 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR-Net: A simple Auto-Regressive Neural Network for time-series
Nov 27, 2019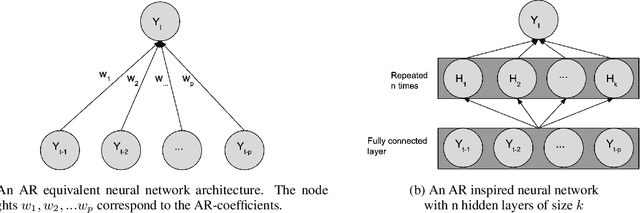
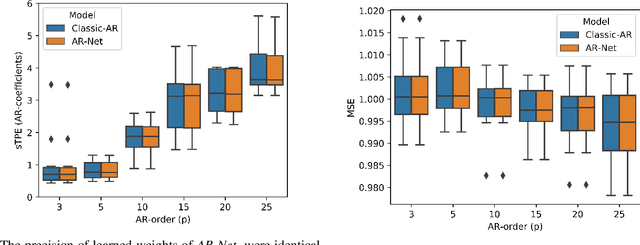
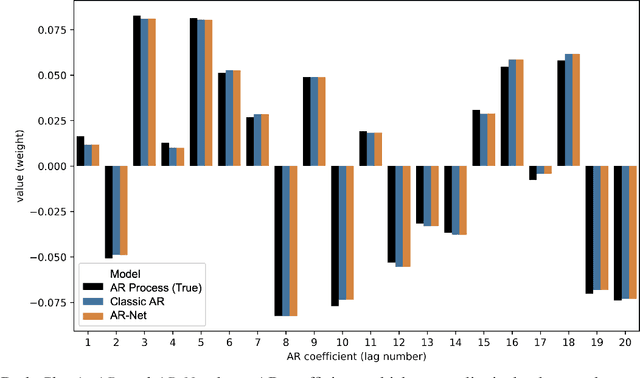
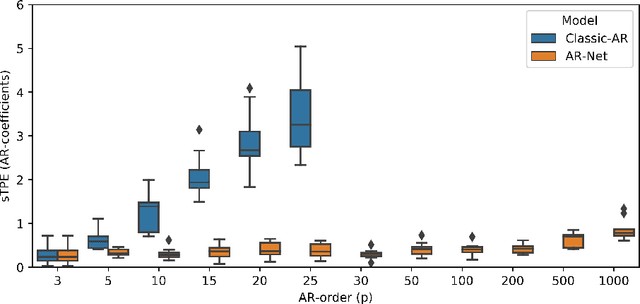
In this paper we present a new framework for time-series modeling that combines the best of traditional statistical models and neural networks. We focus on time-series with long-range dependencies, needed for monitoring fine granularity data (e.g. minutes, seconds, milliseconds), prevalent in operational use-cases. Traditional models, such as auto-regression fitted with least squares (Classic-AR) can model time-series with a concise and interpretable model. When dealing with long-range dependencies, Classic-AR models can become intractably slow to fit for large data. Recently, sequence-to-sequence models, such as Recurrent Neural Networks, which were originally intended for natural language processing, have become popular for time-series. However, they can be overly complex for typical time-series data and lack interpretability. A scalable and interpretable model is needed to bridge the statistical and deep learning-based approaches. As a first step towards this goal, we propose modelling AR-process dynamics using a feed-forward neural network approach, termed AR-Net. We show that AR-Net is as interpretable as Classic-AR but also scales to long-range dependencies. Our results lead to three major conclusions: First, AR-Net learns identical AR-coefficients as Classic-AR, thus being equally interpretable. Second, the computational complexity with respect to the order of the AR process, is linear for AR-Net as compared to a quadratic for Classic-AR. This makes it possible to model long-range dependencies within fine granularity data. Third, by introducing regularization, AR-Net automatically selects and learns sparse AR-coefficients. This eliminates the need to know the exact order of the AR-process and allows to learn sparse weights for a model with long-range dependencies.
On the Interaction between Autonomous Mobility on Demand Systems and Power Distribution Networks -- An Optimal Power Flow Approach
May 01, 2019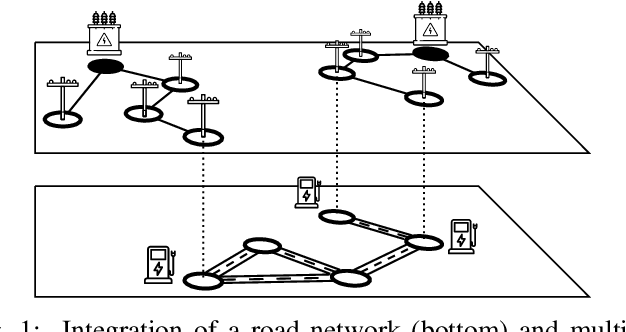
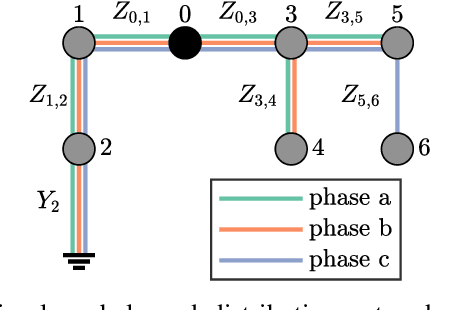
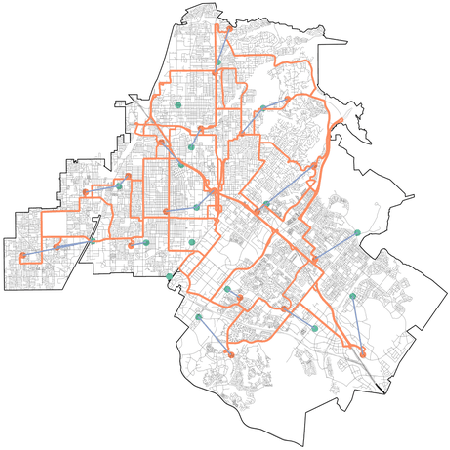
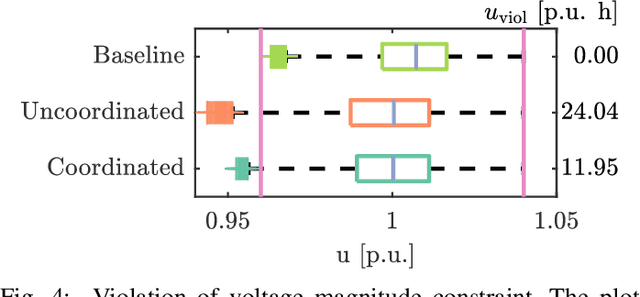
In future transportation systems, the charging behavior of electric Autonomous Mobility on Demand (AMoD) fleets, i.e., fleets of self-driving cars that service on-demand trip requests, will likely challenge power distribution networks (PDNs), causing overloads or voltage drops. In this paper, we show that these challenges can be significantly attenuated if the PDNs' operational constraints and exogenous loads (e.g., from homes or businesses) are considered when operating the electric AMoD fleet. We focus on a system-level perspective, assuming full cooperation between the AMoD and the PDN operators. Through this single entity perspective, we derive an upper bound on the benefits of coordination. We present an optimization-based modeling approach to jointly control an electric AMoD fleet and a series of PDNs, and analyze the benefit of coordination under load balancing constraints. For a case study in Orange County, CA, we show that coordinating the electric AMoD fleet and the PDNs helps to reduce 99% of overloads and 50% of voltage drops which the electric AMoD fleet causes without coordination. Our results show that coordinating electric AMoD and PDNs helps to level loads and can significantly postpone the point at which upgrading the network's capacity to a larger scale becomes inevitable to preserve stability.
Distributed generation of privacy preserving data with user customization
Apr 20, 2019

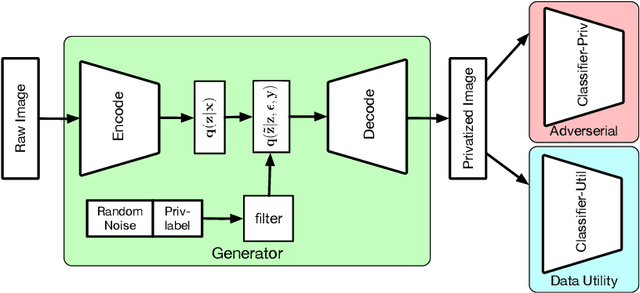

Distributed devices such as mobile phones can produce and store large amounts of data that can enhance machine learning models; however, this data may contain private information specific to the data owner that prevents the release of the data. We wish to reduce the correlation between user-specific private information and data while maintaining the useful information. Rather than learning a large model to achieve privatization from end to end, we introduce a decoupling of the creation of a latent representation and the privatization of data that allows user-specific privatization to occur in a distributed setting with limited computation and minimal disturbance on the utility of the data. We leverage a Variational Autoencoder (VAE) to create a compact latent representation of the data; however, the VAE remains fixed for all devices and all possible private labels. We then train a small generative filter to perturb the latent representation based on individual preferences regarding the private and utility information. The small filter is trained by utilizing a GAN-type robust optimization that can take place on a distributed device. We conduct experiments on three popular datasets: MNIST, UCI-Adult, and CelebA, and give a thorough evaluation including visualizing the geometry of the latent embeddings and estimating the empirical mutual information to show the effectiveness of our approach.
Structural Damage Detection and Localization with Unknown Post-Damage Feature Distribution Using Sequential Change-Point Detection Method
Nov 14, 2018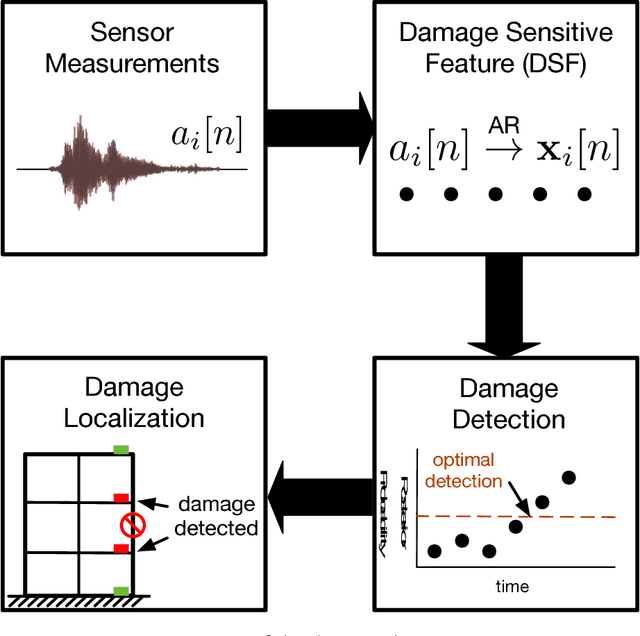
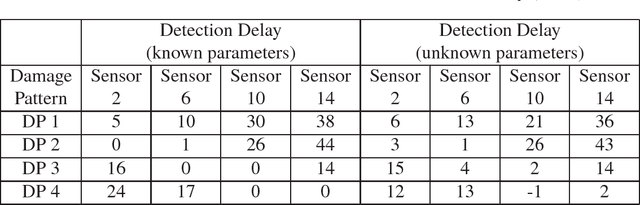
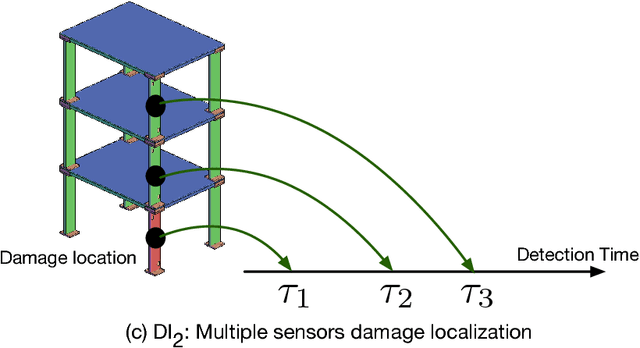
The high structural deficient rate poses serious risks to the operation of many bridges and buildings. To prevent critical damage and structural collapse, a quick structural health diagnosis tool is needed during normal operation or immediately after extreme events. In structural health monitoring (SHM), many existing works will have limited performance in the quick damage identification process because 1) the damage event needs to be identified with short delay and 2) the post-damage information is usually unavailable. To address these drawbacks, we propose a new damage detection and localization approach based on stochastic time series analysis. Specifically, the damage sensitive features are extracted from vibration signals and follow different distributions before and after a damage event. Hence, we use the optimal change point detection theory to find damage occurrence time. As the existing change point detectors require the post-damage feature distribution, which is unavailable in SHM, we propose a maximum likelihood method to learn the distribution parameters from the time-series data. The proposed damage detection using estimated parameters also achieves the optimal performance. Also, we utilize the detection results to find damage location without any further computation. Validation results show highly accurate damage identification in American Society of Civil Engineers benchmark structure and two shake table experiments.
Fast Distribution Grid Line Outage Identification with $μ$PMU
Nov 14, 2018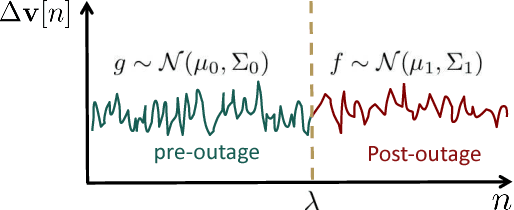
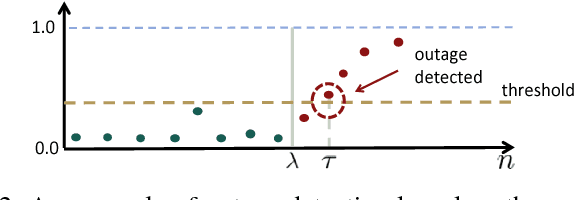
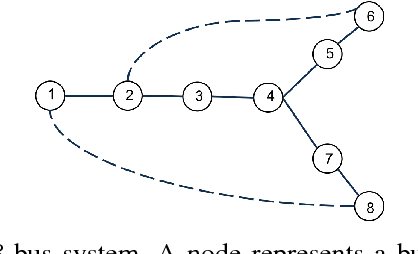
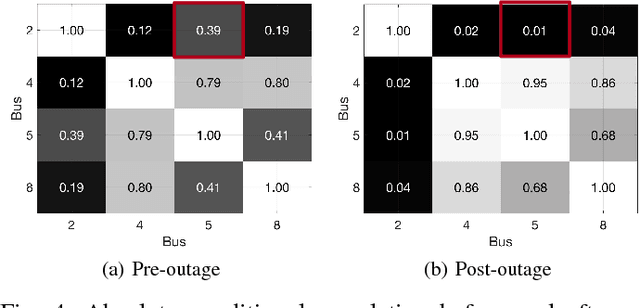
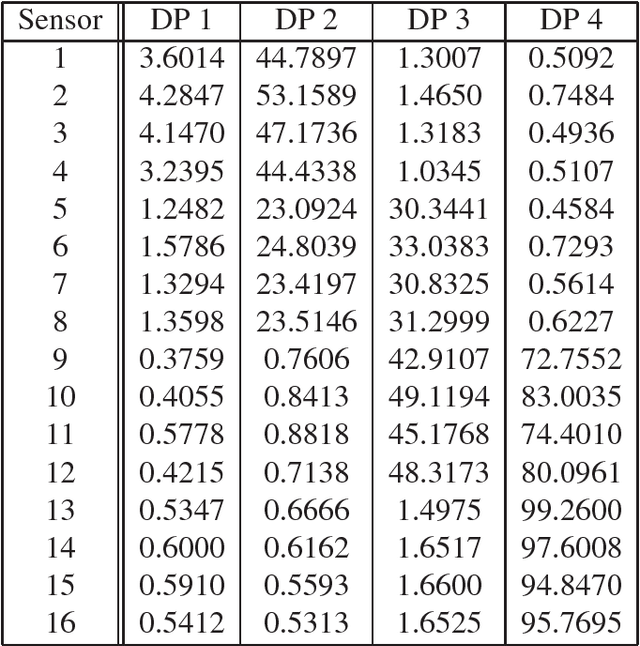
The growing integration of distributed energy resources (DERs) in urban distribution grids raises various reliability issues due to DER's uncertain and complex behaviors. With a large-scale DER penetration, traditional outage detection methods, which rely on customers making phone calls and smart meters' "last gasp" signals, will have limited performance, because the renewable generators can supply powers after line outages and many urban grids are mesh so line outages do not affect power supply. To address these drawbacks, we propose a data-driven outage monitoring approach based on the stochastic time series analysis from micro phasor measurement unit ($\mu$PMU). Specifically, we prove via power flow analysis that the dependency of time-series voltage measurements exhibits significant statistical changes after line outages. This makes the theory on optimal change-point detection suitable to identify line outages via $\mu$PMUs with fast and accurate sampling. However, existing change point detection methods require post-outage voltage distribution unknown in distribution systems. Therefore, we design a maximum likelihood-based method to directly learn the distribution parameters from $\mu$PMU data. We prove that the estimated parameters-based detection still achieves the optimal performance, making it extremely useful for distribution grid outage identifications. Simulation results show highly accurate outage identification in eight distribution grids with 14 configurations with and without DERs using $\mu$PMU data.
Unbalanced Three-Phase Distribution Grid Topology Estimation and Bus Phase Identification
Oct 09, 2018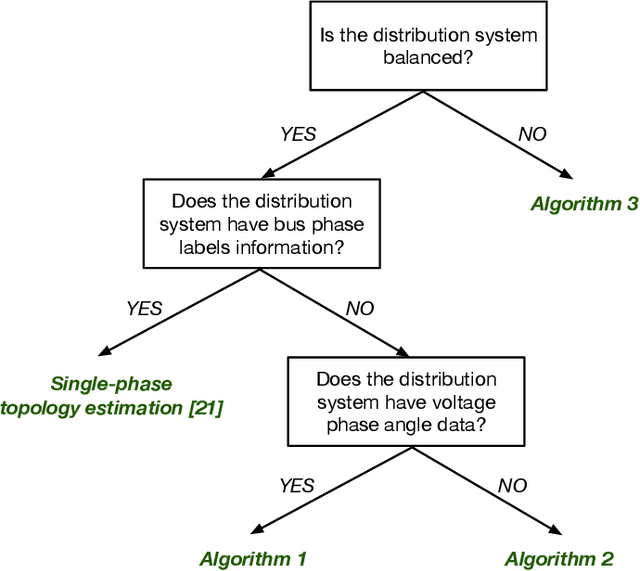
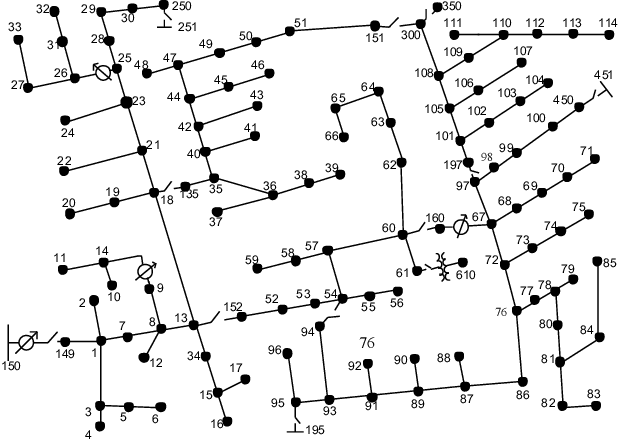
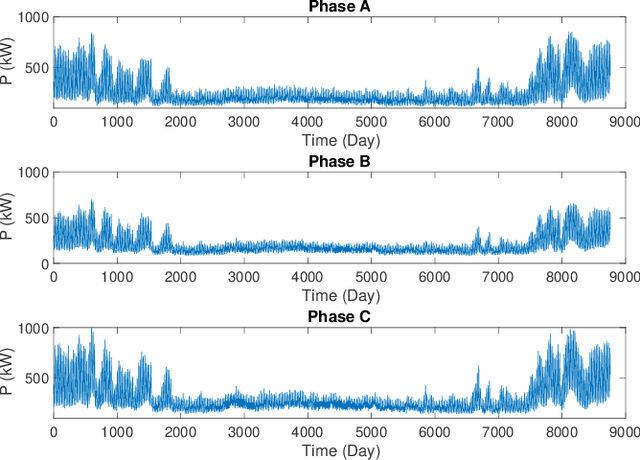
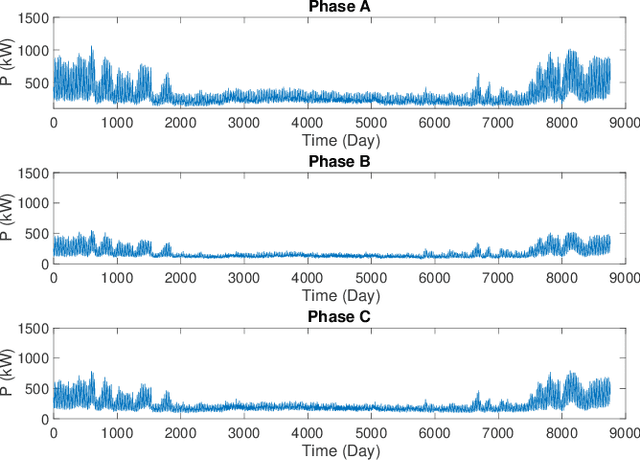
There is an increasing need for monitoring and controlling uncertainties brought by distributed energy resources in distribution grids. For such goal, accurate three-phase topology is the basis for correlating and exterminating measurements in unbalanced distribution networks. Unfortunately, such topology knowledge is often unavailable due to limited investment, especially for secondary distribution grids. Also, the bus phase connectivity information is inaccurate due to human errors or outdated records. For this challenge, we utilize smart meter data at different phases for an information-theoretic approach to learn the structures. Specifically, we convert the system of three unbalanced phasors into symmetrical components, namely the positive, negative, and zero sequences. Then, we prove that Chow-Liu algorithm can find the optimal topology by utilizing power flow equation and the conditional independence relationships implied by the radial three-phase structure of distribution grids with the presence of incorrect bus phase labels. At last, by utilizing Carson's equation, we prove that the bus phase connection can be correctly identified using voltage measurements. For validation, we extensively simulate on IEEE $37$- and $123$-bus systems using real data from PG\&E, ADRES Project, and Pecan Street. We observe that the algorithm is highly accurate for finding three-phase topology in distribution grids even with strong load unbalancing condition and DERs. This ensures close monitoring and controlling DERs in distribution grids.
Siamese Generative Adversarial Privatizer for Biometric Data
Oct 08, 2018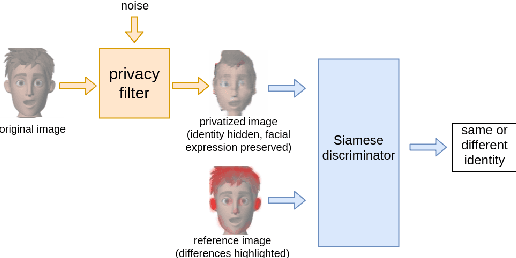
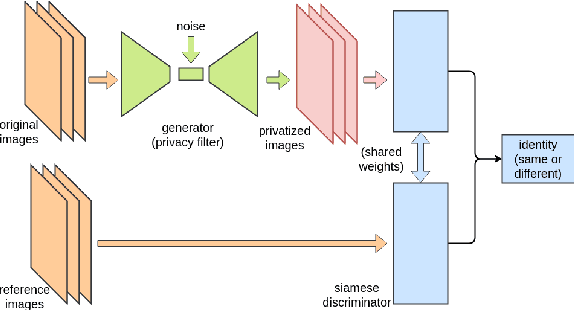
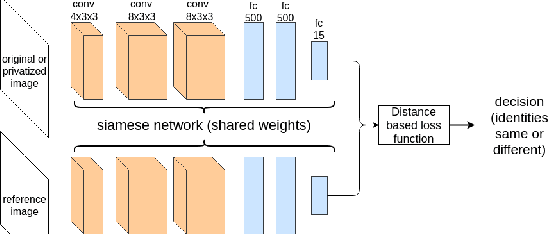
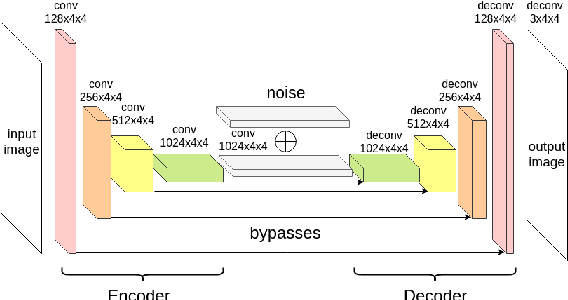
State-of-the-art machine learning algorithms can be fooled by carefully crafted adversarial examples. As such, adversarial examples present a concrete problem in AI safety. In this work we turn the tables and ask the following question: can we harness the power of adversarial examples to prevent malicious adversaries from learning identifying information from data while allowing non-malicious entities to benefit from the utility of the same data? For instance, can we use adversarial examples to anonymize biometric dataset of faces while retaining usefulness of this data for other purposes, such as emotion recognition? To address this question, we propose a simple yet effective method, called Siamese Generative Adversarial Privatizer (SGAP), that exploits the properties of a Siamese neural network to find discriminative features that convey identifying information. When coupled with a generative model, our approach is able to correctly locate and disguise identifying information, while minimally reducing the utility of the privatized dataset. Extensive evaluation on a biometric dataset of fingerprints and cartoon faces confirms usefulness of our simple yet effective method.
Understanding Compressive Adversarial Privacy
Oct 02, 2018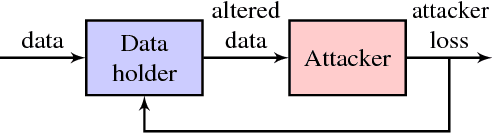
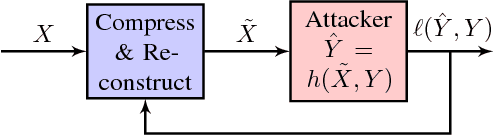
Designing a data sharing mechanism without sacrificing too much privacy can be considered as a game between data holders and malicious attackers. This paper describes a compressive adversarial privacy framework that captures the trade-off between the data privacy and utility. We characterize the optimal data releasing mechanism through convex optimization when assuming that both the data holder and attacker can only modify the data using linear transformations. We then build a more realistic data releasing mechanism that can rely on a nonlinear compression model while the attacker uses a neural network. We demonstrate in a series of empirical applications that this framework, consisting of compressive adversarial privacy, can preserve sensitive information.
Urban MV and LV Distribution Grid Topology Estimation via Group Lasso
Sep 13, 2018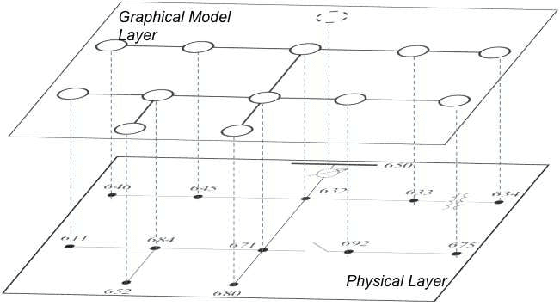
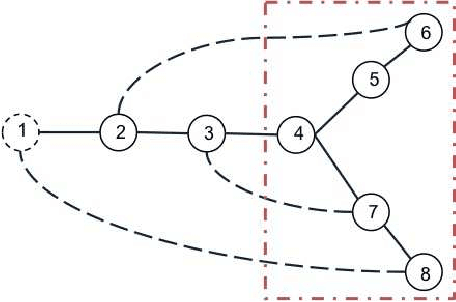
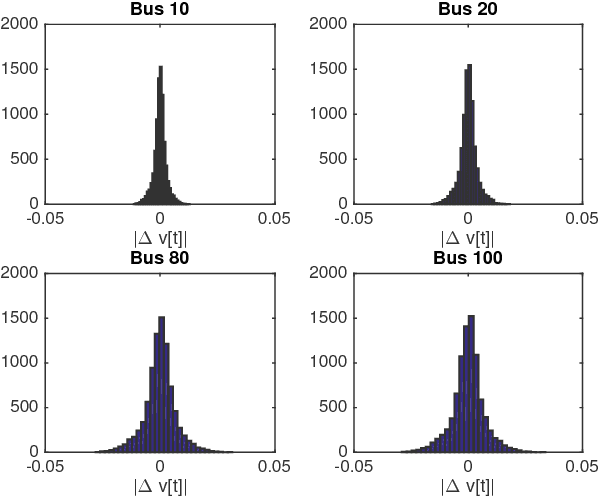
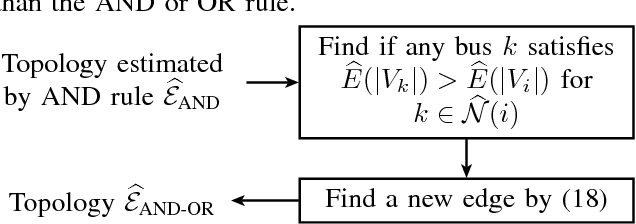
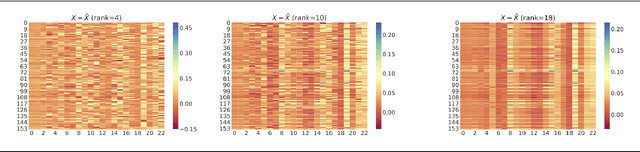
The increasing penetration of distributed energy resources poses numerous reliability issues to the urban distribution grid. The topology estimation is a critical step to ensure the robustness of distribution grid operation. However, the bus connectivity and grid topology estimation are usually hard in distribution grids. For example, it is technically challenging and costly to monitor the bus connectivity in urban grids, e.g., underground lines. It is also inappropriate to use the radial topology assumption exclusively because the grids of metropolitan cities and regions with dense loads could be with many mesh structures. To resolve these drawbacks, we propose a data-driven topology estimation method for MV and LV distribution grids by only utilizing the historical smart meter measurements. Particularly, a probabilistic graphical model is utilized to capture the statistical dependencies amongst bus voltages. We prove that the bus connectivity and grid topology estimation problems, in radial and mesh structures, can be formulated as a linear regression with a least absolute shrinkage regularization on grouped variables (\textit{group lasso}). Simulations show highly accurate results in eight MV and LV distribution networks at different sizes and 22 topology configurations using PG\&E residential smart meter data.
* 15 pages, 16 figures
Generative Adversarial Privacy
Jul 13, 2018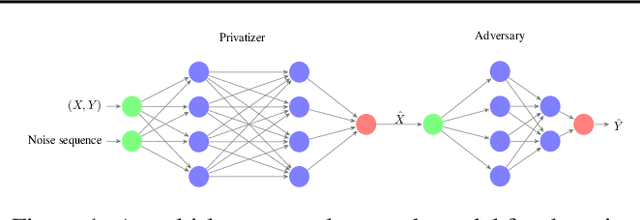
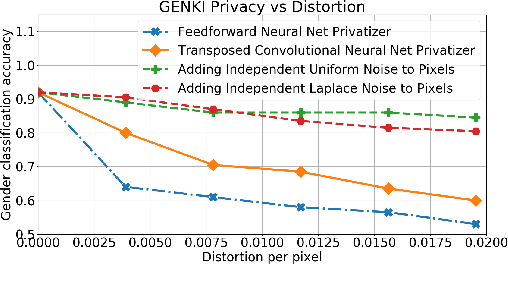

We present a data-driven framework called generative adversarial privacy (GAP). Inspired by recent advancements in generative adversarial networks (GANs), GAP allows the data holder to learn the privatization mechanism directly from the data. Under GAP, finding the optimal privacy mechanism is formulated as a constrained minimax game between a privatizer and an adversary. We show that for appropriately chosen adversarial loss functions, GAP provides privacy guarantees against strong information-theoretic adversaries. We also evaluate the performance of GAP on multi-dimensional Gaussian mixture models and the GENKI face database.