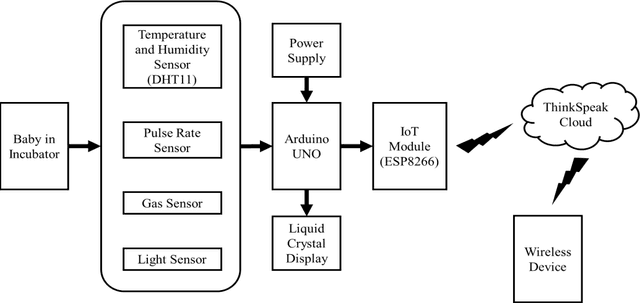
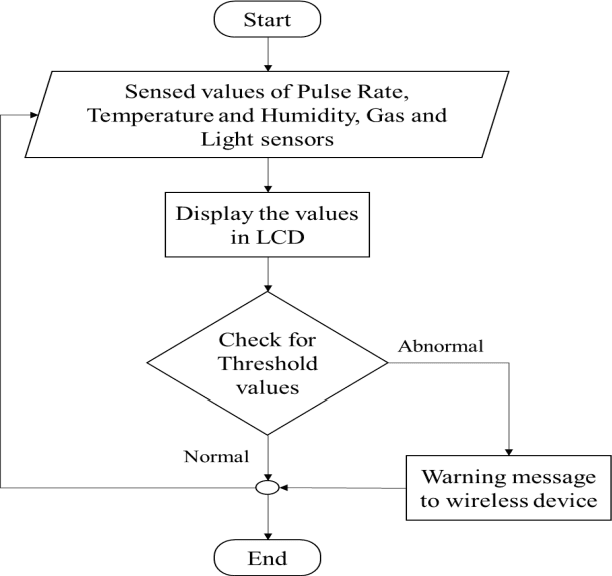
The care of new born babies are the most important and sensitive part of bio-medical domain. Some new born babies have a higher risk of mortality due to their gestational age or their birth weight. Most of the premature babies born on 32-37 weeks of gestation and are deceased due to their unmet need for warmth. The neonatal incubator is a device used to nourish the premature babies by providing a controlled and closed environment. This incubator provides the babies with optimum temperature, relative humidity, optimum light and appropriate level of oxygen which are same as that in the womb. But babies in the incubators have a risk of losing those babies lives due to the improper monitoring of the it which causes accidents like gas leakage and short circuits due to overheating which leads to bursting of incubators. Thus, the objective of this paper is to overcome the drawbacks of an unmonitored incubator and develops an affordable and safe device for real-time monitoring of the neonatal incubator. a low cost yet effective apparatus for monitoring the important parameters like pulse rate, temperature, humidity, gas and light of the premature baby inside an incubator. The sensed data are passed to the doctors or nurses wirelessly by the Arduino UNO via Internet of Things (IoT) so as to take necessary actions at times to maintain an appropriate environment for the safety of the lives of premature babies.
An Effective Evolutionary Clustering Algorithm: Hepatitis C Case Study
Feb 27, 2014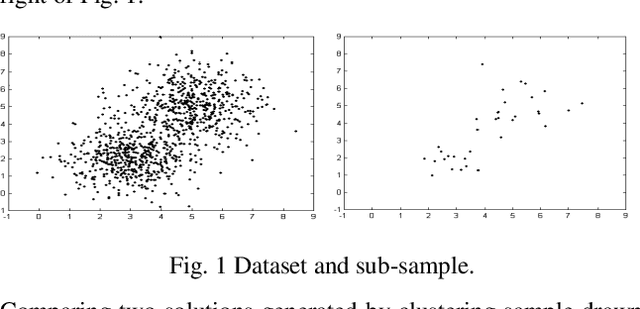
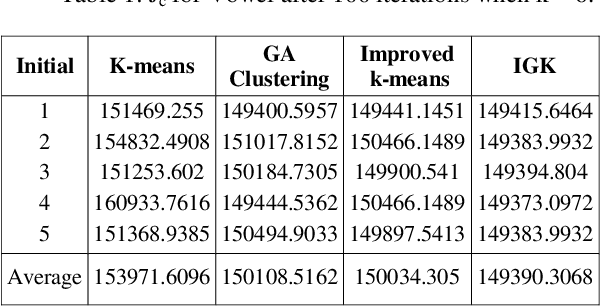
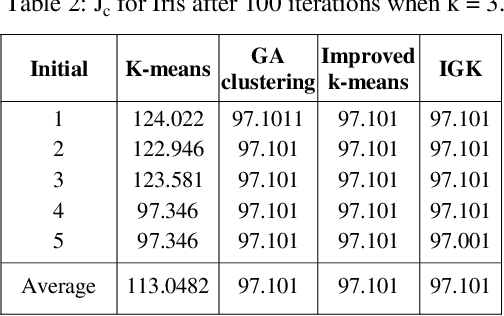

Clustering analysis plays an important role in scientific research and commercial application. K-means algorithm is a widely used partition method in clustering. However, it is known that the K-means algorithm may get stuck at suboptimal solutions, depending on the choice of the initial cluster centers. In this article, we propose a technique to handle large scale data, which can select initial clustering center purposefully using Genetic algorithms (GAs), reduce the sensitivity to isolated point, avoid dissevering big cluster, and overcome deflexion of data in some degree that caused by the disproportion in data partitioning owing to adoption of multi-sampling. We applied our method to some public datasets these show the advantages of the proposed approach for example Hepatitis C dataset that has been taken from the machine learning warehouse of University of California. Our aim is to evaluate hepatitis dataset. In order to evaluate this dataset we did some preprocessing operation, the reason to preprocessing is to summarize the data in the best and suitable way for our algorithm. Missing values of the instances are adjusted using local mean method.