 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapidly Bootstrapping a Question Answering Dataset for COVID-19
Apr 23, 2020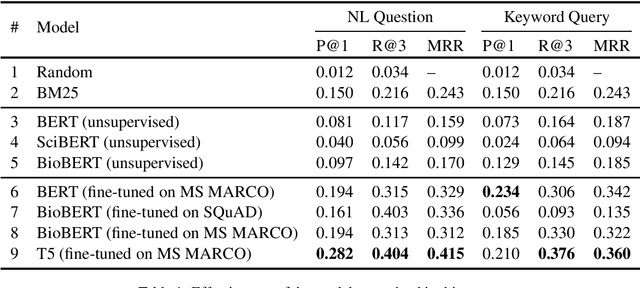
We present CovidQA, the beginnings of a question answering dataset specifically designed for COVID-19, built by hand from knowledge gathered from Kaggle's COVID-19 Open Research Dataset Challenge. To our knowledge, this is the first publicly available resource of its type, and intended as a stopgap measure for guiding research until more substantial evaluation resources become available. While this dataset, comprising 124 question-article pairs as of the present version 0.1 release, does not have sufficient examples for supervised machine learning, we believe that it can be helpful for evaluating the zero-shot or transfer capabilities of existing models on topics specifically related to COVID-19. This paper describes our methodology for constructing the dataset and presents the effectiveness of a number of baselines, including term-based techniques and various transformer-based models. The dataset is available at http://covidqa.ai/
What Would Elsa Do? Freezing Layers During Transformer Fine-Tuning
Nov 08, 2019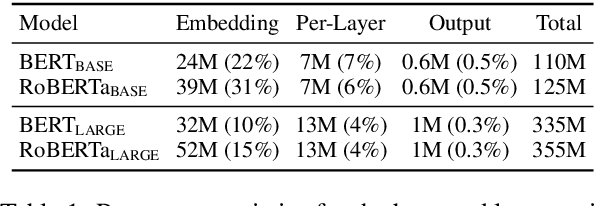
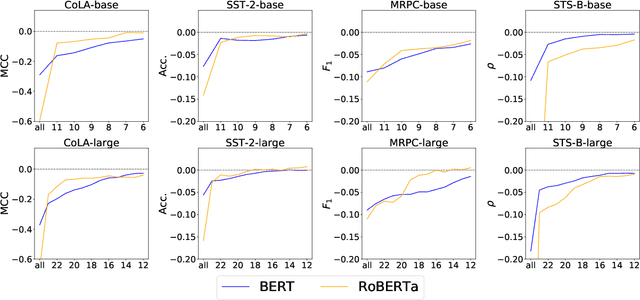
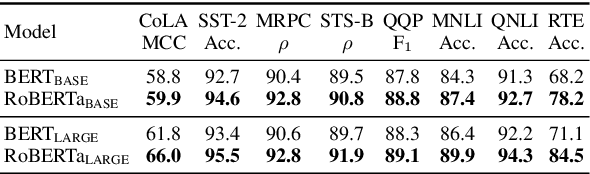
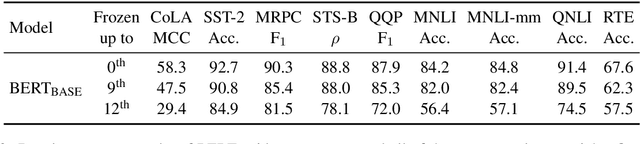
Pretrained transformer-based language models have achieved state of the art across countless tasks in natural language processing. These models are highly expressive, comprising at least a hundred million parameters and a dozen layers. Recent evidence suggests that only a few of the final layers need to be fine-tuned for high quality on downstream tasks. Naturally, a subsequent research question is, "how many of the last layers do we need to fine-tune?" In this paper, we precisely answer this question. We examine two recent pretrained language models, BERT and RoBERTa, across standard tasks in textual entailment, semantic similarity, sentiment analysis, and linguistic acceptability. We vary the number of final layers that are fine-tuned, then study the resulting change in task-specific effectiveness. We show that only a fourth of the final layers need to be fine-tuned to achieve 90% of the original quality. Surprisingly, we also find that fine-tuning all layers does not always help.
Explicit Pairwise Word Interaction Modeling Improves Pretrained Transformers for English Semantic Similarity Tasks
Nov 07, 2019
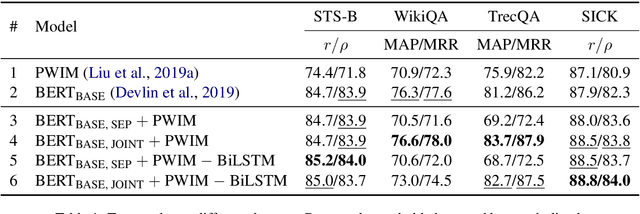
In English semantic similarity tasks, classic word embedding-based approaches explicitly model pairwise "interactions" between the word representations of a sentence pair. Transformer-based pretrained language models disregard this notion, instead modeling pairwise word interactions globally and implicitly through their self-attention mechanism. In this paper, we hypothesize that introducing an explicit, constrained pairwise word interaction mechanism to pretrained language models improves their effectiveness on semantic similarity tasks. We validate our hypothesis using BERT on four tasks in semantic textual similarity and answer sentence selection. We demonstrate consistent improvements in quality by adding an explicit pairwise word interaction module to BERT.
DocBERT: BERT for Document Classification
Apr 17, 2019
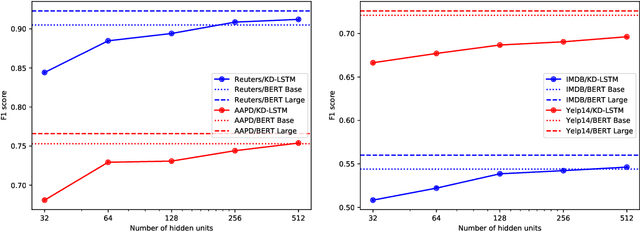
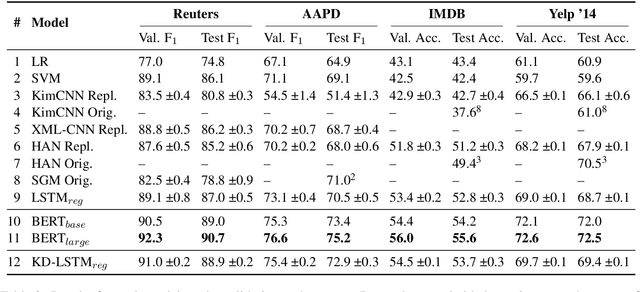
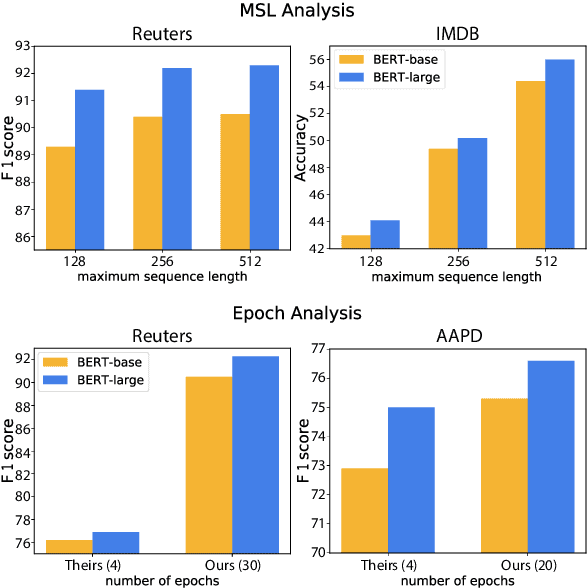
Pre-trained language representation models achieve remarkable state of the art across a wide range of tasks in natural language processing. One of the latest advancements is BERT, a deep pre-trained transformer that yields much better results than its predecessors do. Despite its burgeoning popularity, however, BERT has not yet been applied to document classification. This task deserves attention, since it contains a few nuances: first, modeling syntactic structure matters less for document classification than for other problems, such as natural language inference and sentiment classification. Second, documents often have multiple labels across dozens of classes, which is uncharacteristic of the tasks that BERT explores. In this paper, we describe fine-tuning BERT for document classification. We are the first to demonstrate the success of BERT on this task, achieving state of the art across four popular datasets.
Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
Mar 28, 2019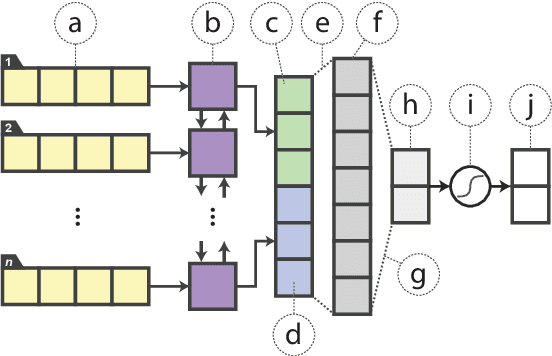
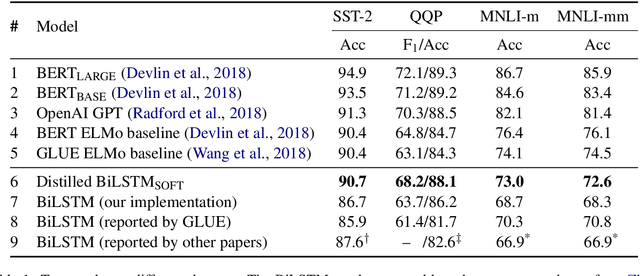
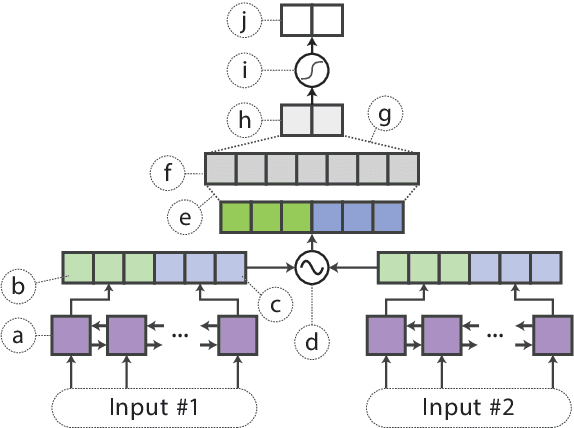
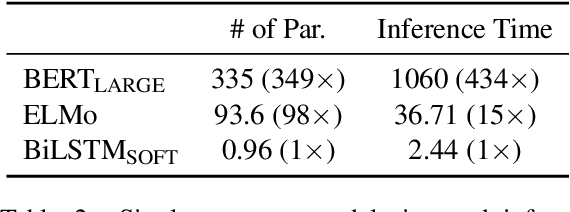
In the natural language processing literature, neural networks are becoming increasingly deeper and complex. The recent poster child of this trend is the deep language representation model, which includes BERT, ELMo, and GPT. These developments have led to the conviction that previous-generation, shallower neural networks for language understanding are obsolete. In this paper, however, we demonstrate that rudimentary, lightweight neural networks can still be made competitive without architecture changes, external training data, or additional input features. We propose to distill knowledge from BERT, a state-of-the-art language representation model, into a single-layer BiLSTM, as well as its siamese counterpart for sentence-pair tasks. Across multiple datasets in paraphrasing, natural language inference, and sentiment classification, we achieve comparable results with ELMo, while using roughly 100 times fewer parameters and 15 times less inference time.
Streaming Voice Query Recognition using Causal Convolutional Recurrent Neural Networks
Dec 19, 2018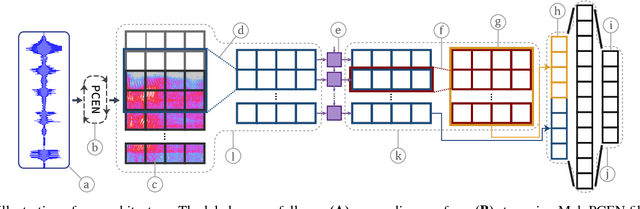
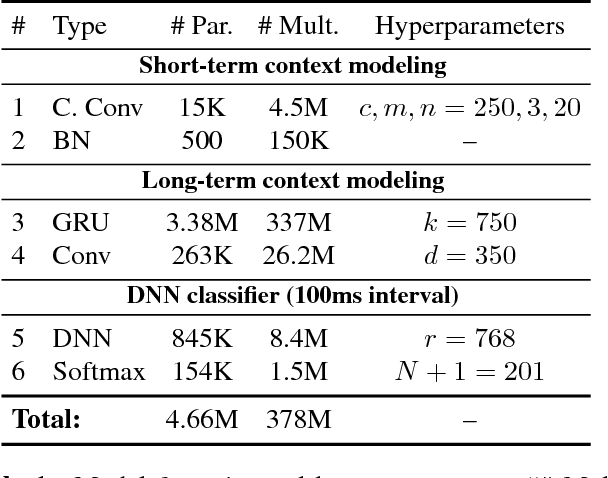
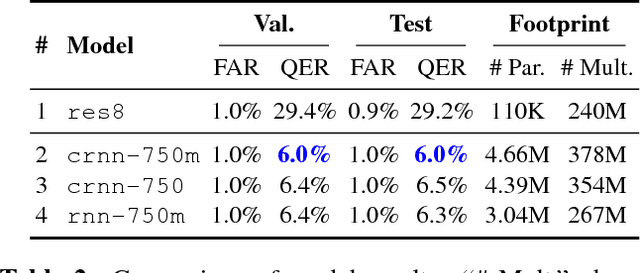
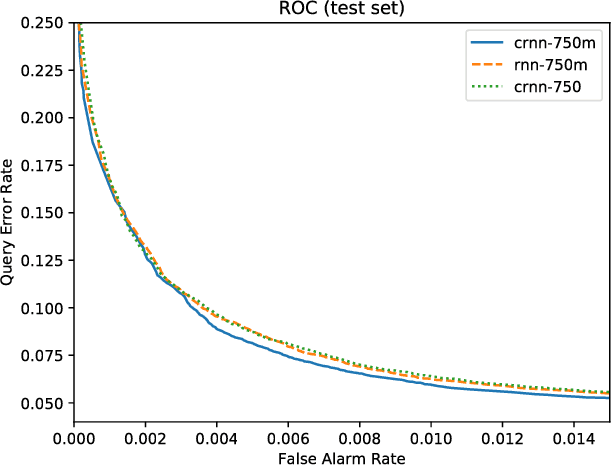
Voice-enabled commercial products are ubiquitous, typically enabled by lightweight on-device keyword spotting (KWS) and full automatic speech recognition (ASR) in the cloud. ASR systems require significant computational resources in training and for inference, not to mention copious amounts of annotated speech data. KWS systems, on the other hand, are less resource-intensive but have limited capabilities. On the Comcast Xfinity X1 entertainment platform, we explore a middle ground between ASR and KWS: We introduce a novel, resource-efficient neural network for voice query recognition that is much more accurate than state-of-the-art CNNs for KWS, yet can be easily trained and deployed with limited resources. On an evaluation dataset representing the top 200 voice queries, we achieve a low false alarm rate of 1% and a query error rate of 6%. Our model performs inference 8.24x faster than the current ASR system.
FLOPs as a Direct Optimization Objective for Learning Sparse Neural Networks
Nov 23, 2018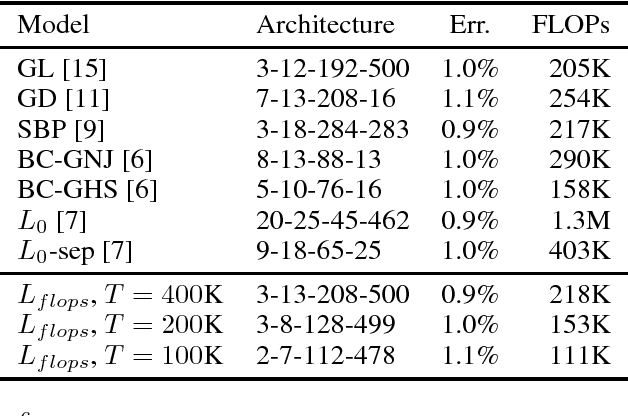
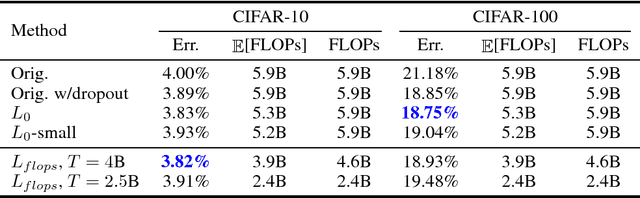
There exists a plethora of techniques for inducing structured sparsity in parametric models during the optimization process, with the final goal of resource-efficient inference. However, few methods target a specific number of floating-point operations (FLOPs) as part of the optimization objective, despite many reporting FLOPs as part of the results. Furthermore, a one-size-fits-all approach ignores realistic system constraints, which differ significantly between, say, a GPU and a mobile phone -- FLOPs on the former incur less latency than on the latter; thus, it is important for practitioners to be able to specify a target number of FLOPs during model compression. In this work, we extend a state-of-the-art technique to directly incorporate FLOPs as part of the optimization objective and show that, given a desired FLOPs requirement, different neural networks can be successfully trained for image classification.
Progress and Tradeoffs in Neural Language Models
Nov 02, 2018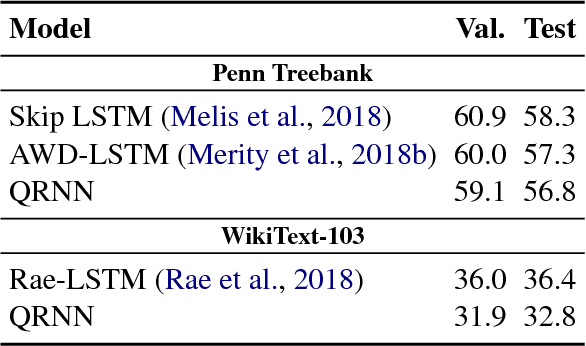
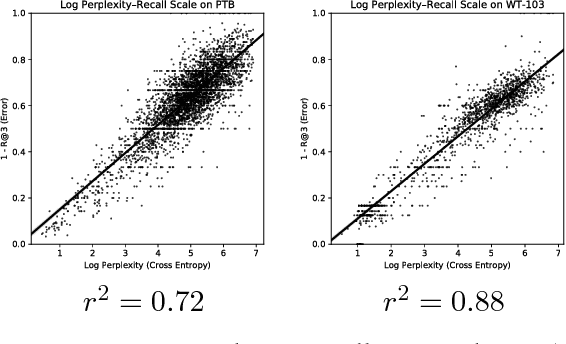
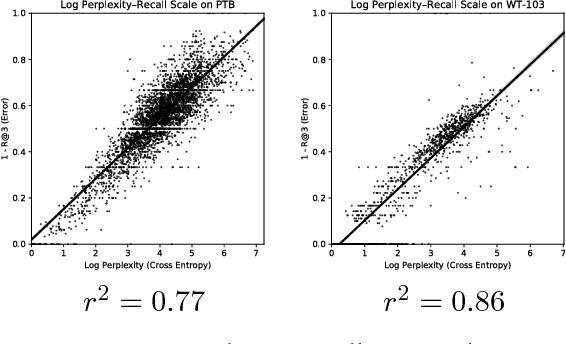
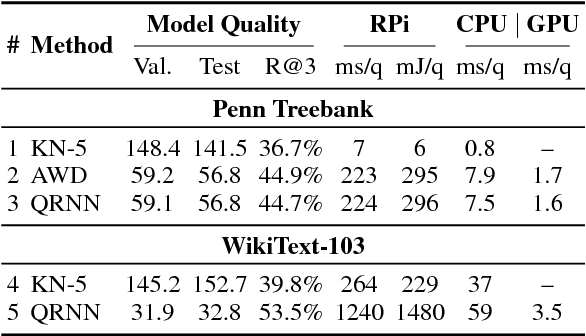
In recent years, we have witnessed a dramatic shift towards techniques driven by neural networks for a variety of NLP tasks. Undoubtedly, neural language models (NLMs) have reduced perplexity by impressive amounts. This progress, however, comes at a substantial cost in performance, in terms of inference latency and energy consumption, which is particularly of concern in deployments on mobile devices. This paper, which examines the quality-performance tradeoff of various language modeling techniques, represents to our knowledge the first to make this observation. We compare state-of-the-art NLMs with "classic" Kneser-Ney (KN) LMs in terms of energy usage, latency, perplexity, and prediction accuracy using two standard benchmarks. On a Raspberry Pi, we find that orders of increase in latency and energy usage correspond to less change in perplexity, while the difference is much less pronounced on a desktop.
JavaScript Convolutional Neural Networks for Keyword Spotting in the Browser: An Experimental Analysis
Oct 30, 2018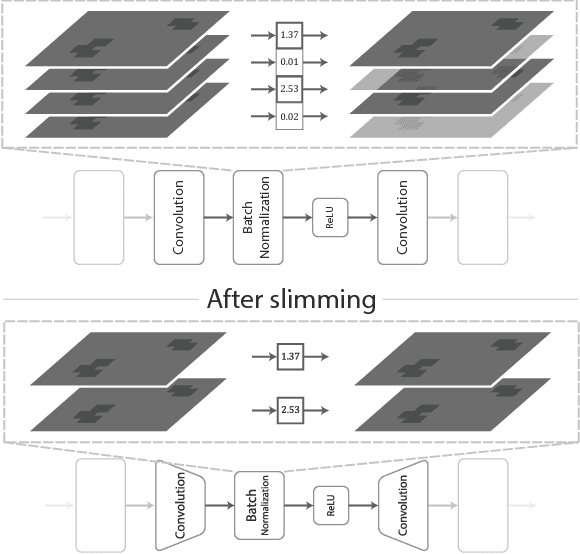
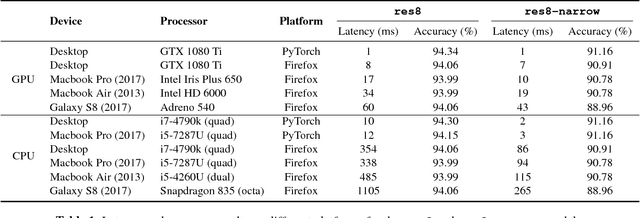
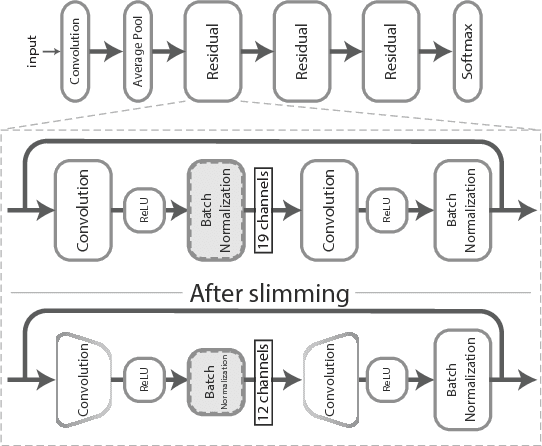
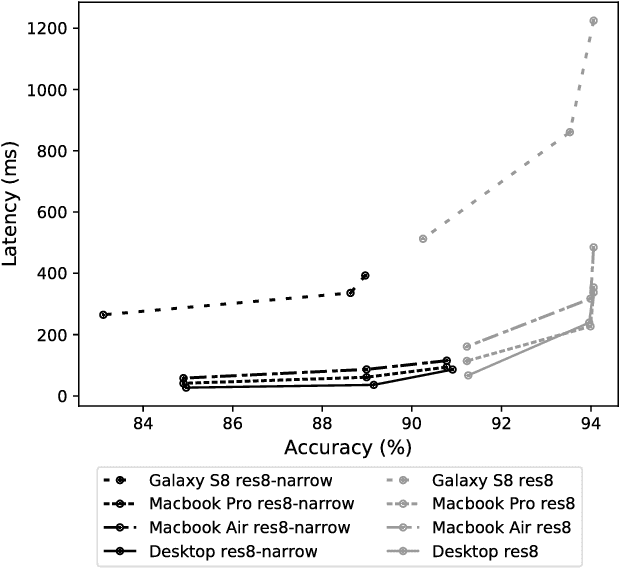
Used for simple commands recognition on devices from smart routers to mobile phones, keyword spotting systems are everywhere. Ubiquitous as well are web applications, which have grown in popularity and complexity over the last decade with significant improvements in usability under cross-platform conditions. However, despite their obvious advantage in natural language interaction, voice-enabled web applications are still far and few between. In this work, we attempt to bridge this gap by bringing keyword spotting capabilities directly into the browser. To our knowledge, we are the first to demonstrate a fully-functional implementation of convolutional neural networks in pure JavaScript that runs in any standards-compliant browser. We also apply network slimming, a model compression technique, to explore the accuracy-efficiency tradeoffs, reporting latency measurements on a range of devices and software. Overall, our robust, cross-device implementation for keyword spotting realizes a new paradigm for serving neural network applications, and one of our slim models reduces latency by 66% with a minimal decrease in accuracy of 4% from 94% to 90%.
Adaptive Pruning of Neural Language Models for Mobile Devices
Sep 27, 2018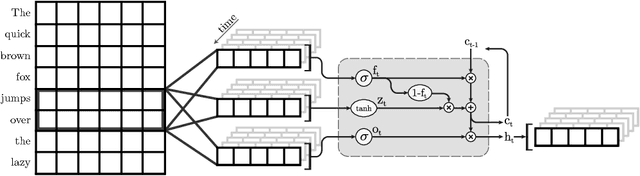
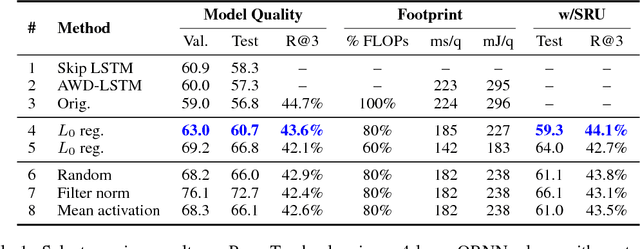
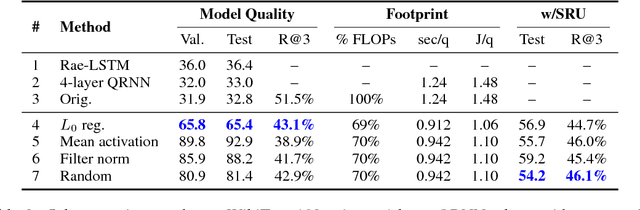
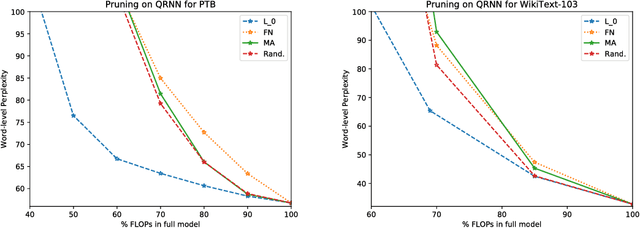
Neural language models (NLMs) exist in an accuracy-efficiency tradeoff space where better perplexity typically comes at the cost of greater computation complexity. In a software keyboard application on mobile devices, this translates into higher power consumption and shorter battery life. This paper represents the first attempt, to our knowledge, in exploring accuracy-efficiency tradeoffs for NLMs. Building on quasi-recurrent neural networks (QRNNs), we apply pruning techniques to provide a "knob" to select different operating points. In addition, we propose a simple technique to recover some perplexity using a negligible amount of memory. Our empirical evaluations consider both perplexity as well as energy consumption on a Raspberry Pi, where we demonstrate which methods provide the best perplexity-power consumption operating point. At one operating point, one of the techniques is able to provide energy savings of 40% over the state of the art with only a 17% relative increase in perplexity.