 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-paced ensemble learning for speech and audio classification
Mar 22, 2021
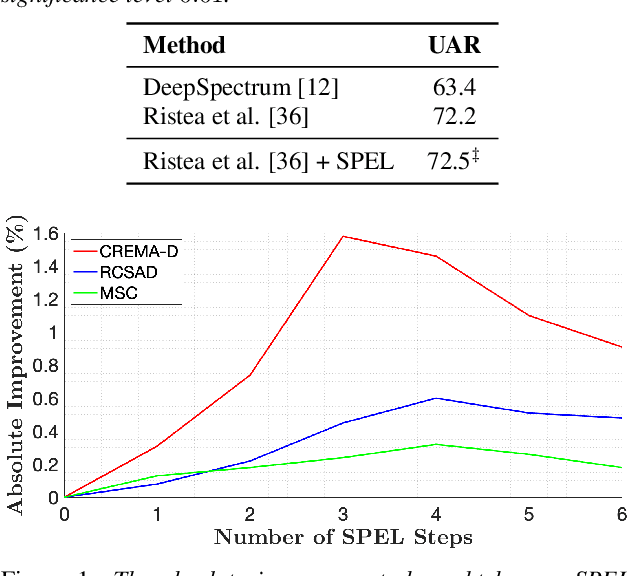
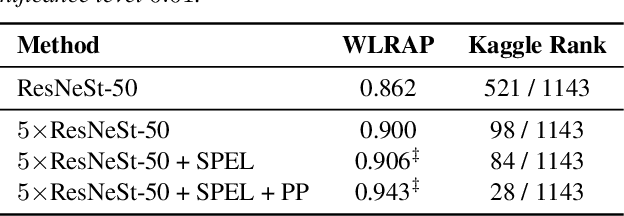
Combining multiple machine learning models into an ensemble is known to provide superior performance levels compared to the individual components forming the ensemble. This is because models can complement each other in taking better decisions. Instead of just combining the models, we propose a self-paced ensemble learning scheme in which models learn from each other over several iterations. During the self-paced learning process based on pseudo-labeling, in addition to improving the individual models, our ensemble also gains knowledge about the target domain. To demonstrate the generality of our self-paced ensemble learning (SPEL) scheme, we conduct experiments on three audio tasks. Our empirical results indicate that SPEL significantly outperforms the baseline ensemble models. We also show that applying self-paced learning on individual models is less effective, illustrating the idea that models in the ensemble actually learn from each other.
UnibucKernel: Geolocating Swiss German Jodels Using Ensemble Learning
Feb 26, 2021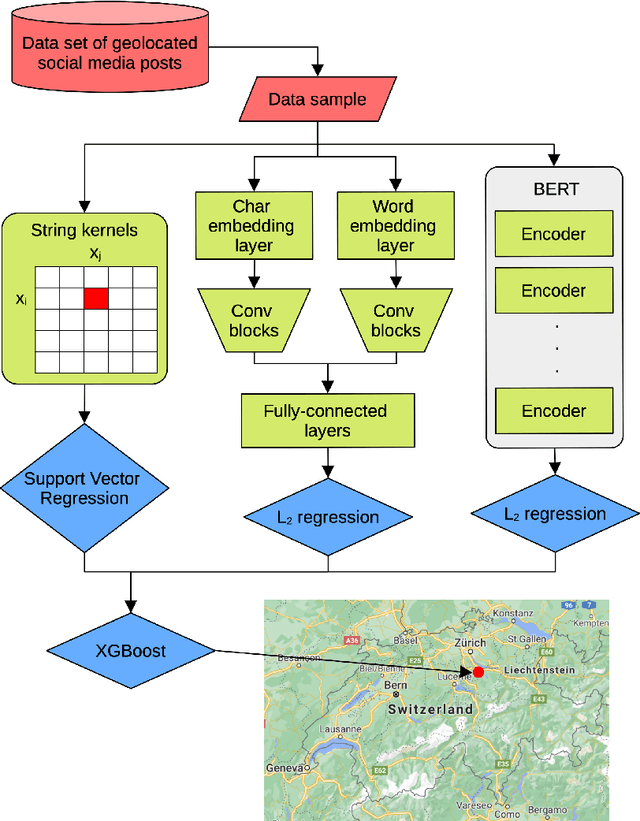
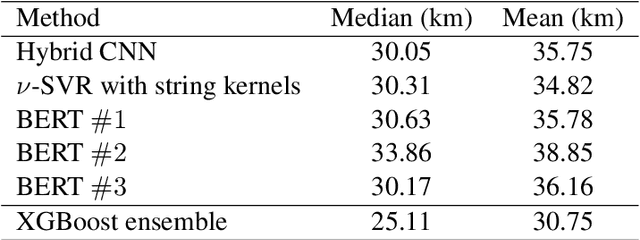
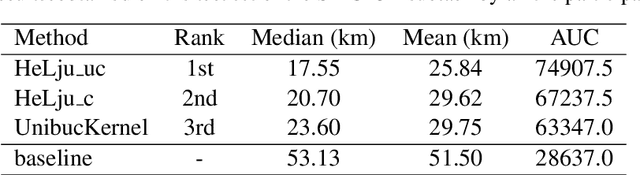
In this work, we describe our approach addressing the Social Media Variety Geolocation task featured in the 2021 VarDial Evaluation Campaign. We focus on the second subtask, which is based on a data set formed of approximately 30 thousand Swiss German Jodels. The dialect identification task is about accurately predicting the latitude and longitude of test samples. We frame the task as a double regression problem, employing an XGBoost meta-learner with the combined power of a variety of machine learning approaches to predict both latitude and longitude. The models included in our ensemble range from simple regression techniques, such as Support Vector Regression, to deep neural models, such as a hybrid neural network and a neural transformer. To minimize the prediction error, we approach the problem from a few different perspectives and consider various types of features, from low-level character n-grams to high-level BERT embeddings. The XGBoost ensemble resulted from combining the power of the aforementioned methods achieves a median distance of 23.6 km on the test data, which places us on the third place in the ranking, at a difference of 6.05 km and 2.9 km from the submissions on the first and second places, respectively.
Unsupervised Medical Image Alignment with Curriculum Learning
Feb 20, 2021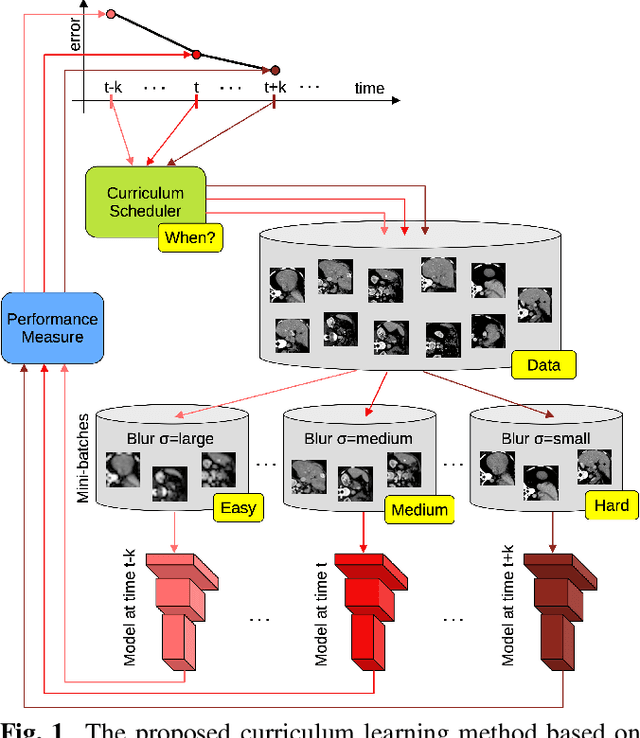
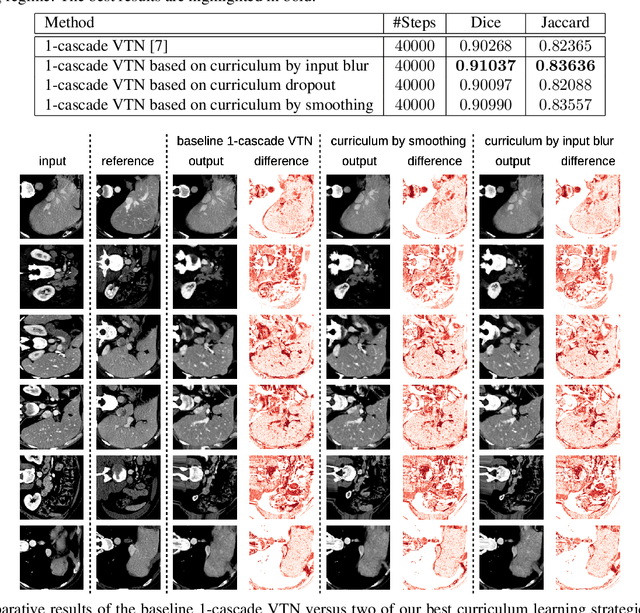
We explore different curriculum learning methods for training convolutional neural networks on the task of deformable pairwise 3D medical image registration. To the best of our knowledge, we are the first to attempt to improve performance by training medical image registration models using curriculum learning, starting from an easy training setup in the first training stages, and gradually increasing the complexity of the setup. On the one hand, we consider two existing curriculum learning approaches, namely curriculum dropout and curriculum by smoothing. On the other hand, we propose a novel and simple strategy to achieve curriculum, namely to use purposely blurred images at the beginning, then gradually transit to sharper images in the later training stages. Our experiments with an underlying state-of-the-art deep learning model show that curriculum learning can lead to superior results compared to conventional training.
Curriculum Learning: A Survey
Jan 25, 2021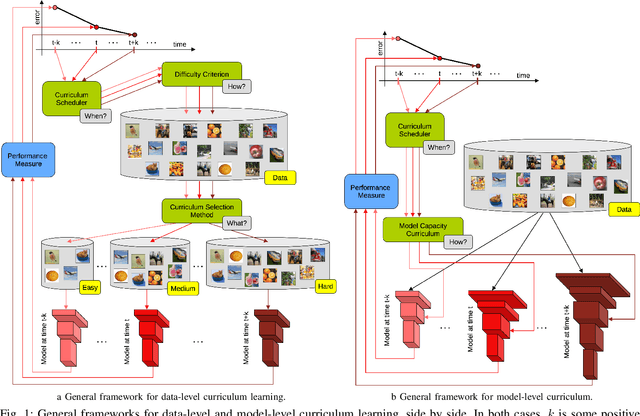
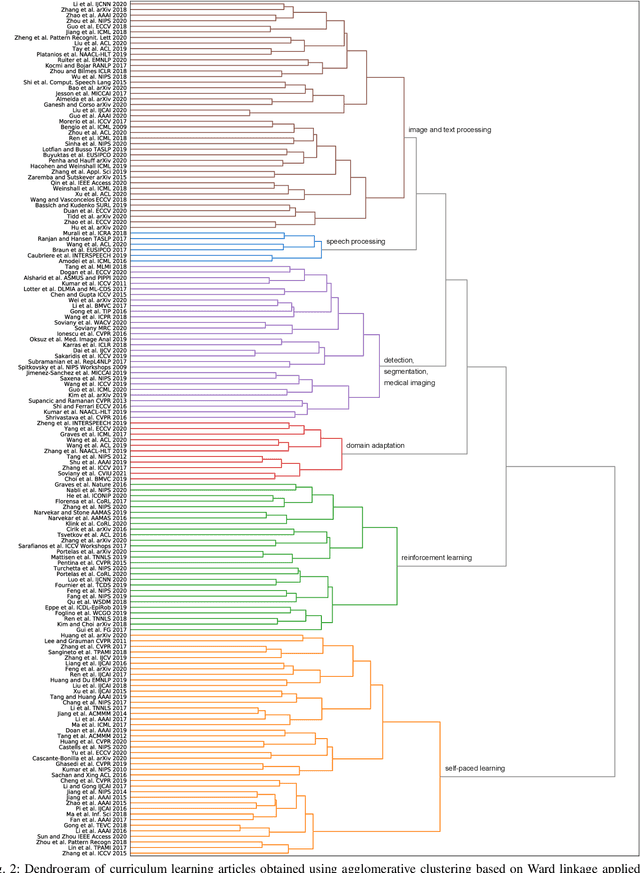
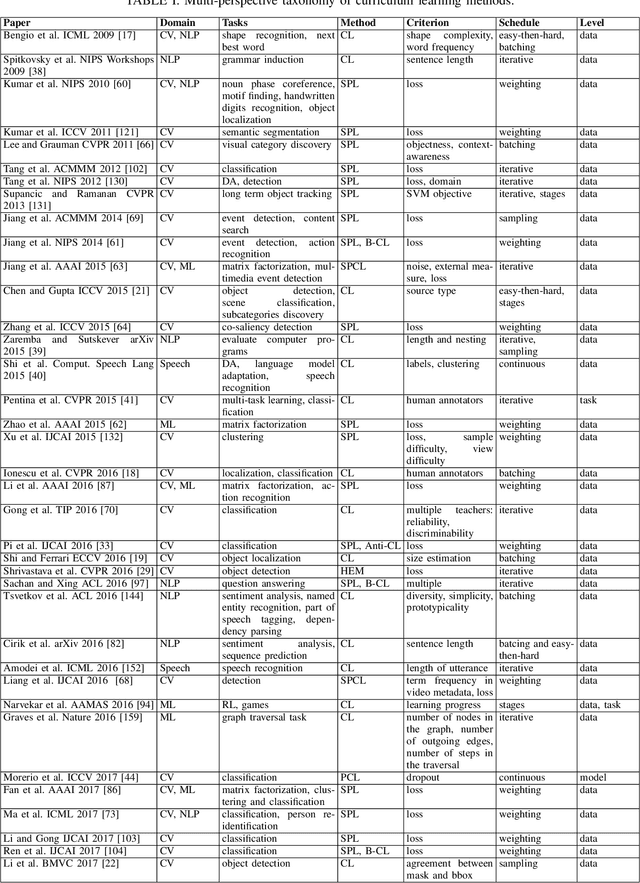
Training machine learning models in a meaningful order, from the easy samples to the hard ones, using curriculum learning can provide performance improvements over the standard training approach based on random data shuffling, without any additional computational costs. Curriculum learning strategies have been successfully employed in all areas of machine learning, in a wide range of tasks. However, the necessity of finding a way to rank the samples from easy to hard, as well as the right pacing function for introducing more difficult data can limit the usage of the curriculum approaches. In this survey, we show how these limits have been tackled in the literature, and we present different curriculum learning instantiations for various tasks in machine learning. We construct a multi-perspective taxonomy of curriculum learning approaches by hand, considering various classification criteria. We further build a hierarchical tree of curriculum learning methods using an agglomerative clustering algorithm, linking the discovered clusters with our taxonomy. At the end, we provide some interesting directions for future work.
Clustering Word Embeddings with Self-Organizing Maps. Application on LaRoSeDa -- A Large Romanian Sentiment Data Set
Jan 11, 2021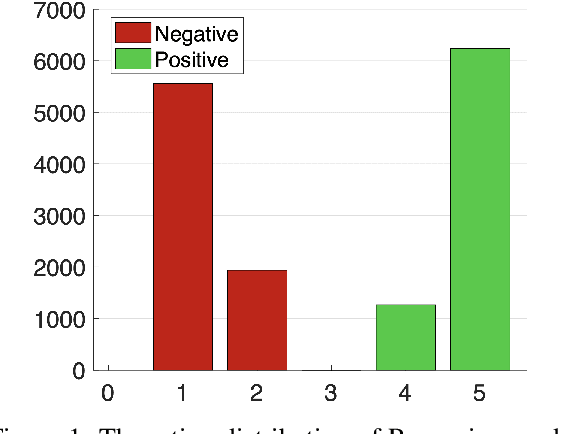
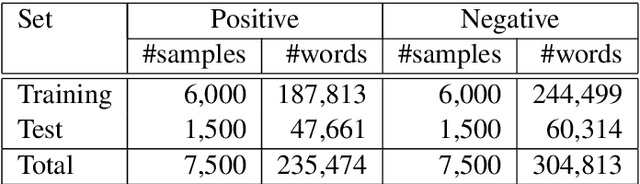
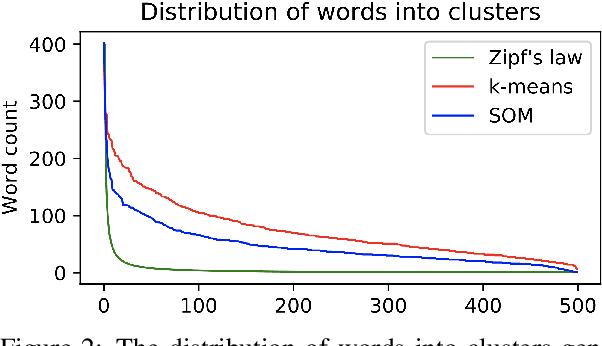
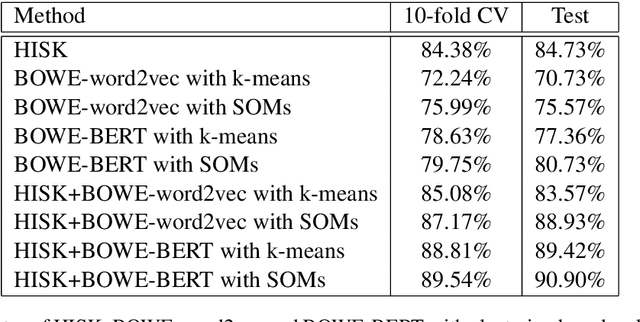
Romanian is one of the understudied languages in computational linguistics, with few resources available for the development of natural language processing tools. In this paper, we introduce LaRoSeDa, a Large Romanian Sentiment Data Set, which is composed of 15,000 positive and negative reviews collected from one of the largest Romanian e-commerce platforms. We employ two sentiment classification methods as baselines for our new data set, one based on low-level features (character n-grams) and one based on high-level features (bag-of-word-embeddings generated by clustering word embeddings with k-means). As an additional contribution, we replace the k-means clustering algorithm with self-organizing maps (SOMs), obtaining better results because the generated clusters of word embeddings are closer to the Zipf's law distribution, which is known to govern natural language. We also demonstrate the generalization capacity of using SOMs for the clustering of word embeddings on another recently-introduced Romanian data set, for text categorization by topic.
Natural vs Balanced Distribution in Deep Learning on Whole Slide Images for Cancer Detection
Dec 21, 2020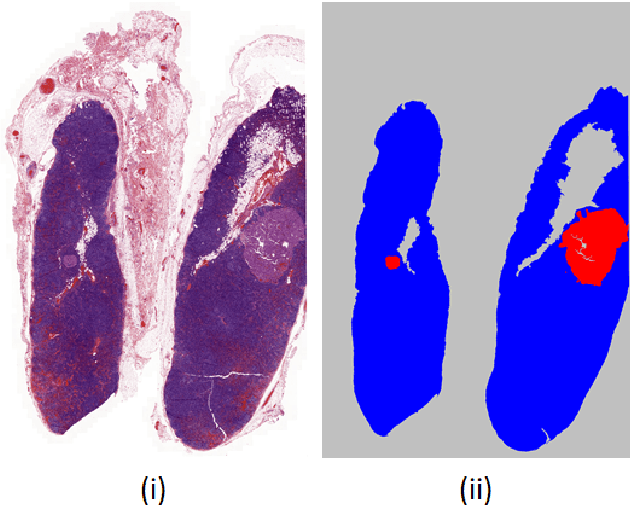


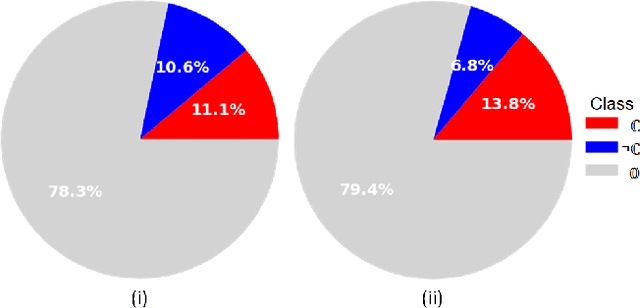
The class distribution of data is one of the factors that regulates the performance of machine learning models. However, investigations on the impact of different distributions available in the literature are very few, sometimes absent for domain-specific tasks. In this paper, we analyze the impact of natural and balanced distributions of the training set in deep learning (DL) models applied on histological images, also known as whole slide images (WSIs). WSIs are considered as the gold standard for cancer diagnosis. In recent years, researchers have turned their attention to DL models to automate and accelerate the diagnosis process. In the training of such DL models, filtering out the non-regions-of-interest from the WSIs and adopting an artificial distribution (usually, a balanced distribution) is a common trend. In our analysis, we show that keeping the WSIs data in their usual distribution (which we call natural distribution) for DL training produces fewer false positives (FPs) with comparable false negatives (FNs) than the artificially-obtained balanced distribution. We conduct an empirical comparative study with 10 random folds for each distribution, comparing the resulting average performance levels in terms of five different evaluation metrics. Experimental results show the effectiveness of the natural distribution over the balanced one across all the evaluation metrics.
Anomaly Detection in Video via Self-Supervised and Multi-Task Learning
Nov 15, 2020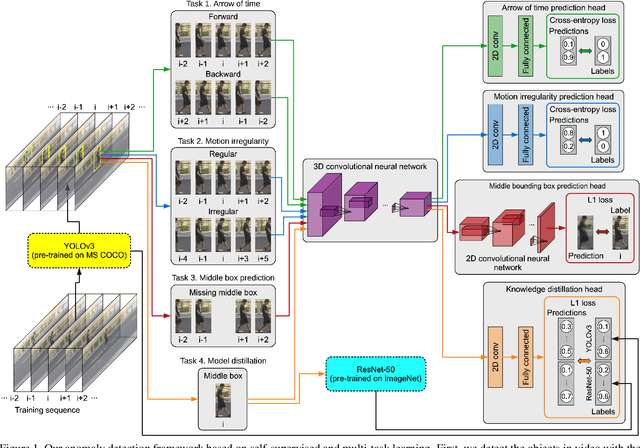
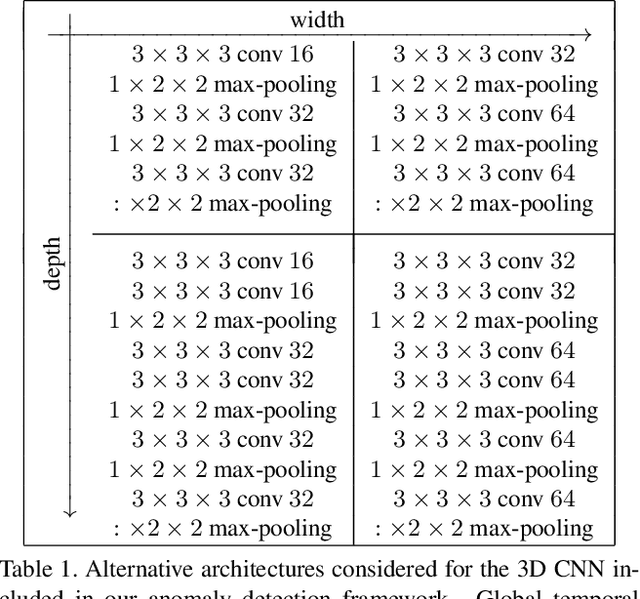
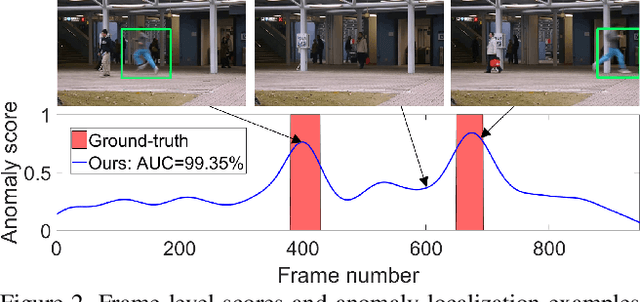
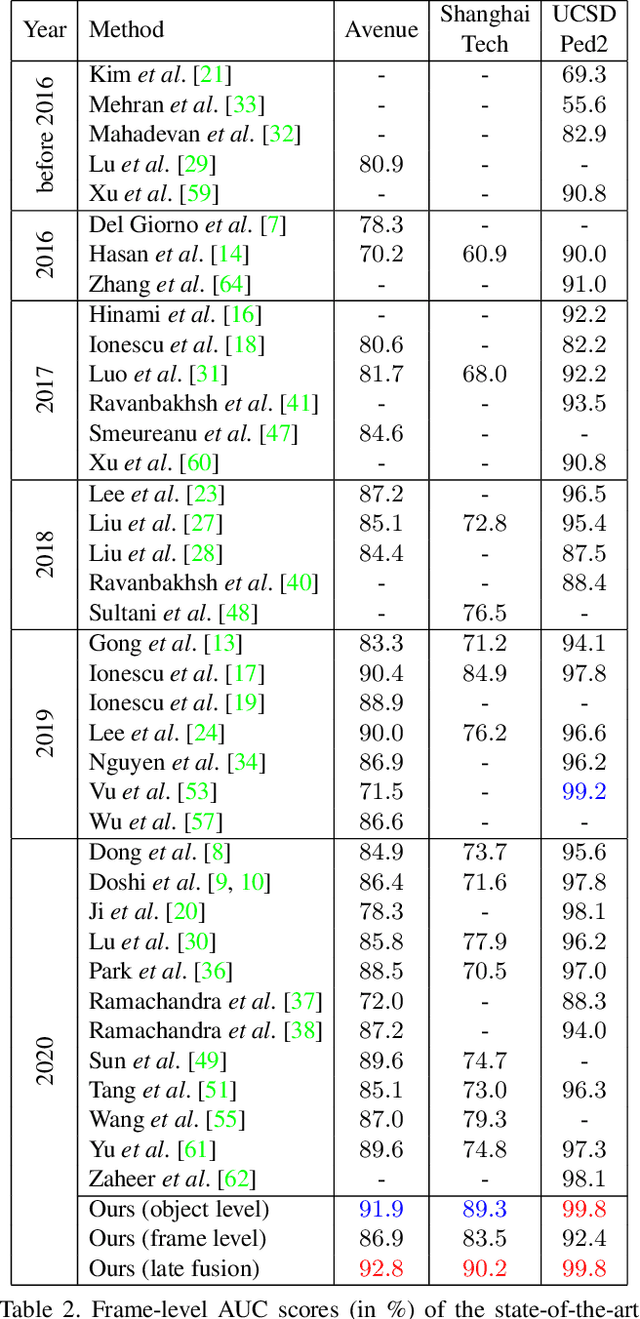
Anomaly detection in video is a challenging computer vision problem. Due to the lack of anomalous events at training time, anomaly detection requires the design of learning methods without full supervision. In this paper, we approach anomalous event detection in video through self-supervised and multi-task learning at the object level. We first utilize a pre-trained detector to detect objects. Then, we train a 3D convolutional neural network to produce discriminative anomaly-specific information by jointly learning multiple proxy tasks: three self-supervised and one based on knowledge distillation. The self-supervised tasks are: (i) discrimination of forward/backward moving objects (arrow of time), (ii) discrimination of objects in consecutive/intermittent frames (motion irregularity) and (iii) reconstruction of object-specific appearance information. The knowledge distillation task takes into account both classification and detection information, generating large prediction discrepancies between teacher and student models when anomalies occur. To the best of our knowledge, we are the first to approach anomalous event detection in video as a multi-task learning problem, integrating multiple self-supervised and knowledge distillation proxy tasks in a single architecture. Our lightweight architecture outperforms the state-of-the-art methods on three benchmarks: Avenue, ShanghaiTech and UCSD Ped2. Additionally, we perform an ablation study demonstrating the importance of integrating self-supervised learning and normality-specific distillation in a multi-task learning setting.
Black-Box Ripper: Copying black-box models using generative evolutionary algorithms
Oct 21, 2020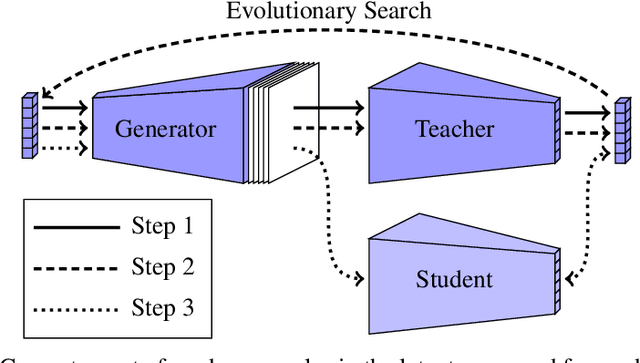
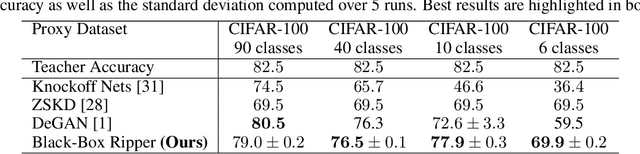
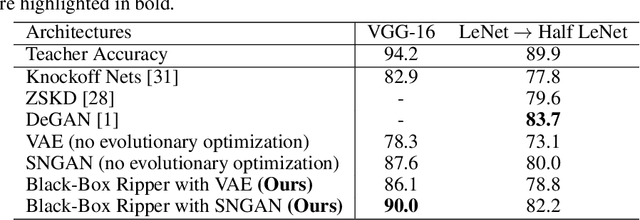

We study the task of replicating the functionality of black-box neural models, for which we only know the output class probabilities provided for a set of input images. We assume back-propagation through the black-box model is not possible and its training images are not available, e.g. the model could be exposed only through an API. In this context, we present a teacher-student framework that can distill the black-box (teacher) model into a student model with minimal accuracy loss. To generate useful data samples for training the student, our framework (i) learns to generate images on a proxy data set (with images and classes different from those used to train the black-box) and (ii) applies an evolutionary strategy to make sure that each generated data sample exhibits a high response for a specific class when given as input to the black box. Our framework is compared with several baseline and state-of-the-art methods on three benchmark data sets. The empirical evidence indicates that our model is superior to the considered baselines. Although our method does not back-propagate through the black-box network, it generally surpasses state-of-the-art methods that regard the teacher as a glass-box model. Our code is available at: https://github.com/antoniobarbalau/black-box-ripper.
Automotive Radar Interference Mitigation with Unfolded Robust PCA based on Residual Overcomplete Auto-Encoder Blocks
Oct 14, 2020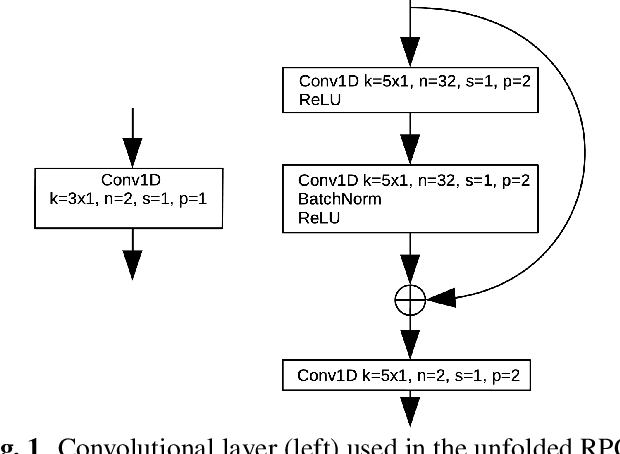
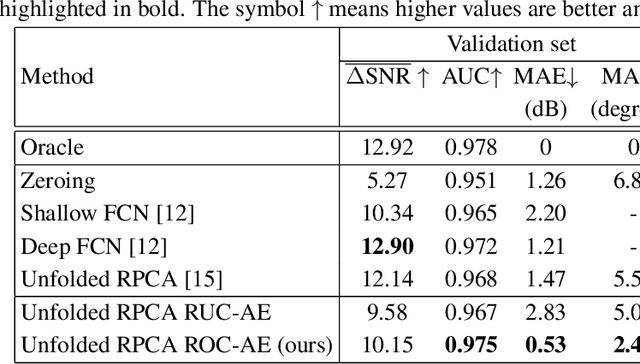
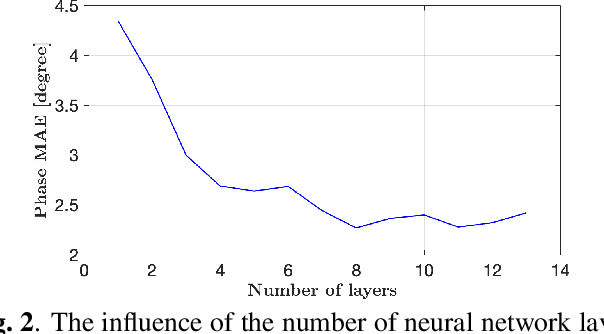
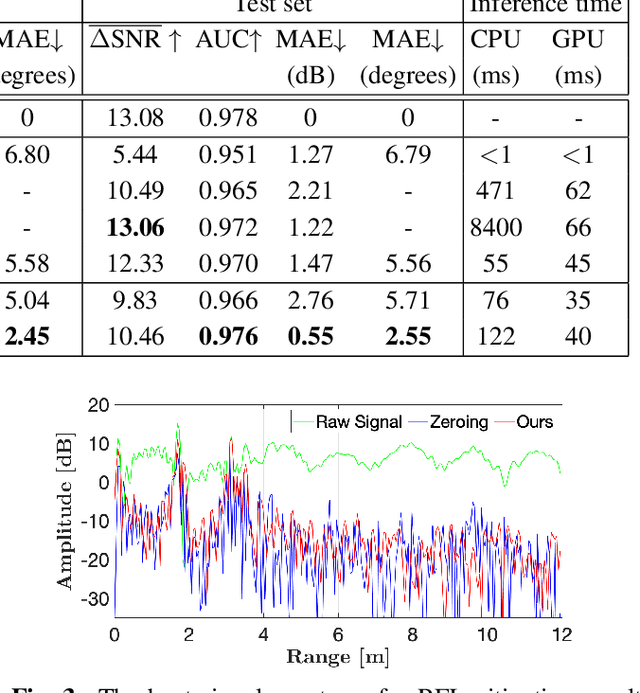
Deep learning methods for automotive radar interference mitigation can succesfully estimate the amplitude of targets, but fail to recover the phase of the respective targets. In this paper, we propose an efficient and effective technique based on unfolded robust Principal Component Analysis (RPCA) that is able to estimate both amplitude and phase in the presence of interference. Our contribution consists in introducing residual overcomplete auto-encoder (ROC-AE) blocks into the recurrent architecture of unfolded RPCA, which results in a deeper model that significantly outperforms unfolded RPCA as well as other deep learning models.
Combining Deep Learning and String Kernels for the Localization of Swiss German Tweets
Oct 07, 2020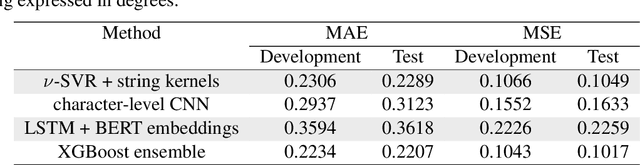
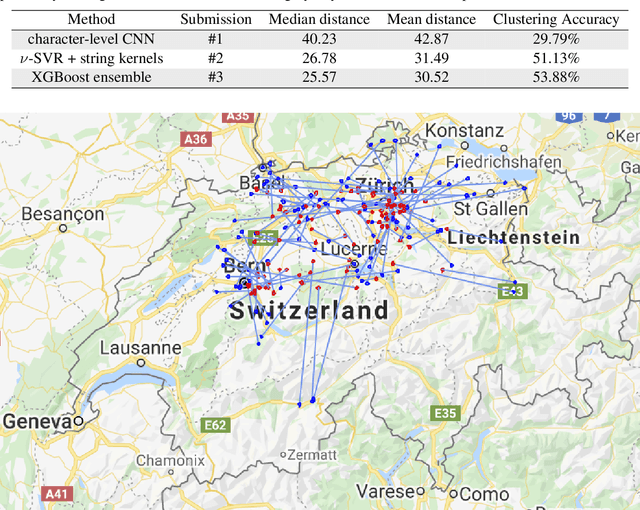
In this work, we introduce the methods proposed by the UnibucKernel team in solving the Social Media Variety Geolocation task featured in the 2020 VarDial Evaluation Campaign. We address only the second subtask, which targets a data set composed of nearly 30 thousand Swiss German Jodels. The dialect identification task is about accurately predicting the latitude and longitude of test samples. We frame the task as a double regression problem, employing a variety of machine learning approaches to predict both latitude and longitude. From simple models for regression, such as Support Vector Regression, to deep neural networks, such as Long Short-Term Memory networks and character-level convolutional neural networks, and, finally, to ensemble models based on meta-learners, such as XGBoost, our interest is focused on approaching the problem from a few different perspectives, in an attempt to minimize the prediction error. With the same goal in mind, we also considered many types of features, from high-level features, such as BERT embeddings, to low-level features, such as characters n-grams, which are known to provide good results in dialect identification. Our empirical results indicate that the handcrafted model based on string kernels outperforms the deep learning approaches. Nevertheless, our best performance is given by the ensemble model that combines both handcrafted and deep learning models.