 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Guided Exploratory Trajectory Optimization for Sampling-Based Model Predictive Control
Apr 13, 2026Trajectory optimization depends heavily on initialization. In particular, sampling-based approaches are highly sensitive to initial solutions, and limited exploration frequently leads them to converge to local minima in complex environments. We present Uncertainty Guided Exploratory Trajectory Optimization (UGE-TO), a trajectory optimization algorithm that generates well-separated samples to achieve a better coverage of the configuration space. UGE-TO represents trajectories as probability distributions induced by uncertainty ellipsoids. Unlike sampling-based approaches that explore only in the action space, this representation captures the effects of both system dynamics and action selection. By incorporating the impact of dynamics, in addition to the action space, into our distributions, our method enhances trajectory diversity by enforcing distributional separation via the Hellinger distance between them. It enables a systematic exploration of the configuration space and improves robustness against local minima. Further, we present UGE-MPC, which integrates UGE-TO into sampling-based model predictive controller methods. Experiments demonstrate that UGE-MPC achieves higher exploration and faster convergence in trajectory optimization compared to baselines under the same sampling budget, achieving 72.1% faster convergence in obstacle-free environments and 66% faster convergence with a 6.7% higher success rate in the cluttered environment compared to the best-performing baseline. Additionally, we validate the approach through a range of simulation scenarios and real-world experiments. Our results indicate that UGE-MPC has higher success rates and faster convergence, especially in environments that demand significant deviations from nominal trajectories to avoid failures. The project and code are available at https://ogpoyrazoglu.github.io/cuniform_sampling/.
VisDiff: SDF-Guided Polygon Generation for Visibility Reconstruction and Recognition
Oct 07, 2024The capability to learn latent representations plays a key role in the effectiveness of recent machine learning methods. An active frontier in representation learning is understanding representations for combinatorial structures which may not admit well-behaved local neighborhoods or distance functions. For example, for polygons, slightly perturbing vertex locations might lead to significant changes in their combinatorial structure and may even lead to invalid polygons. In this paper, we investigate representations to capture the underlying combinatorial structures of polygons. Specifically, we study the open problem of Visibility Reconstruction: Given a visibility graph G, construct a polygon P whose visibility graph is G. We introduce VisDiff, a novel diffusion-based approach to reconstruct a polygon from its given visibility graph G. Our method first estimates the signed distance function (SDF) of P from G. Afterwards, it extracts ordered vertex locations that have the pairwise visibility relationship given by the edges of G. Our main insight is that going through the SDF significantly improves learning for reconstruction. In order to train VisDiff, we make two main contributions: (1) We design novel loss components for computing the visibility in a differentiable manner and (2) create a carefully curated dataset. We use this dataset to benchmark our method and achieve 21% improvement in F1-Score over standard methods. We also demonstrate effective generalization to out-of-distribution polygon types and show that learning a generative model allows us to sample the set of polygons with a given visibility graph. Finally, we extend our method to the related combinatorial problem of reconstruction from a triangulation. We achieve 95% classification accuracy of triangulation edges and a 4% improvement in Chamfer distance compared to current architectures.
Spam filtering on forums: A synthetic oversampling based approach for imbalanced data classification
Sep 10, 2019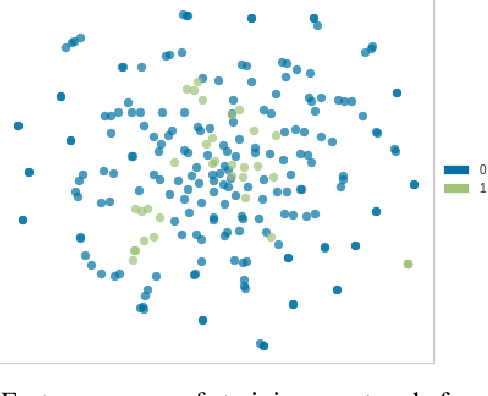
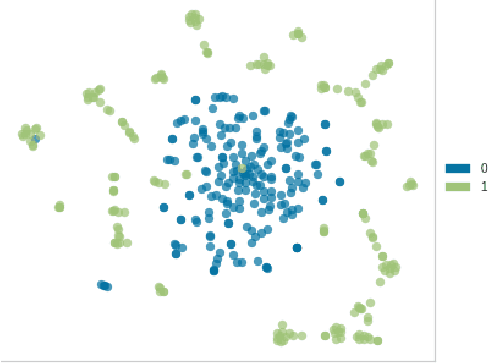
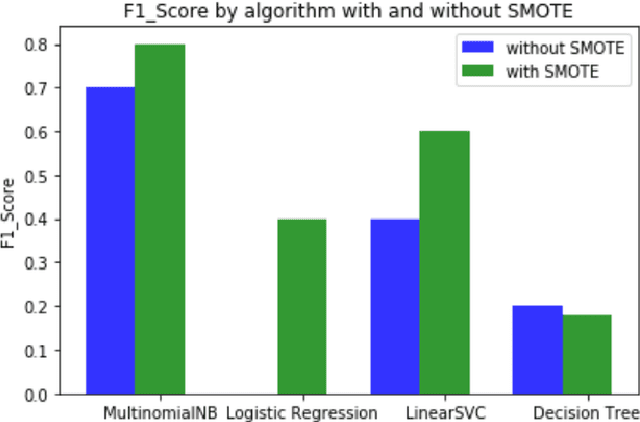
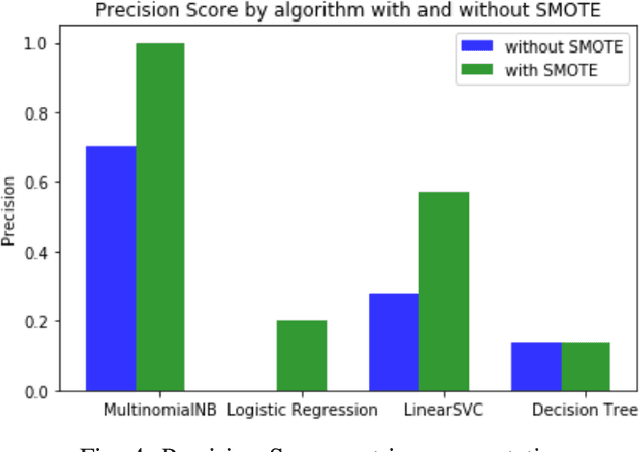
Forums play an important role in providing a platform for community interaction. The introduction of irrelevant content or spam by individuals for commercial and social gains tends to degrade the professional experience presented to the forum users. Automated moderation of the relevancy of posted content is desired. Machine learning is used for text classification and finds applications in spam email detection, fraudulent transaction detection etc. The balance of classes in training data is essential in the case of classification algorithms to make the learning efficient and accurate. However, in the case of forums, the spam content is sparse compared to the relevant content giving rise to a bias towards the latter while training. A model trained on such biased data will fail to classify a spam sample. An approach based on Synthetic Minority Over-sampling Technique(SMOTE) is presented in this paper to tackle imbalanced training data. It involves synthetically creating new minority class samples from the existing ones until balance in data is achieved. The enhanced data is then passed through various classifiers for which the performance is recorded. The results were analyzed on the data of forums of Spoken Tutorial, IIT Bombay over standard performance metrics and revealed that models trained after Synthetic Minority oversampling outperform the ones trained on imbalanced data by substantial margins. An empirical comparison of the results obtained by both SMOTE and without SMOTE for various supervised classification algorithms have been presented in this paper. Synthetic oversampling proves to be a critical technique for achieving uniform class distribution which in turn yields commendable results in text classification. The presented approach can be further extended to content categorization on educational websites thus helping to improve the overall digital learning experience.