 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFluids You Can Trust: Property-Preserving Operator Learning for Incompressible Flows
Feb 17, 2026We present a novel property-preserving kernel-based operator learning method for incompressible flows governed by the incompressible Navier-Stokes equations. Traditional numerical solvers incur significant computational costs to respect incompressibility. Operator learning offers efficient surrogate models, but current neural operators fail to exactly enforce physical properties such as incompressibility, periodicity, and turbulence. Our method maps input functions to expansion coefficients of output functions in a property-preserving kernel basis, ensuring that predicted velocity fields analytically and simultaneously preserve the aforementioned physical properties. We evaluate the method on challenging 2D and 3D, laminar and turbulent, incompressible flow problems. Our method achieves up to six orders of magnitude lower relative $\ell_2$ errors upon generalization and trains up to five orders of magnitude faster compared to neural operators. Moreover, while our method enforces incompressibility analytically, neural operators exhibit very large deviations. Our results show that our method provides an accurate and efficient surrogate for incompressible flows.
Ensemble and Mixture-of-Experts DeepONets For Operator Learning
May 21, 2024We present a novel deep operator network (DeepONet) architecture for operator learning, the ensemble DeepONet, that allows for enriching the trunk network of a single DeepONet with multiple distinct trunk networks. This trunk enrichment allows for greater expressivity and generalization capabilities over a range of operator learning problems. We also present a spatial mixture-of-experts (MoE) DeepONet trunk network architecture that utilizes a partition-of-unity (PoU) approximation to promote spatial locality and model sparsity in the operator learning problem. We first prove that both the ensemble and PoU-MoE DeepONets are universal approximators. We then demonstrate that ensemble DeepONets containing a trunk ensemble of a standard trunk, the PoU-MoE trunk, and/or a proper orthogonal decomposition (POD) trunk can achieve 2-4x lower relative $\ell_2$ errors than standard DeepONets and POD-DeepONets on both standard and challenging new operator learning problems involving partial differential equations (PDEs) in two and three dimensions. Our new PoU-MoE formulation provides a natural way to incorporate spatial locality and model sparsity into any neural network architecture, while our new ensemble DeepONet provides a powerful and general framework for incorporating basis enrichment in scientific machine learning architectures for operator learning.
Accelerated Training of Physics Informed Neural Networks (PINNs) using Meshless Discretizations
May 19, 2022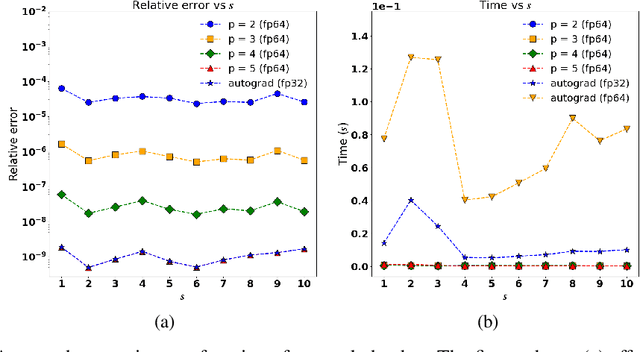
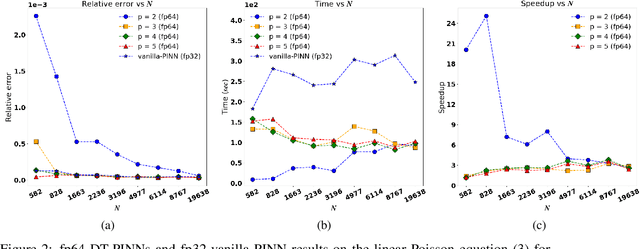
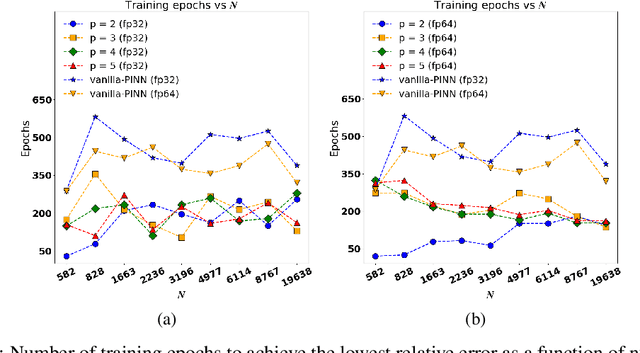
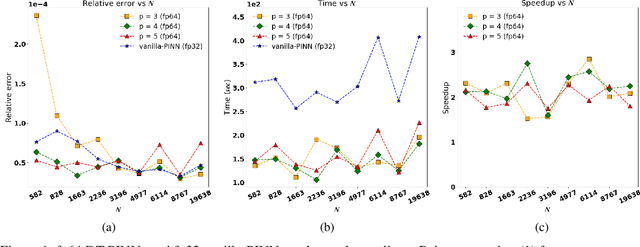
We present a new technique for the accelerated training of physics-informed neural networks (PINNs): discretely-trained PINNs (DT-PINNs). The repeated computation of partial derivative terms in the PINN loss functions via automatic differentiation during training is known to be computationally expensive, especially for higher-order derivatives. DT-PINNs are trained by replacing these exact spatial derivatives with high-order accurate numerical discretizations computed using meshless radial basis function-finite differences (RBF-FD) and applied via sparse-matrix vector multiplication. The use of RBF-FD allows for DT-PINNs to be trained even on point cloud samples placed on irregular domain geometries. Additionally, though traditional PINNs (vanilla-PINNs) are typically stored and trained in 32-bit floating-point (fp32) on the GPU, we show that for DT-PINNs, using fp64 on the GPU leads to significantly faster training times than fp32 vanilla-PINNs with comparable accuracy. We demonstrate the efficiency and accuracy of DT-PINNs via a series of experiments. First, we explore the effect of network depth on both numerical and automatic differentiation of a neural network with random weights and show that RBF-FD approximations of third-order accuracy and above are more efficient while being sufficiently accurate. We then compare the DT-PINNs to vanilla-PINNs on both linear and nonlinear Poisson equations and show that DT-PINNs achieve similar losses with 2-4x faster training times on a consumer GPU. Finally, we also demonstrate that similar results can be obtained for the PINN solution to the heat equation (a space-time problem) by discretizing the spatial derivatives using RBF-FD and using automatic differentiation for the temporal derivative. Our results show that fp64 DT-PINNs offer a superior cost-accuracy profile to fp32 vanilla-PINNs.
Beyond modeling: NLP Pipeline for efficient environmental policy analysis
Jan 08, 2022


As we enter the UN Decade on Ecosystem Restoration, creating effective incentive structures for forest and landscape restoration has never been more critical. Policy analysis is necessary for policymakers to understand the actors and rules involved in restoration in order to shift economic and financial incentives to the right places. Classical policy analysis is resource-intensive and complex, lacks comprehensive central information sources, and is prone to overlapping jurisdictions. We propose a Knowledge Management Framework based on Natural Language Processing (NLP) techniques that would tackle these challenges and automate repetitive tasks, reducing the policy analysis process from weeks to minutes. Our framework was designed in collaboration with policy analysis experts and made to be platform-, language- and policy-agnostic. In this paper, we describe the design of the NLP pipeline, review the state-of-the-art methods for each of its components, and discuss the challenges that rise when building a framework oriented towards policy analysis.