 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe RLHF Beyond Expectation: Stochastic Dominance for Universal Spectral Risk Control
Mar 11, 2026Safe Reinforcement Learning from Human Feedback (RLHF) typically enforces safety through expected cost constraints, but the expectation captures only a single statistic of the cost distribution and fails to account for distributional uncertainty, particularly under heavy tails or rare catastrophic events. This limitation is problematic when robustness and risk sensitivity are critical. Stochastic dominance offers a principled alternative by comparing entire cost distributions rather than just their averages, enabling direct control over tail risks and potential out-of-distribution failures that expectation-based constraints may overlook. In this work, we propose Risk-sensitive Alignment via Dominance (RAD), a novel alignment framework that replaces scalar expected cost constraints with First-Order Stochastic Dominance (FSD) constraints. We operationalize this constraint by comparing the target policy's cost distribution to that of a reference policy within an Optimal Transport (OT) framework, using entropic regularization and Sinkhorn iterations to obtain a differentiable and computationally efficient objective for stable end-to-end optimization. Furthermore, we introduce quantile-weighted FSD constraints and show that weighted FSD universally controls a broad class of Spectral Risk Measures (SRMs), so that improvements under weighted dominance imply guaranteed improvements in the corresponding spectral risk. This provides a principled mechanism for tuning a model's risk profile via the quantile weighting function. Empirical results demonstrate that RAD improves harmlessness over baselines while remaining competitive in helpfulness, and exhibits greater robustness on out-of-distribution harmlessness evaluations.
No-regret Algorithms for Fair Resource Allocation
Mar 11, 2023



We consider a fair resource allocation problem in the no-regret setting against an unrestricted adversary. The objective is to allocate resources equitably among several agents in an online fashion so that the difference of the aggregate $\alpha$-fair utilities of the agents between an optimal static clairvoyant allocation and that of the online policy grows sub-linearly with time. The problem is challenging due to the non-additive nature of the $\alpha$-fairness function. Previously, it was shown that no online policy can exist for this problem with a sublinear standard regret. In this paper, we propose an efficient online resource allocation policy, called Online Proportional Fair (OPF), that achieves $c_\alpha$-approximate sublinear regret with the approximation factor $c_\alpha=(1-\alpha)^{-(1-\alpha)}\leq 1.445,$ for $0\leq \alpha < 1$. The upper bound to the $c_\alpha$-regret for this problem exhibits a surprising phase transition phenomenon. The regret bound changes from a power-law to a constant at the critical exponent $\alpha=\frac{1}{2}.$ As a corollary, our result also resolves an open problem raised by Even-Dar et al. [2009] on designing an efficient no-regret policy for the online job scheduling problem in certain parameter regimes. The proof of our results introduces new algorithmic and analytical techniques, including greedy estimation of the future gradients for non-additive global reward functions and bootstrapping adaptive regret bounds, which may be of independent interest.
Online Algorithms for Multiclass Classification using Partial Labels
Dec 24, 2019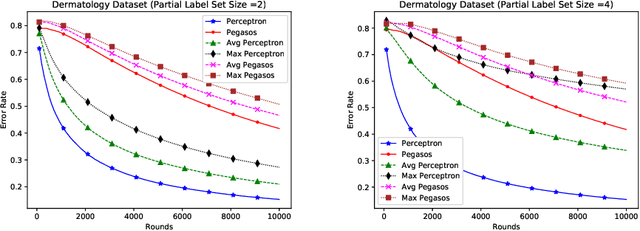
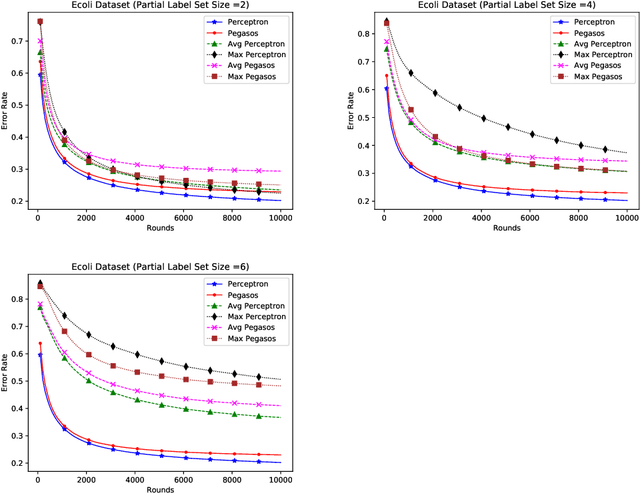
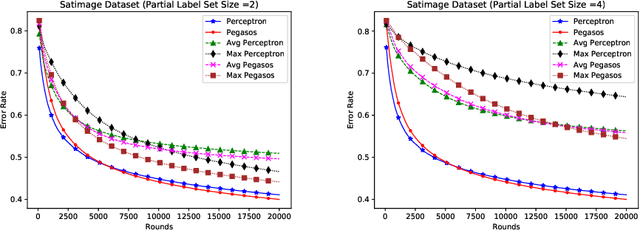
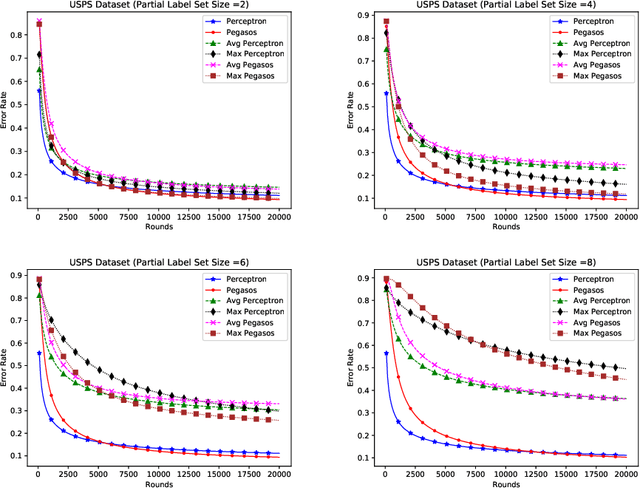
In this paper, we propose online algorithms for multiclass classification using partial labels. We propose two variants of Perceptron called Avg Perceptron and Max Perceptron to deal with the partial labeled data. We also propose Avg Pegasos and Max Pegasos, which are extensions of Pegasos algorithm. We also provide mistake bounds for Avg Perceptron and regret bound for Avg Pegasos. We show the effectiveness of the proposed approaches by experimenting on various datasets and comparing them with the standard Perceptron and Pegasos.