 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGesture based Arabic Sign Language Recognition for Impaired People based on Convolution Neural Network
Mar 10, 2022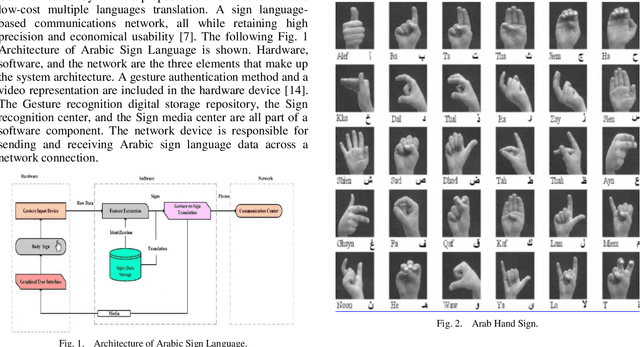
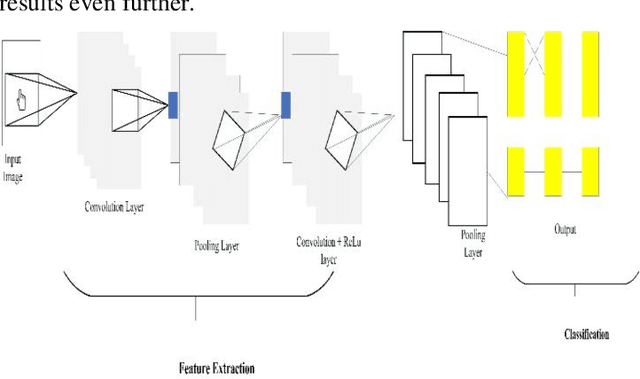
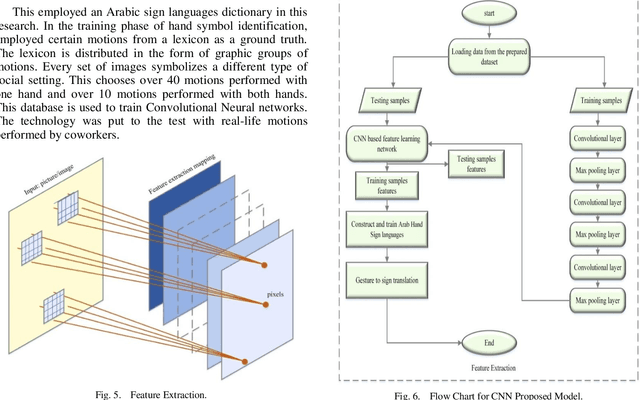
The Arabic Sign Language has endorsed outstanding research achievements for identifying gestures and hand signs using the deep learning methodology. The term "forms of communication" refers to the actions used by hearing-impaired people to communicate. These actions are difficult for ordinary people to comprehend. The recognition of Arabic Sign Language (ArSL) has become a difficult study subject due to variations in Arabic Sign Language (ArSL) from one territory to another and then within states. The Convolution Neural Network has been encapsulated in the proposed system which is based on the machine learning technique. For the recognition of the Arabic Sign Language, the wearable sensor is utilized. This approach has been used a different system that could suit all Arabic gestures. This could be used by the impaired people of the local Arabic community. The research method has been used with reasonable and moderate accuracy. A deep Convolutional network is initially developed for feature extraction from the data gathered by the sensing devices. These sensors can reliably recognize the Arabic sign language's 30 hand sign letters. The hand movements in the dataset were captured using DG5-V hand gloves with wearable sensors. For categorization purposes, the CNN technique is used. The suggested system takes Arabic sign language hand gestures as input and outputs vocalized speech as output. The results were recognized by 90% of the people.
Human Face Recognition from Part of a Facial Image based on Image Stitching
Mar 10, 2022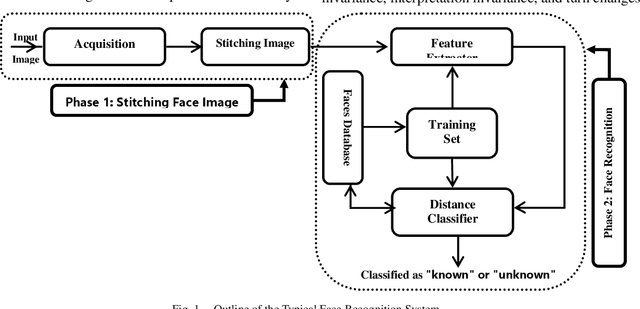
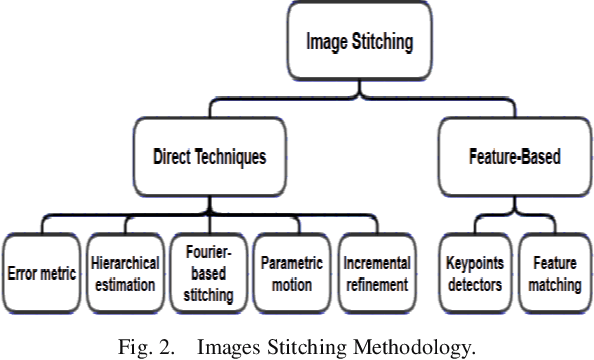


Most of the current techniques for face recognition require the presence of a full face of the person to be recognized, and this situation is difficult to achieve in practice, the required person may appear with a part of his face, which requires prediction of the part that did not appear. Most of the current forecasting processes are done by what is known as image interpolation, which does not give reliable results, especially if the missing part is large. In this work, we adopted the process of stitching the face by completing the missing part with the flipping of the part shown in the picture, depending on the fact that the human face is characterized by symmetry in most cases. To create a complete model, two facial recognition methods were used to prove the efficiency of the algorithm. The selected face recognition algorithms that are applied here are Eigenfaces and geometrical methods. Image stitching is the process during which distinctive photographic images are combined to make a complete scene or a high-resolution image. Several images are integrated to form a wide-angle panoramic image. The quality of the image stitching is determined by calculating the similarity among the stitched image and original images and by the presence of the seam lines through the stitched images. The Eigenfaces approach utilizes PCA calculation to reduce the feature vector dimensions. It provides an effective approach for discovering the lower-dimensional space. In addition, to enable the proposed algorithm to recognize the face, it also ensures a fast and effective way of classifying faces. The phase of feature extraction is followed by the classifier phase.
A Predictive Model for Student Performance in Classrooms Using Student Interactions With an eTextbook
Feb 16, 2022
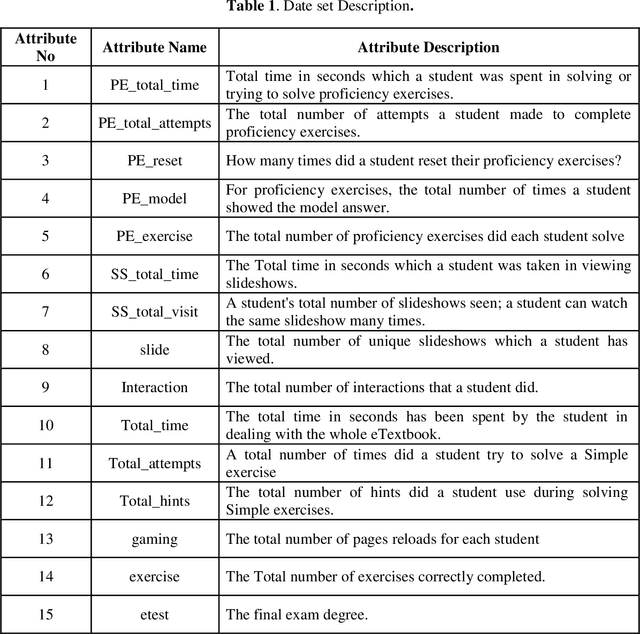
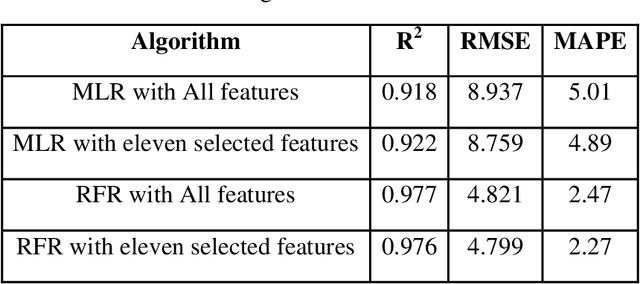
With the rise of online eTextbooks and Massive Open Online Courses (MOOCs), a huge amount of data has been collected related to students' learning. With the careful analysis of this data, educators can gain useful insights into the performance of their students and their behavior in learning a particular topic. This paper proposes a new model for predicting student performance based on an analysis of how students interact with an interactive online eTextbook. By being able to predict students' performance early in the course, educators can easily identify students at risk and provide a suitable intervention. We considered two main issues the prediction of good/bad performance and the prediction of the final exam grade. To build the proposed model, we evaluated the most popular classification and regression algorithms on data from a data structures and algorithms course (CS2) offered in a large public research university. Random Forest Regression and Multiple Linear Regression have been applied in Regression. While Logistic Regression, decision tree, Random Forest Classifier, K Nearest Neighbors, and Support Vector Machine have been applied in classification.
Real Time Monitoring and Control of Neonatal Incubator using IOT
Nov 27, 2021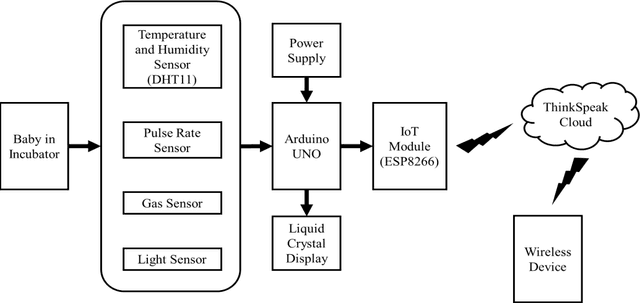
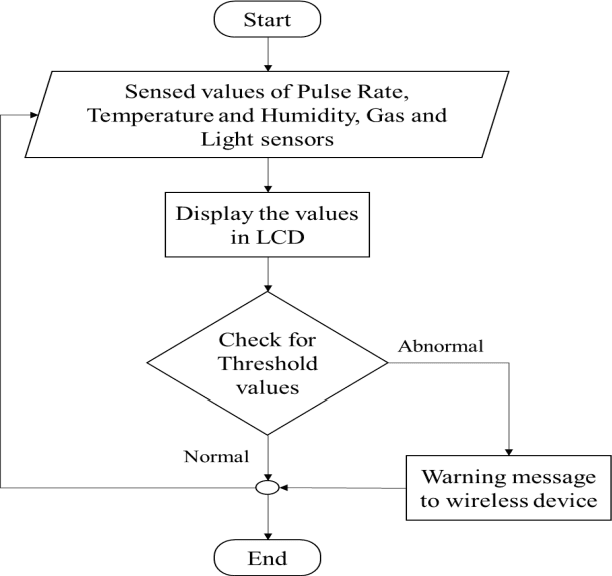
The care of new born babies are the most important and sensitive part of bio-medical domain. Some new born babies have a higher risk of mortality due to their gestational age or their birth weight. Most of the premature babies born on 32-37 weeks of gestation and are deceased due to their unmet need for warmth. The neonatal incubator is a device used to nourish the premature babies by providing a controlled and closed environment. This incubator provides the babies with optimum temperature, relative humidity, optimum light and appropriate level of oxygen which are same as that in the womb. But babies in the incubators have a risk of losing those babies lives due to the improper monitoring of the it which causes accidents like gas leakage and short circuits due to overheating which leads to bursting of incubators. Thus, the objective of this paper is to overcome the drawbacks of an unmonitored incubator and develops an affordable and safe device for real-time monitoring of the neonatal incubator. a low cost yet effective apparatus for monitoring the important parameters like pulse rate, temperature, humidity, gas and light of the premature baby inside an incubator. The sensed data are passed to the doctors or nurses wirelessly by the Arduino UNO via Internet of Things (IoT) so as to take necessary actions at times to maintain an appropriate environment for the safety of the lives of premature babies.
Arabic aspect based sentiment analysis using bidirectional GRU based models
Feb 18, 2021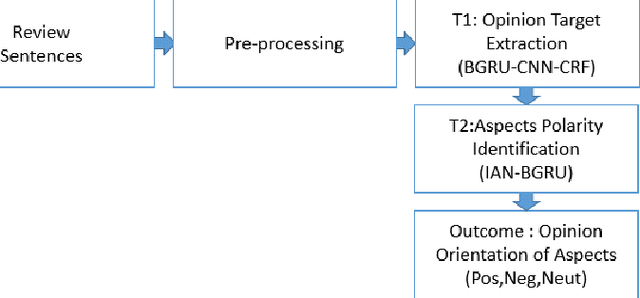

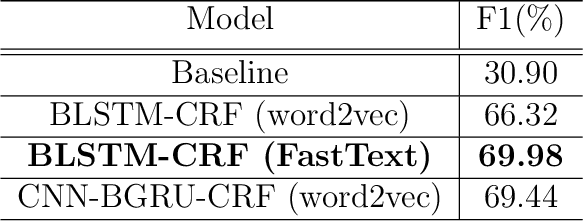
Aspect-based Sentiment analysis (ABSA) accomplishes a fine-grained analysis that defines the aspects of a given document or sentence and the sentiments conveyed regarding each aspect. This level of analysis is the most detailed version that is capable of exploring the nuanced viewpoints of the reviews. Most of the research available in ABSA focuses on English language with very few work available on Arabic. Most previous work in Arabic has been based on regular methods of machine learning that mainly depends on a group of rare resources and tools for analyzing and processing Arabic content such as lexicons, but the lack of those resources presents another challenge. To overcome these obstacles, Deep Learning (DL)-based methods are proposed using two models based on Gated Recurrent Units (GRU) neural networks for ABSA. The first one is a DL model that takes advantage of the representations on both words and characters via the combination of bidirectional GRU, Convolutional neural network (CNN), and Conditional Random Field (CRF) which makes up (BGRU-CNN-CRF) model to extract the main opinionated aspects (OTE). The second is an interactive attention network based on bidirectional GRU (IAN-BGRU) to identify sentiment polarity toward extracted aspects. We evaluated our models using the benchmarked Arabic hotel reviews dataset. The results indicate that the proposed methods are better than baseline research on both tasks having 38.5% enhancement in F1-score for opinion target extraction (T2) and 7.5% in accuracy for aspect-based sentiment polarity classification (T3). Obtaining F1 score of 69.44% for T2, and accuracy of 83.98% for T3.
A Comparative Study on using Principle Component Analysis with Different Text Classifiers
Jul 04, 2018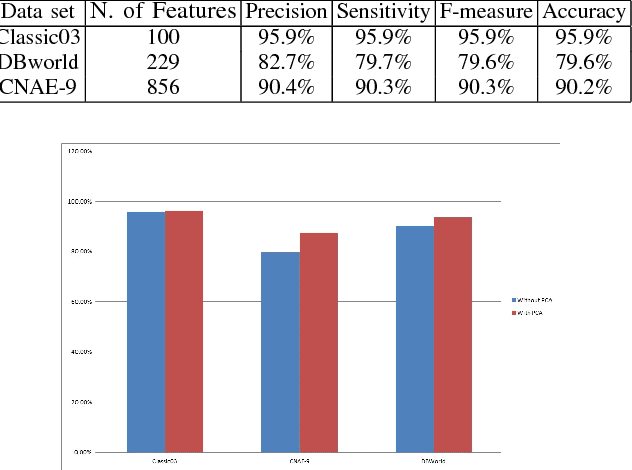
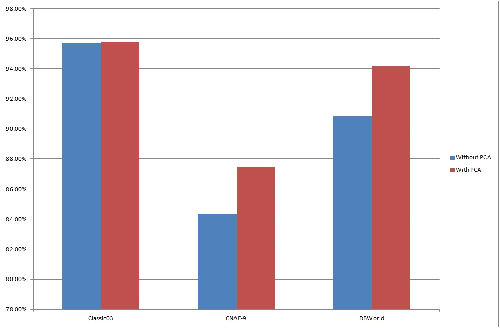
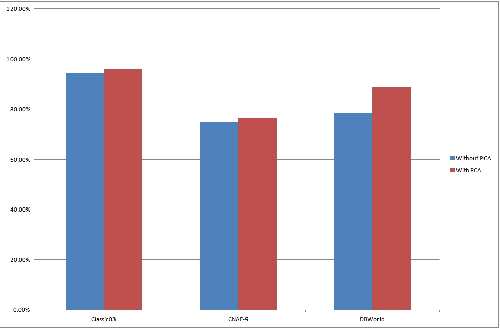
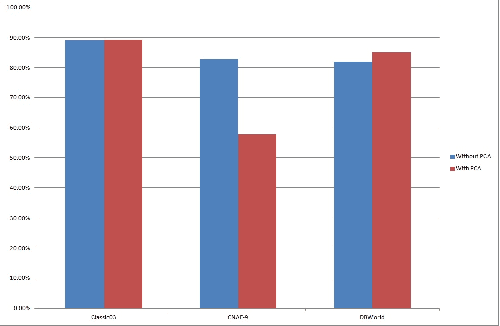
Text categorization (TC) is the task of automatically organizing a set of documents into a set of pre-defined categories. Over the last few years, increased attention has been paid to the use of documents in digital form and this makes text categorization becomes a challenging issue. The most significant problem of text categorization is its huge number of features. Most of these features are redundant, noisy and irrelevant that cause over fitting with most of the classifiers. Hence, feature extraction is an important step to improve the overall accuracy and the performance of the text classifiers. In this paper, we will provide an overview of using principle component analysis (PCA) as a feature extraction with various classifiers. It was observed that the performance rate of the classifiers after using PCA to reduce the dimension of data improved. Experiments are conducted on three UCI data sets, Classic03, CNAE-9 and DBWorld e-mails. We compare the classification performance results of using PCA with popular and well-known text classifiers. Results show that using PCA encouragingly enhances classification performance on most of the classifiers.
Differential Search Algorithm-based Parametric Optimization of Fuzzy Generalized Eigenvalue Proximal Support Vector Machine
Jan 04, 2015
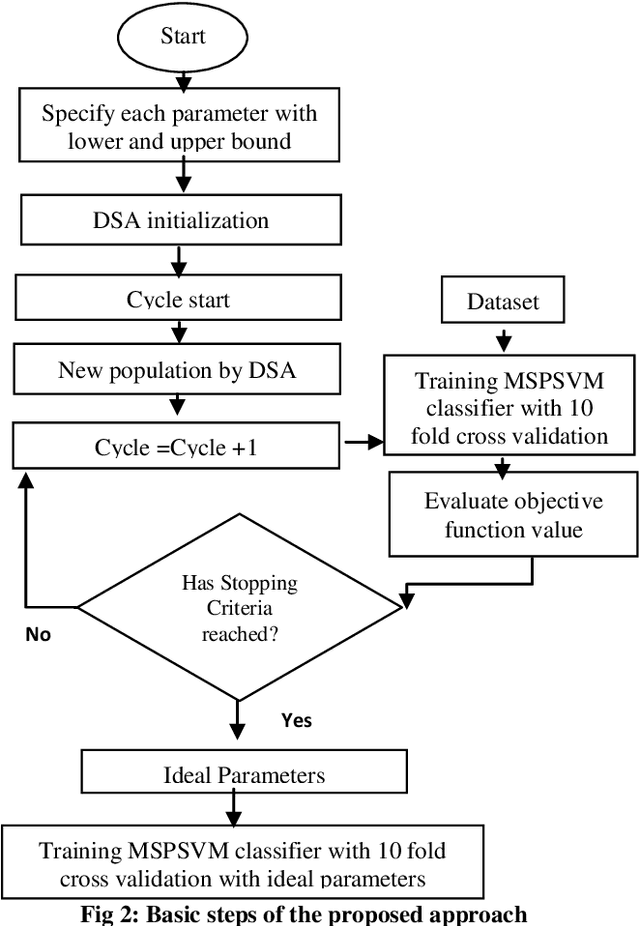
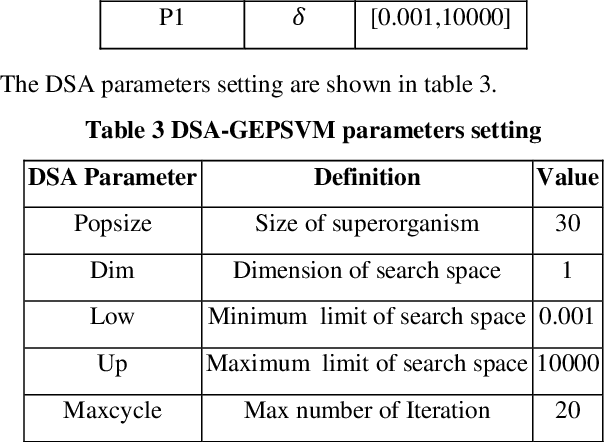
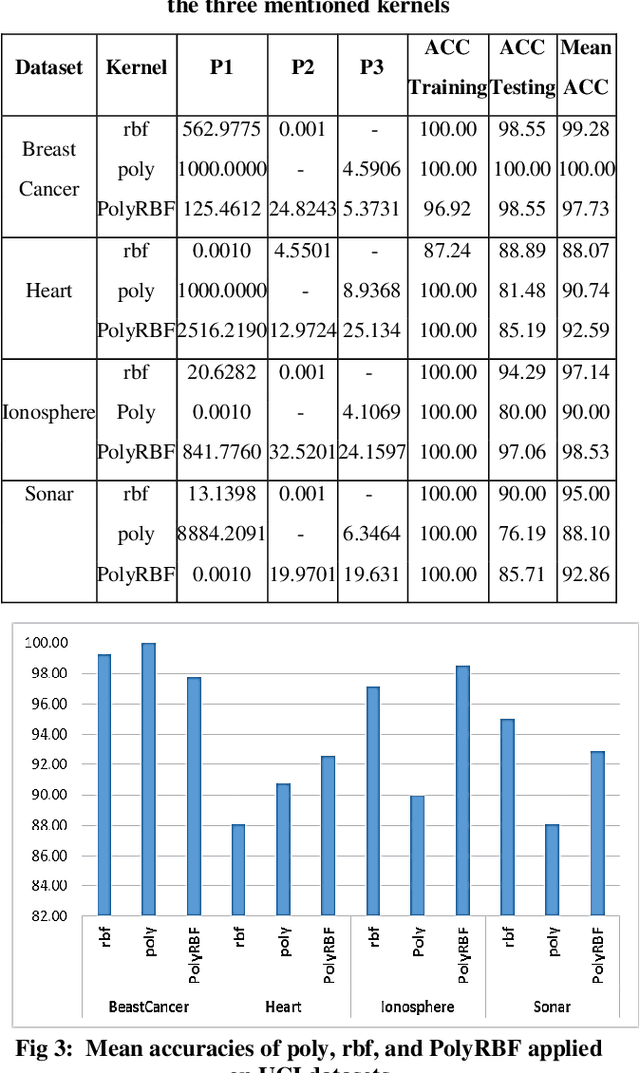
Support Vector Machine (SVM) is an effective model for many classification problems. However, SVM needs the solution of a quadratic program which require specialized code. In addition, SVM has many parameters, which affects the performance of SVM classifier. Recently, the Generalized Eigenvalue Proximal SVM (GEPSVM) has been presented to solve the SVM complexity. In real world applications data may affected by error or noise, working with this data is a challenging problem. In this paper, an approach has been proposed to overcome this problem. This method is called DSA-GEPSVM. The main improvements are carried out based on the following: 1) a novel fuzzy values in the linear case. 2) A new Kernel function in the nonlinear case. 3) Differential Search Algorithm (DSA) is reformulated to find near optimal values of the GEPSVM parameters and its kernel parameters. The experimental results show that the proposed approach is able to find the suitable parameter values, and has higher classification accuracy compared with some other algorithms.
Outlier Detection using Improved Genetic K-means
Feb 27, 2014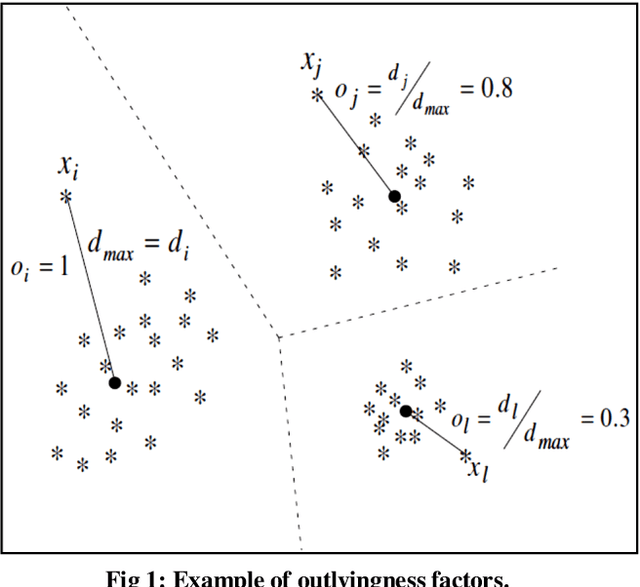
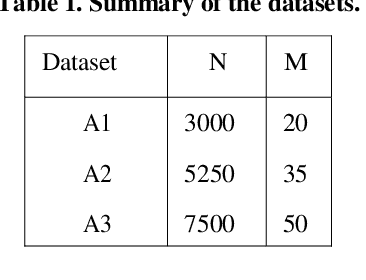
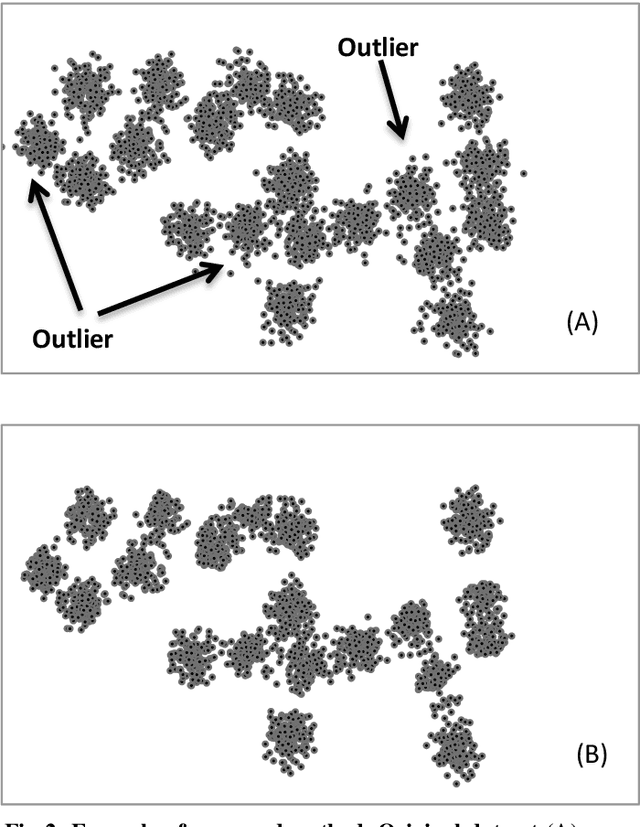
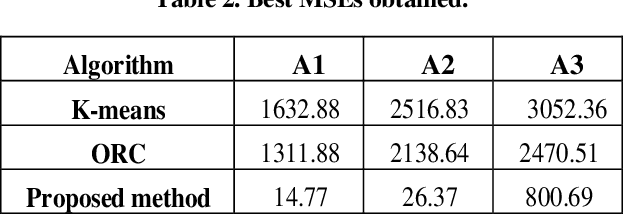
The outlier detection problem in some cases is similar to the classification problem. For example, the main concern of clustering-based outlier detection algorithms is to find clusters and outliers, which are often regarded as noise that should be removed in order to make more reliable clustering. In this article, we present an algorithm that provides outlier detection and data clustering simultaneously. The algorithmimprovesthe estimation of centroids of the generative distribution during the process of clustering and outlier discovery. The proposed algorithm consists of two stages. The first stage consists of improved genetic k-means algorithm (IGK) process, while the second stage iteratively removes the vectors which are far from their cluster centroids.
An Effective Evolutionary Clustering Algorithm: Hepatitis C Case Study
Feb 27, 2014
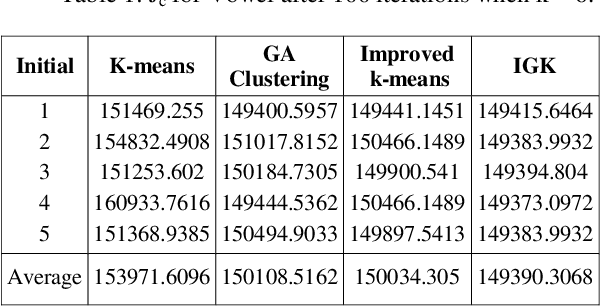
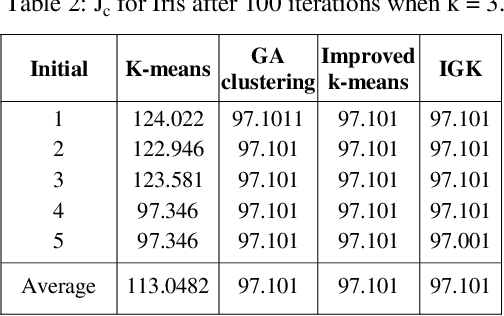

Clustering analysis plays an important role in scientific research and commercial application. K-means algorithm is a widely used partition method in clustering. However, it is known that the K-means algorithm may get stuck at suboptimal solutions, depending on the choice of the initial cluster centers. In this article, we propose a technique to handle large scale data, which can select initial clustering center purposefully using Genetic algorithms (GAs), reduce the sensitivity to isolated point, avoid dissevering big cluster, and overcome deflexion of data in some degree that caused by the disproportion in data partitioning owing to adoption of multi-sampling. We applied our method to some public datasets these show the advantages of the proposed approach for example Hepatitis C dataset that has been taken from the machine learning warehouse of University of California. Our aim is to evaluate hepatitis dataset. In order to evaluate this dataset we did some preprocessing operation, the reason to preprocessing is to summarize the data in the best and suitable way for our algorithm. Missing values of the instances are adjusted using local mean method.