 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Data Flywheel: Applying MAPE Control Loops to AI Agent Improvement
Oct 30, 2025Enterprise AI agents must continuously adapt to maintain accuracy, reduce latency, and remain aligned with user needs. We present a practical implementation of a data flywheel in NVInfo AI, NVIDIA's Mixture-of-Experts (MoE) Knowledge Assistant serving over 30,000 employees. By operationalizing a MAPE-driven data flywheel, we built a closed-loop system that systematically addresses failures in retrieval-augmented generation (RAG) pipelines and enables continuous learning. Over a 3-month post-deployment period, we monitored feedback and collected 495 negative samples. Analysis revealed two major failure modes: routing errors (5.25\%) and query rephrasal errors (3.2\%). Using NVIDIA NeMo microservices, we implemented targeted improvements through fine-tuning. For routing, we replaced a Llama 3.1 70B model with a fine-tuned 8B variant, achieving 96\% accuracy, a 10x reduction in model size, and 70\% latency improvement. For query rephrasal, fine-tuning yielded a 3.7\% gain in accuracy and a 40\% latency reduction. Our approach demonstrates how human-in-the-loop (HITL) feedback, when structured within a data flywheel, transforms enterprise AI agents into self-improving systems. Key learnings include approaches to ensure agent robustness despite limited user feedback, navigating privacy constraints, and executing staged rollouts in production. This work offers a repeatable blueprint for building robust, adaptive enterprise AI agents capable of learning from real-world usage at scale.
In Defense of RAG in the Era of Long-Context Language Models
Sep 03, 2024



Overcoming the limited context limitations in early-generation LLMs, retrieval-augmented generation (RAG) has been a reliable solution for context-based answer generation in the past. Recently, the emergence of long-context LLMs allows the models to incorporate much longer text sequences, making RAG less attractive. Recent studies show that long-context LLMs significantly outperform RAG in long-context applications. Unlike the existing works favoring the long-context LLM over RAG, we argue that the extremely long context in LLMs suffers from a diminished focus on relevant information and leads to potential degradation in answer quality. This paper revisits the RAG in long-context answer generation. We propose an order-preserve retrieval-augmented generation (OP-RAG) mechanism, which significantly improves the performance of RAG for long-context question-answer applications. With OP-RAG, as the number of retrieved chunks increases, the answer quality initially rises, and then declines, forming an inverted U-shaped curve. There exist sweet points where OP-RAG could achieve higher answer quality with much less tokens than long-context LLM taking the whole context as input. Extensive experiments on public benchmark demonstrate the superiority of our OP-RAG.
FACTS About Building Retrieval Augmented Generation-based Chatbots
Jul 10, 2024Enterprise chatbots, powered by generative AI, are emerging as key applications to enhance employee productivity. Retrieval Augmented Generation (RAG), Large Language Models (LLMs), and orchestration frameworks like Langchain and Llamaindex are crucial for building these chatbots. However, creating effective enterprise chatbots is challenging and requires meticulous RAG pipeline engineering. This includes fine-tuning embeddings and LLMs, extracting documents from vector databases, rephrasing queries, reranking results, designing prompts, honoring document access controls, providing concise responses, including references, safeguarding personal information, and building orchestration agents. We present a framework for building RAG-based chatbots based on our experience with three NVIDIA chatbots: for IT/HR benefits, financial earnings, and general content. Our contributions are three-fold: introducing the FACTS framework (Freshness, Architectures, Cost, Testing, Security), presenting fifteen RAG pipeline control points, and providing empirical results on accuracy-latency tradeoffs between large and small LLMs. To the best of our knowledge, this is the first paper of its kind that provides a holistic view of the factors as well as solutions for building secure enterprise-grade chatbots."
An Empirical Study of Factors Affecting Language-Independent Models
Dec 30, 2019


Scaling existing applications and solutions to multiple human languages has traditionally proven to be difficult, mainly due to the language-dependent nature of preprocessing and feature engineering techniques employed in traditional approaches. In this work, we empirically investigate the factors affecting language-independent models built with multilingual representations, including task type, language set and data resource. On two most representative NLP tasks -- sentence classification and sequence labeling, we show that language-independent models can be comparable to or even outperforms the models trained using monolingual data, and they are generally more effective on sentence classification. We experiment language-independent models with many different languages and show that they are more suitable for typologically similar languages. We also explore the effects of different data sizes when training and testing language-independent models, and demonstrate that they are not only suitable for high-resource languages, but also very effective in low-resource languages.
Characterizing machine learning process: A maturity framework
Nov 12, 2018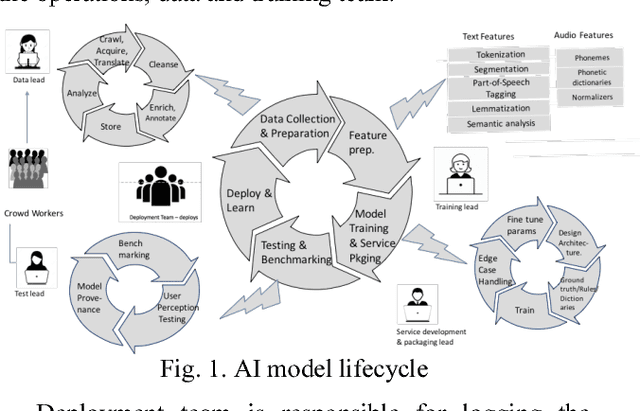
Academic literature on machine learning modeling fails to address how to make machine learning models work for enterprises. For example, existing machine learning processes cannot address how to define business use cases for an AI application, how to convert business requirements from offering managers into data requirements for data scientists, and how to continuously improve AI applications in term of accuracy and fairness, and how to customize general purpose machine learning models with industry, domain, and use case specific data to make them more accurate for specific situations etc. Making AI work for enterprises requires special considerations, tools, methods and processes. In this paper we present a maturity framework for machine learning model lifecycle management for enterprises. Our framework is a re-interpretation of the software Capability Maturity Model (CMM) for machine learning model development process. We present a set of best practices from our personal experience of building large scale real-world machine learning models to help organizations achieve higher levels of maturity independent of their starting point.
Challenge AI Mind: A Crowd System for Proactive AI Testing
Oct 21, 2018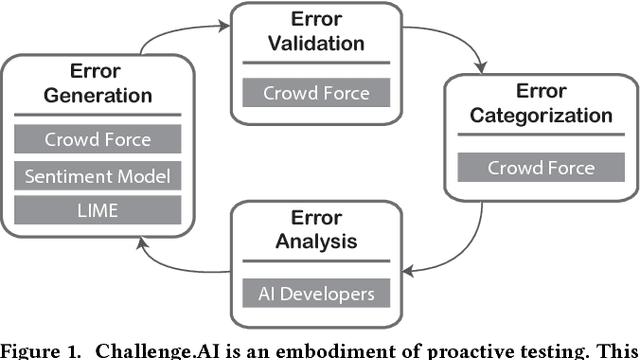
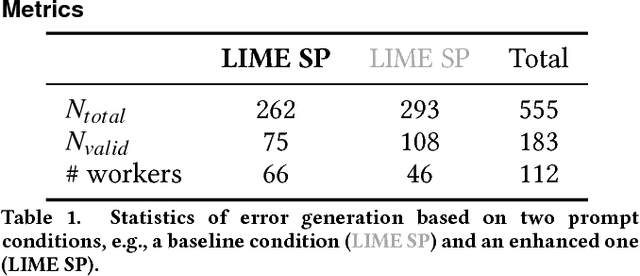
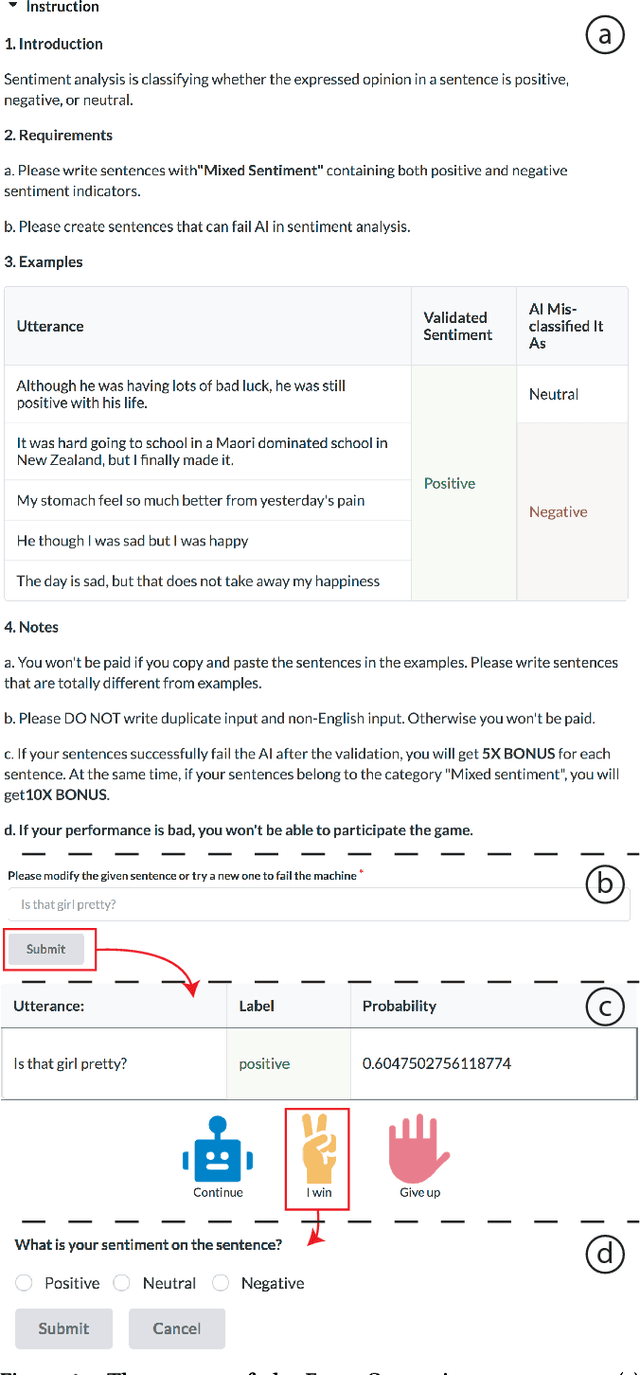

Artificial Intelligence (AI) has burrowed into our lives in various aspects; however, without appropriate testing, deployed AI systems are often being criticized to fail in critical and embarrassing cases. Existing testing approaches mainly depend on fixed and pre-defined datasets, providing a limited testing coverage. In this paper, we propose the concept of proactive testing to dynamically generate testing data and evaluate the performance of AI systems. We further introduce Challenge.AI, a new crowd system that features the integration of crowdsourcing and machine learning techniques in the process of error generation, error validation, error categorization, and error analysis. We present experiences and insights into a participatory design with AI developers. The evaluation shows that the crowd workflow is more effective with the help of machine learning techniques. AI developers found that our system can help them discover unknown errors made by the AI models, and engage in the process of proactive testing.
Don't get Lost in Negation: An Effective Negation Handled Dialogue Acts Prediction Algorithm for Twitter Customer Service Conversations
Jul 16, 2018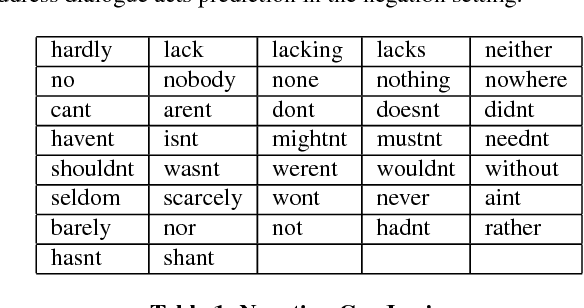

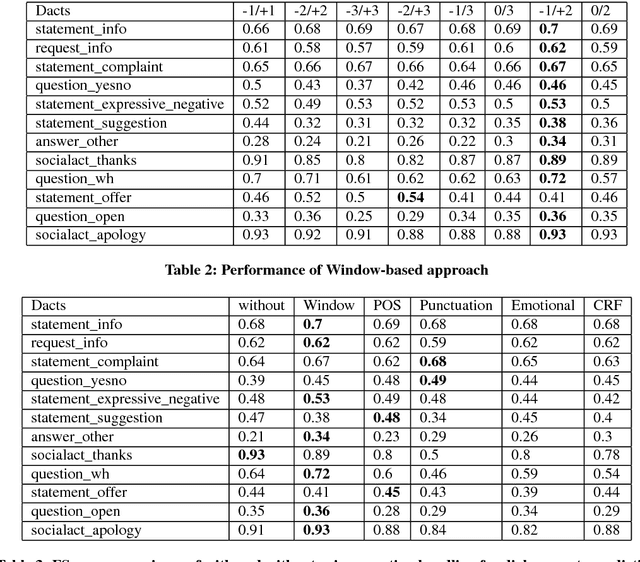
In the last several years, Twitter is being adopted by the companies as an alternative platform to interact with the customers to address their concerns. With the abundance of such unconventional conversation resources, push for developing effective virtual agents is more than ever. To address this challenge, a better understanding of such customer service conversations is required. Lately, there have been several works proposing a novel taxonomy for fine-grained dialogue acts as well as develop algorithms for automatic detection of these acts. The outcomes of these works are providing stepping stones for the ultimate goal of building efficient and effective virtual agents. But none of these works consider handling the notion of negation into the proposed algorithms. In this work, we developed an SVM-based dialogue acts prediction algorithm for Twitter customer service conversations where negation handling is an integral part of the end-to-end solution. For negation handling, we propose several efficient heuristics as well as adopt recent state-of- art third party machine learning based solutions. Empirically we show model's performance gain while handling negation compared to when we don't. Our experiments show that for the informal text such as tweets, the heuristic-based approach is more effective.
"How May I Help You?": Modeling Twitter Customer Service Conversations Using Fine-Grained Dialogue Acts
Sep 15, 2017
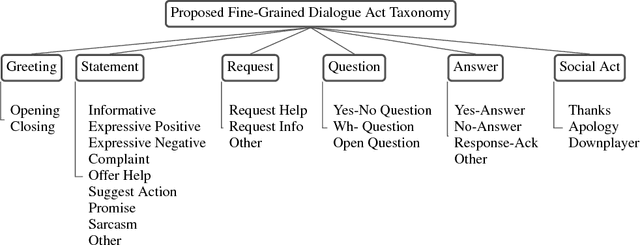
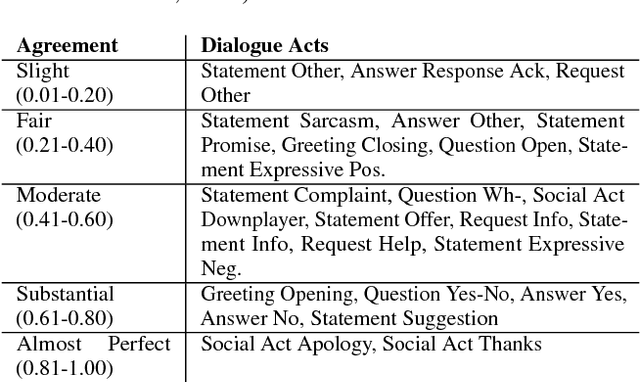
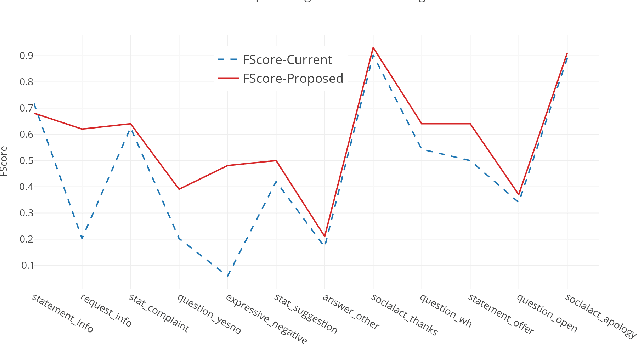
Given the increasing popularity of customer service dialogue on Twitter, analysis of conversation data is essential to understand trends in customer and agent behavior for the purpose of automating customer service interactions. In this work, we develop a novel taxonomy of fine-grained "dialogue acts" frequently observed in customer service, showcasing acts that are more suited to the domain than the more generic existing taxonomies. Using a sequential SVM-HMM model, we model conversation flow, predicting the dialogue act of a given turn in real-time. We characterize differences between customer and agent behavior in Twitter customer service conversations, and investigate the effect of testing our system on different customer service industries. Finally, we use a data-driven approach to predict important conversation outcomes: customer satisfaction, customer frustration, and overall problem resolution. We show that the type and location of certain dialogue acts in a conversation have a significant effect on the probability of desirable and undesirable outcomes, and present actionable rules based on our findings. The patterns and rules we derive can be used as guidelines for outcome-driven automated customer service platforms.
25 Tweets to Know You: A New Model to Predict Personality with Social Media
Apr 18, 2017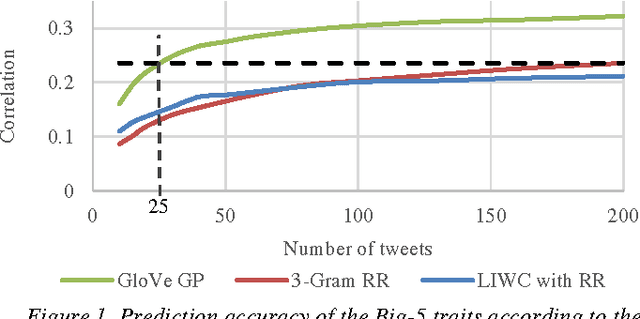
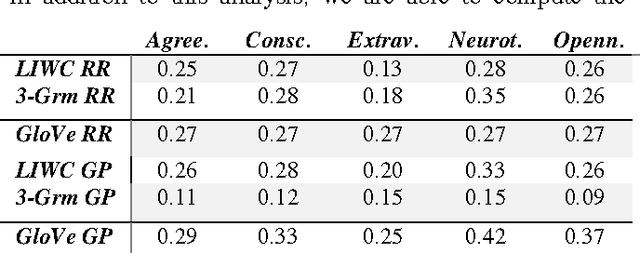
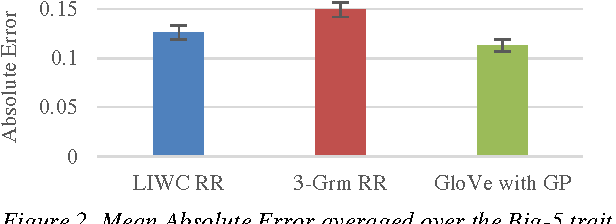
Predicting personality is essential for social applications supporting human-centered activities, yet prior modeling methods with users written text require too much input data to be realistically used in the context of social media. In this work, we aim to drastically reduce the data requirement for personality modeling and develop a model that is applicable to most users on Twitter. Our model integrates Word Embedding features with Gaussian Processes regression. Based on the evaluation of over 1.3K users on Twitter, we find that our model achieves comparable or better accuracy than state of the art techniques with 8 times fewer data.