 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Role of Affect Dimensions in Detecting Emotions from Tweets: A Multi-task Approach
May 09, 2021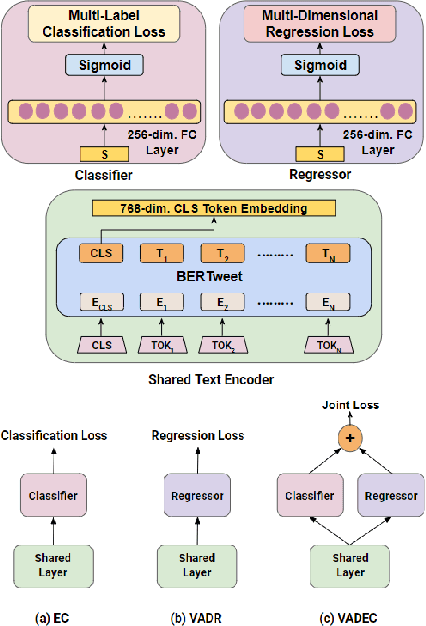
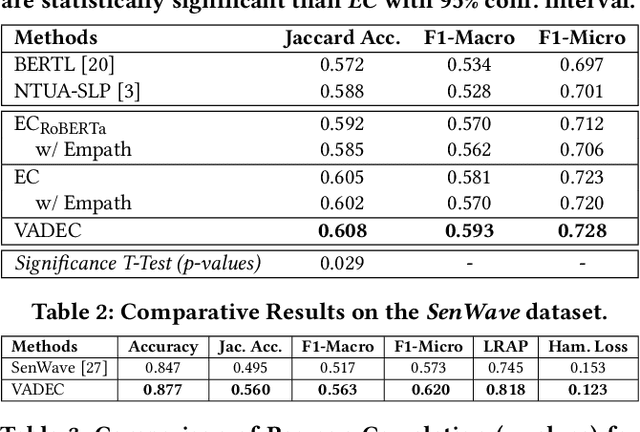
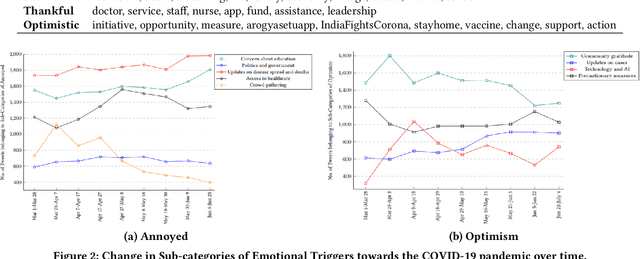
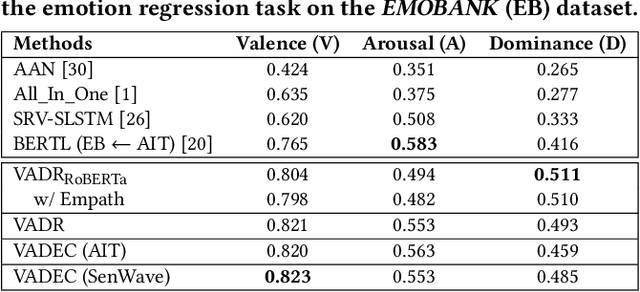
We propose VADEC, a multi-task framework that exploits the correlation between the categorical and dimensional models of emotion representation for better subjectivity analysis. Focusing primarily on the effective detection of emotions from tweets, we jointly train multi-label emotion classification and multi-dimensional emotion regression, thereby utilizing the inter-relatedness between the tasks. Co-training especially helps in improving the performance of the classification task as we outperform the strongest baselines with 3.4%, 11%, and 3.9% gains in Jaccard Accuracy, Macro-F1, and Micro-F1 scores respectively on the AIT dataset. We also achieve state-of-the-art results with 11.3% gains averaged over six different metrics on the SenWave dataset. For the regression task, VADEC, when trained with SenWave, achieves 7.6% and 16.5% gains in Pearson Correlation scores over the current state-of-the-art on the EMOBANK dataset for the Valence (V) and Dominance (D) affect dimensions respectively. We conclude our work with a case study on COVID-19 tweets posted by Indians that further helps in establishing the efficacy of our proposed solution.
Reproducibility, Replicability and Beyond: Assessing Production Readiness of Aspect Based Sentiment Analysis in the Wild
Jan 23, 2021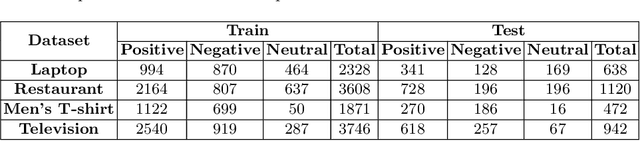
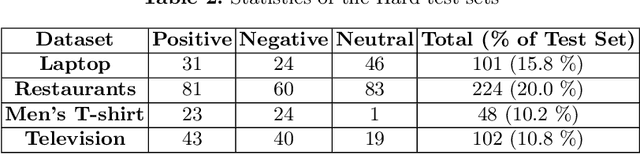
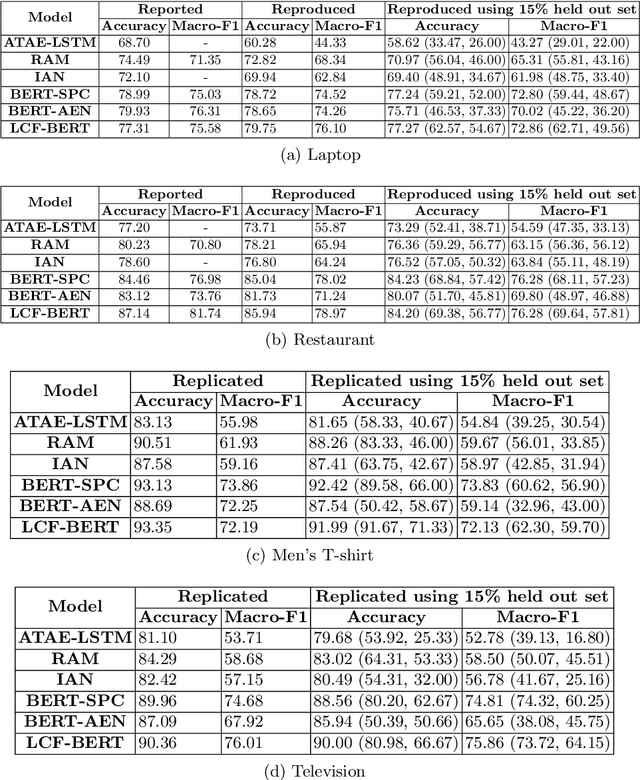

With the exponential growth of online marketplaces and user-generated content therein, aspect-based sentiment analysis has become more important than ever. In this work, we critically review a representative sample of the models published during the past six years through the lens of a practitioner, with an eye towards deployment in production. First, our rigorous empirical evaluation reveals poor reproducibility: an average 4-5% drop in test accuracy across the sample. Second, to further bolster our confidence in empirical evaluation, we report experiments on two challenging data slices, and observe a consistent 12-55% drop in accuracy. Third, we study the possibility of transfer across domains and observe that as little as 10-25% of the domain-specific training dataset, when used in conjunction with datasets from other domains within the same locale, largely closes the gap between complete cross-domain and complete in-domain predictive performance. Lastly, we open-source two large-scale annotated review corpora from a large e-commerce portal in India in order to aid the study of replicability and transfer, with the hope that it will fuel further growth of the field.
How Have We Reacted To The COVID-19 Pandemic? Analyzing Changing Indian Emotions Through The Lens of Twitter
Aug 20, 2020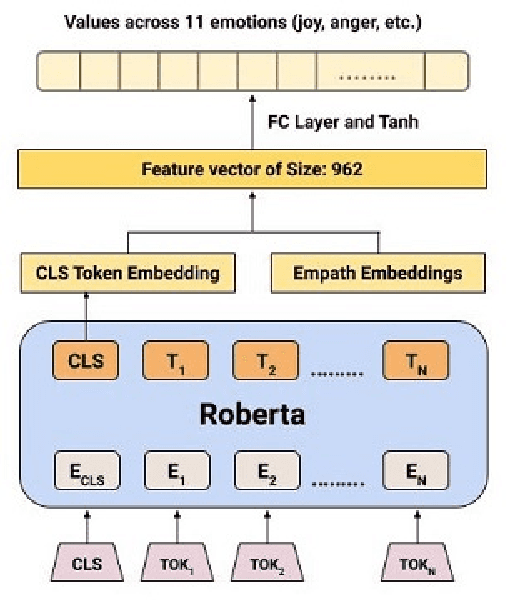
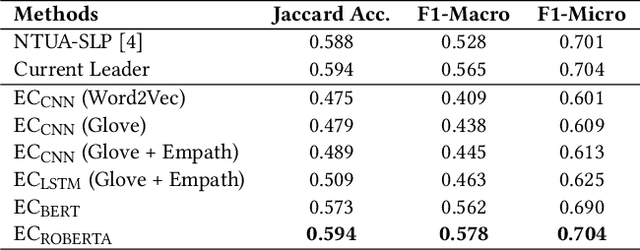
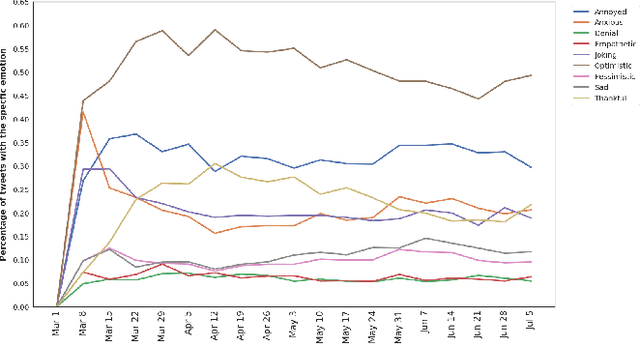
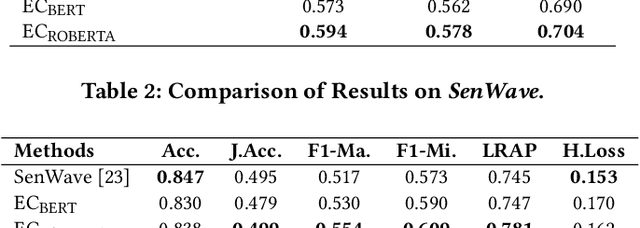
Since its outbreak, the ongoing COVID-19 pandemic has caused unprecedented losses to human lives and economies around the world. As of 18th July 2020, the World Health Organization (WHO) has reported more than 13 million confirmed cases including close to 600,000 deaths across 216 countries and territories. Despite several government measures, India has gradually moved up the ranks to become the third worst-hit nation by the pandemic after the US and Brazil, thus causing widespread anxiety and fear among her citizens. As majority of the world's population continues to remain confined to their homes, more and more people have started relying on social media platforms such as Twitter for expressing their feelings and attitudes towards various aspects of the pandemic. With rising concerns of mental well-being, it becomes imperative to analyze the dynamics of public affect in order to anticipate any potential threats and take precautionary measures. Since affective states of human mind are more nuanced than meager binary sentiments, here we propose a deep learning-based system to identify people's emotions from their tweets. We achieve competitive results on two benchmark datasets for multi-label emotion classification. We then use our system to analyze the evolution of emotional responses among Indians as the pandemic continues to spread its wings. We also study the development of salient factors contributing towards the changes in attitudes over time. Finally, we discuss directions to further improve our work and hope that our analysis can aid in better public health monitoring.
Read what you need: Controllable Aspect-based Opinion Summarization of Tourist Reviews
Jun 09, 2020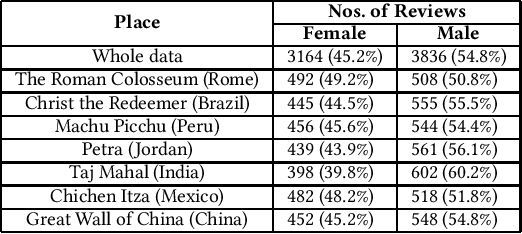
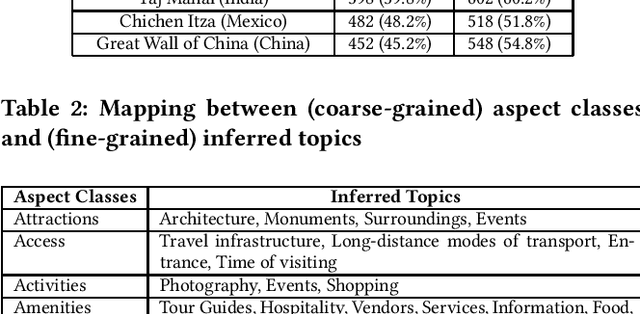
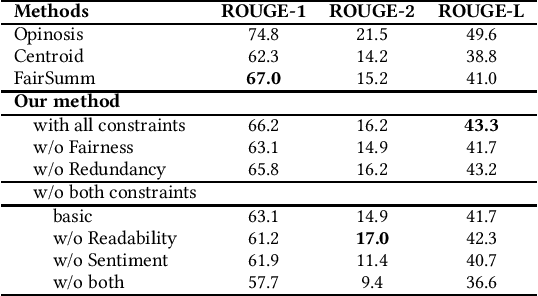
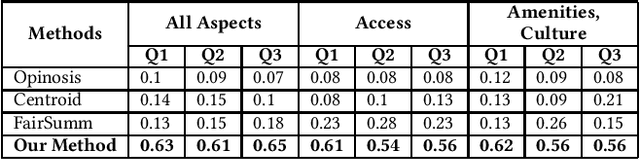
Manually extracting relevant aspects and opinions from large volumes of user-generated text is a time-consuming process. Summaries, on the other hand, help readers with limited time budgets to quickly consume the key ideas from the data. State-of-the-art approaches for multi-document summarization, however, do not consider user preferences while generating summaries. In this work, we argue the need and propose a solution for generating personalized aspect-based opinion summaries from large collections of online tourist reviews. We let our readers decide and control several attributes of the summary such as the length and specific aspects of interest among others. Specifically, we take an unsupervised approach to extract coherent aspects from tourist reviews posted on TripAdvisor. We then propose an Integer Linear Programming (ILP) based extractive technique to select an informative subset of opinions around the identified aspects while respecting the user-specified values for various control parameters. Finally, we evaluate and compare our summaries using crowdsourcing and ROUGE-based metrics and obtain competitive results.
StationPlot: A New Non-stationarity Quantification Tool for Detection of Epileptic Seizures
Nov 10, 2018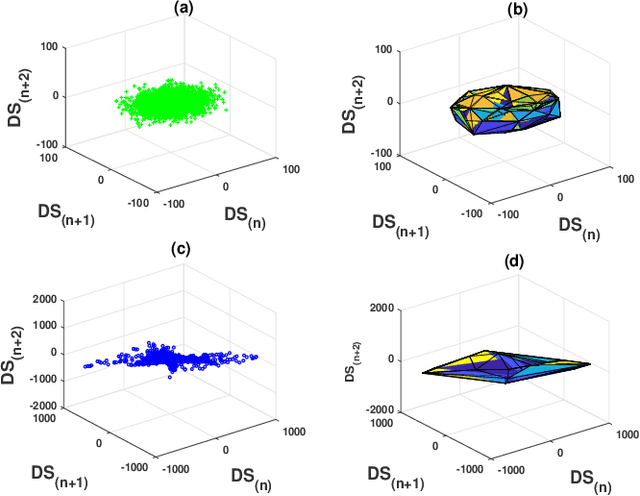
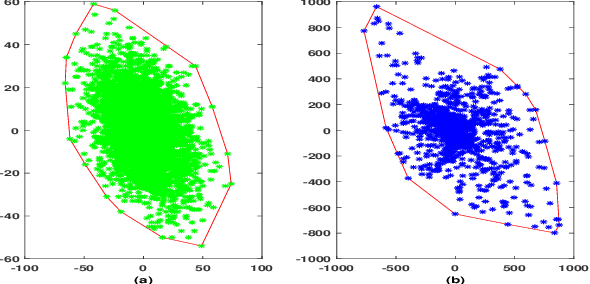

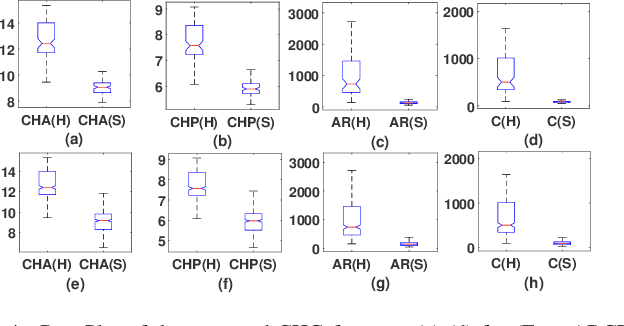
A novel non-stationarity visualization tool known as StationPlot is developed for deciphering the chaotic behavior of a dynamical time series. A family of analytic measures enumerating geometrical aspects of the non-stationarity & degree of variability is formulated by convex hull geometry (CHG) on StationPlot. In the Euclidean space, both trend-stationary (TS) & difference-stationary (DS) perturbations are comprehended by the asymmetric structure of StationPlot's region of interest (ROI). The proposed method is experimentally validated using EEG signals, where it comprehend the relative temporal evolution of neural dynamics & its non-stationary morphology, thereby exemplifying its diagnostic competence for seizure activity (SA) detection. Experimental results & analysis-of-Variance (ANOVA) on the extracted CHG features demonstrates better classification performances as compared to the existing shallow feature based state-of-the-art & validates its efficacy as geometry-rich discriminative descriptors for signal processing applications.