 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoverage, Not Averages: Semantic Stratification for Trustworthy Retrieval Evaluation
Apr 22, 2026Retrieval quality is the primary bottleneck for accuracy and robustness in retrieval-augmented generation (RAG). Current evaluation relies on heuristically constructed query sets, which introduce a hidden intrinsic bias. We formalize retrieval evaluation as a statistical estimation problem, showing that metric reliability is fundamentally limited by the evaluation-set construction. We further introduce \emph{semantic stratification}, which grounds evaluation in corpus structure by organizing documents into an interpretable global space of entity-based clusters and systematically generating queries for missing strata. This yields (1) formal semantic coverage guarantees across retrieval regimes and (2) interpretable visibility into retrieval failure modes. Experiments across multiple benchmarks and retrieval methods validate our framework. The results expose systematic coverage gaps, identify structural signals that explain variance in retrieval performance, and show that stratified evaluation yields more stable and transparent assessments while supporting more trustworthy decision-making than aggregate metrics.
Identifying Actions for Sound Event Classification
Apr 26, 2021
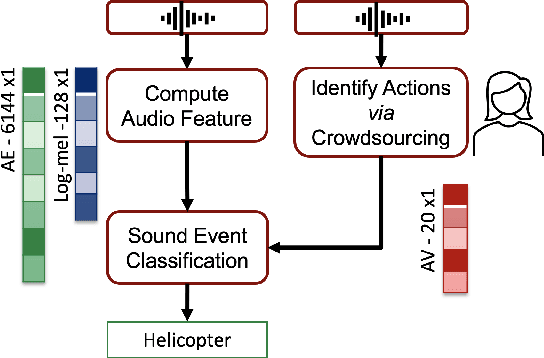
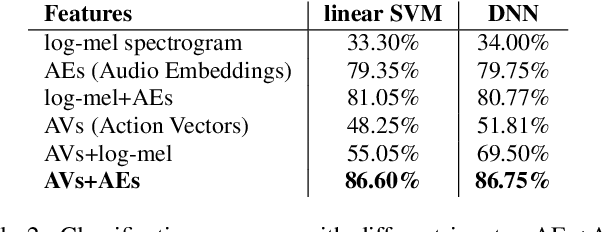

In Psychology, actions are paramount for humans to perceive and separate sound events. In Machine Learning (ML), action recognition achieves high accuracy; however, it has not been asked if identifying actions can benefit Sound Event Classification (SEC), as opposed to mapping the audio directly to a sound event. Therefore, we propose a new Psychology-inspired approach for SEC that includes identification of actions via human listeners. To achieve this goal, we used crowdsourcing to have listeners identify 20 actions that in isolation or in combination may have produced any of the 50 sound events in the well-studied dataset ESC-50. The resulting annotations for each audio recording relate actions to a database of sound events for the first time~\footnote{Annotations will be released after revision.}. The annotations were used to create semantic representations called Action Vectors (AVs). We evaluated SEC by comparing the AVs with two types of audio features -- log-mel spectrograms and state of the art audio embeddings. Because audio features and AVs capture different abstractions of the acoustic content, we combined them and achieved one of the highest reported accuracies (86.75%) in ESC-50, showing that Psychology-inspired approaches can improve SEC.