 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtended Gaze Following: Detecting Objects in Videos Beyond the Camera Field of View
Feb 28, 2019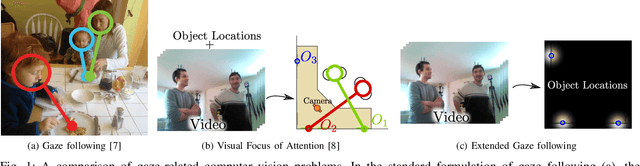
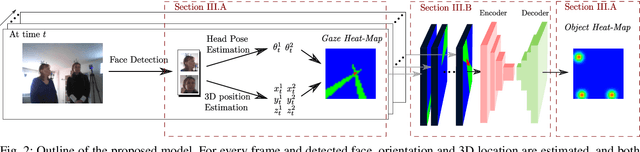
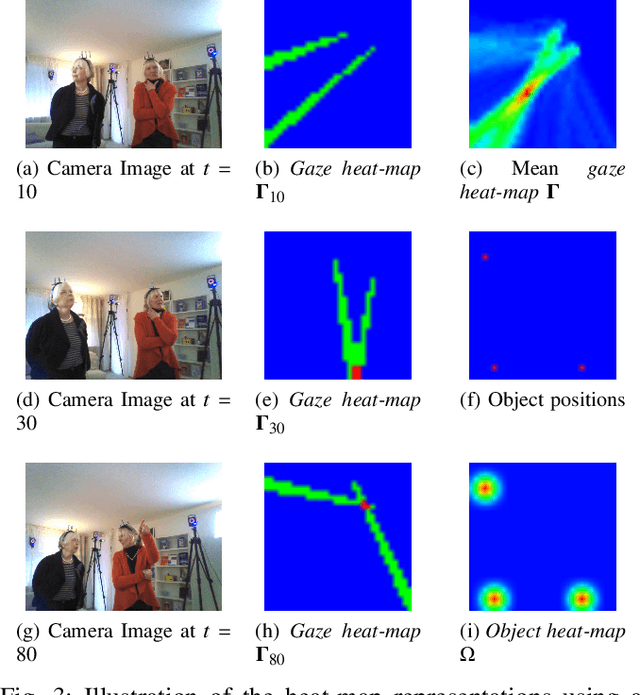
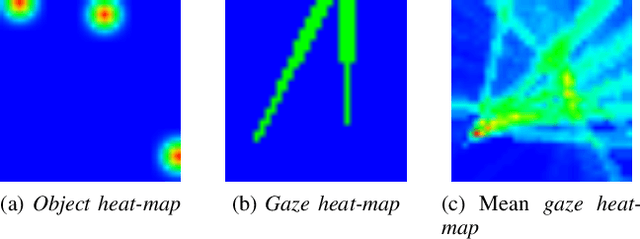
In this paper we address the problems of detecting objects of interest in a video and of estimating their locations, solely from the gaze directions of people present in the video. Objects can be indistinctly located inside or outside the camera field of view. We refer to this problem as extended gaze following. The contributions of the paper are the followings. First, we propose a novel spatial representation of the gaze directions adopting a top-view perspective. Second, we develop several convolutional encoder/decoder networks to predict object locations and compare them with heuristics and with classical learning-based approaches. Third, in order to train the proposed models, we generate a very large number of synthetic scenarios employing a probabilistic formulation. Finally, our methodology is empirically validated using a publicly available dataset.
Speech enhancement with variational autoencoders and alpha-stable distributions
Feb 08, 2019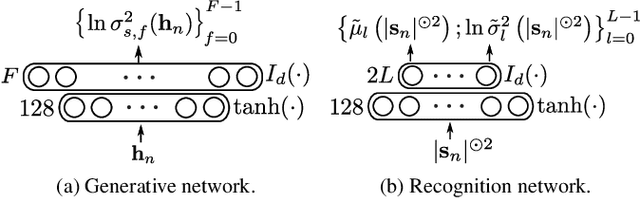
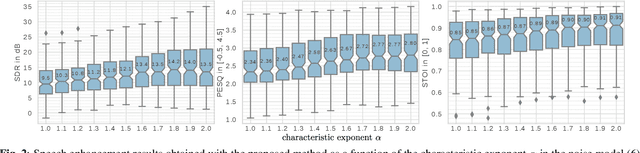
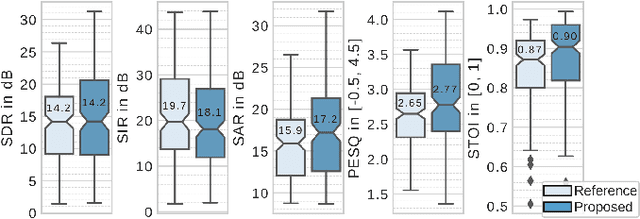
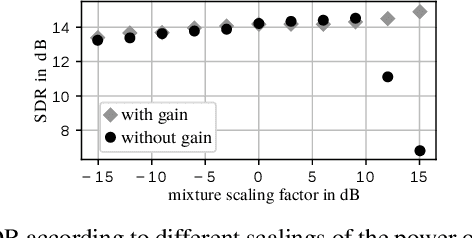
This paper focuses on single-channel semi-supervised speech enhancement. We learn a speaker-independent deep generative speech model using the framework of variational autoencoders. The noise model remains unsupervised because we do not assume prior knowledge of the noisy recording environment. In this context, our contribution is to propose a noise model based on alpha-stable distributions, instead of the more conventional Gaussian non-negative matrix factorization approach found in previous studies. We develop a Monte Carlo expectation-maximization algorithm for estimating the model parameters at test time. Experimental results show the superiority of the proposed approach both in terms of perceptual quality and intelligibility of the enhanced speech signal.
* 5 pages, 3 figures, audio examples and code available online : https://team.inria.fr/perception/research/icassp2019-asvae/. arXiv admin note: text overlap with arXiv:1811.06713
A variance modeling framework based on variational autoencoders for speech enhancement
Feb 05, 2019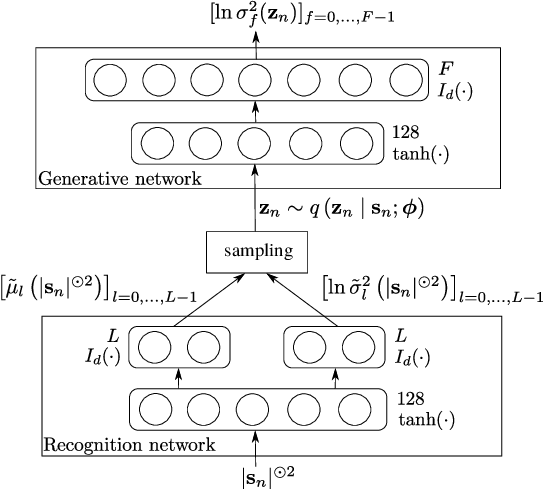
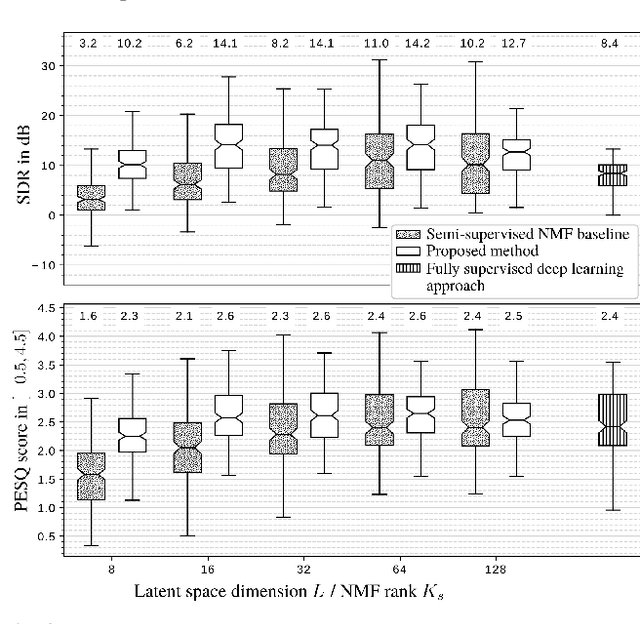
In this paper we address the problem of enhancing speech signals in noisy mixtures using a source separation approach. We explore the use of neural networks as an alternative to a popular speech variance model based on supervised non-negative matrix factorization (NMF). More precisely, we use a variational autoencoder as a speaker-independent supervised generative speech model, highlighting the conceptual similarities that this approach shares with its NMF-based counterpart. In order to be free of generalization issues regarding the noisy recording environments, we follow the approach of having a supervised model only for the target speech signal, the noise model being based on unsupervised NMF. We develop a Monte Carlo expectation-maximization algorithm for inferring the latent variables in the variational autoencoder and estimating the unsupervised model parameters. Experiments show that the proposed method outperforms a semi-supervised NMF baseline and a state-of-the-art fully supervised deep learning approach.
* 6 pages, 3 figures
Semi-supervised multichannel speech enhancement with variational autoencoders and non-negative matrix factorization
Nov 16, 2018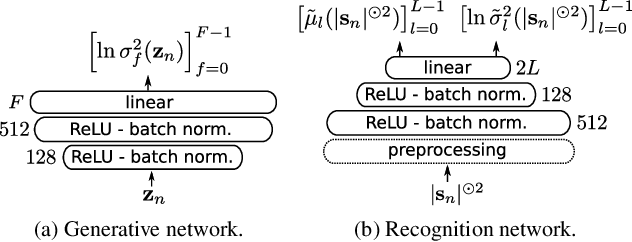
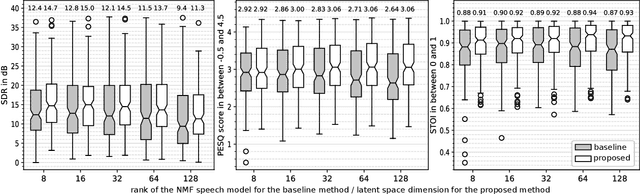
In this paper we address speaker-independent multichannel speech enhancement in unknown noisy environments. Our work is based on a well-established multichannel local Gaussian modeling framework. We propose to use a neural network for modeling the speech spectro-temporal content. The parameters of this supervised model are learned using the framework of variational autoencoders. The noisy recording environment is supposed to be unknown, so the noise spectro-temporal modeling remains unsupervised and is based on non-negative matrix factorization (NMF). We develop a Monte Carlo expectation-maximization algorithm and we experimentally show that the proposed approach outperforms its NMF-based counterpart, where speech is modeled using supervised NMF.
Variational Bayesian Inference for Audio-Visual Tracking of Multiple Speakers
Sep 28, 2018


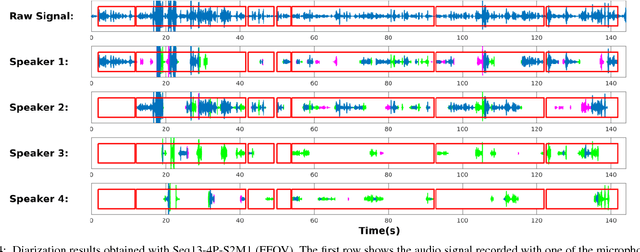
In this paper we address the problem of tracking multiple speakers via the fusion of visual and auditory information. We propose to exploit the complementary nature of these two modalities in order to accurately estimate smooth trajectories of the tracked persons, to deal with the partial or total absence of one of the modalities over short periods of time, and to estimate the acoustic status -- either speaking or silent -- of each tracked person along time. We propose to cast the problem at hand into a generative audio-visual fusion (or association) model formulated as a latent-variable temporal graphical model. This may well be viewed as the problem of maximizing the posterior joint distribution of a set of continuous and discrete latent variables given the past and current observations, which is intractable. We propose a variational inference model which amounts to approximate the joint distribution with a factorized distribution. The solution takes the form of a closed-form expectation maximization procedure. We describe in detail the inference algorithm, we evaluate its performance and we compare it with several baseline methods. These experiments show that the proposed audio-visual tracker performs well in informal meetings involving a time-varying number of people.
DeepGUM: Learning Deep Robust Regression with a Gaussian-Uniform Mixture Model
Aug 28, 2018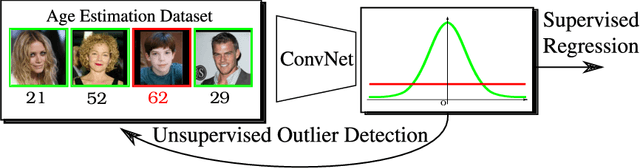
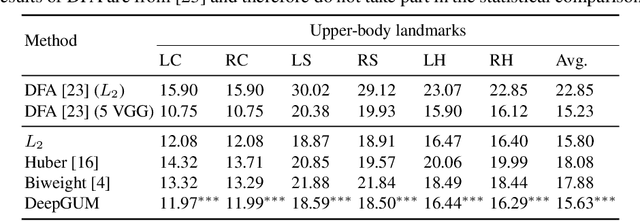
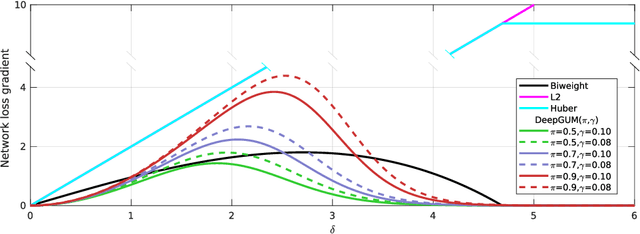
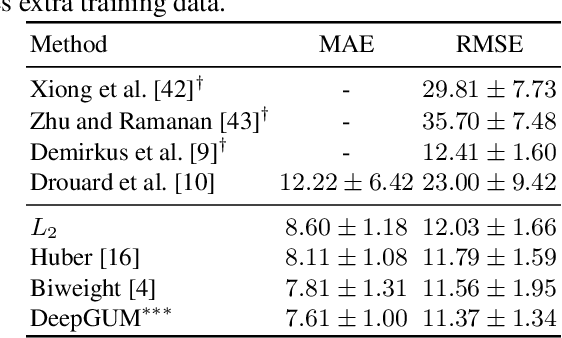
In this paper, we address the problem of how to robustly train a ConvNet for regression, or deep robust regression. Traditionally, deep regression employs the L2 loss function, known to be sensitive to outliers, i.e. samples that either lie at an abnormal distance away from the majority of the training samples, or that correspond to wrongly annotated targets. This means that, during back-propagation, outliers may bias the training process due to the high magnitude of their gradient. In this paper, we propose DeepGUM: a deep regression model that is robust to outliers thanks to the use of a Gaussian-uniform mixture model. We derive an optimization algorithm that alternates between the unsupervised detection of outliers using expectation-maximization, and the supervised training with cleaned samples using stochastic gradient descent. DeepGUM is able to adapt to a continuously evolving outlier distribution, avoiding to manually impose any threshold on the proportion of outliers in the training set. Extensive experimental evaluations on four different tasks (facial and fashion landmark detection, age and head pose estimation) lead us to conclude that our novel robust technique provides reliability in the presence of various types of noise and protection against a high percentage of outliers.
Neural Network Based Reinforcement Learning for Audio-Visual Gaze Control in Human-Robot Interaction
Apr 23, 2018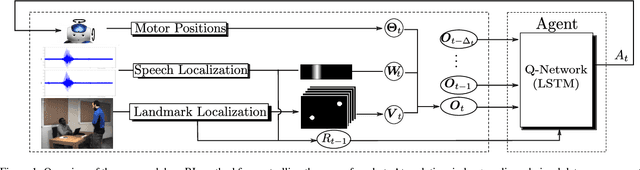
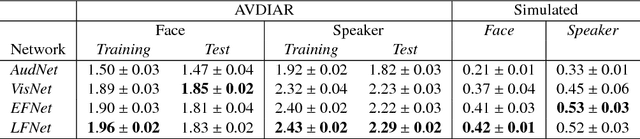
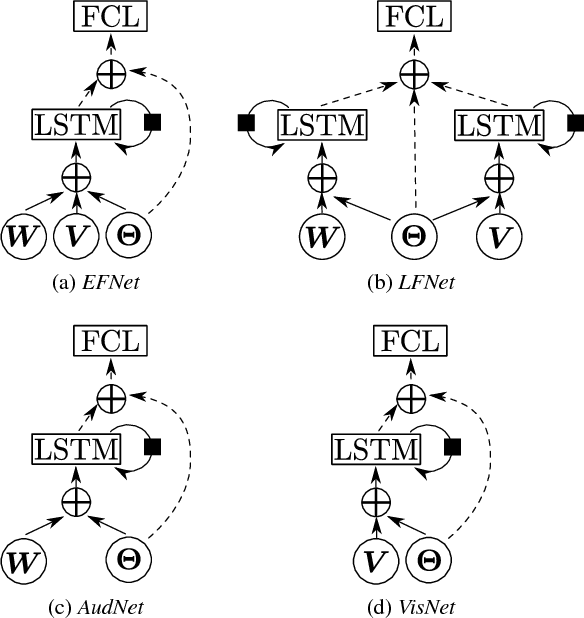
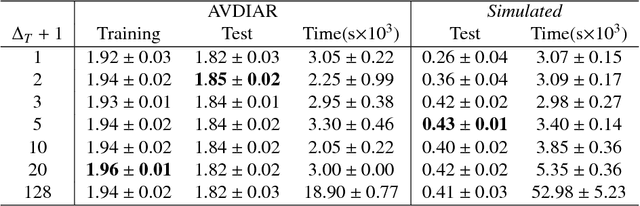
This paper introduces a novel neural network-based reinforcement learning approach for robot gaze control. Our approach enables a robot to learn and to adapt its gaze control strategy for human-robot interaction neither with the use of external sensors nor with human supervision. The robot learns to focus its attention onto groups of people from its own audio-visual experiences, independently of the number of people, of their positions and of their physical appearances. In particular, we use a recurrent neural network architecture in combination with Q-learning to find an optimal action-selection policy; we pre-train the network using a simulated environment that mimics realistic scenarios that involve speaking/silent participants, thus avoiding the need of tedious sessions of a robot interacting with people. Our experimental evaluation suggests that the proposed method is robust against parameter estimation, i.e. the parameter values yielded by the method do not have a decisive impact on the performance. The best results are obtained when both audio and visual information is jointly used. Experiments with the Nao robot indicate that our framework is a step forward towards the autonomous learning of socially acceptable gaze behavior.
Plane-extraction from depth-data using a Gaussian mixture regression model
Mar 30, 2018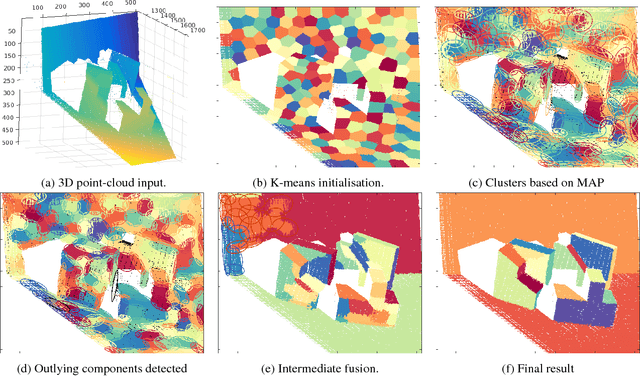
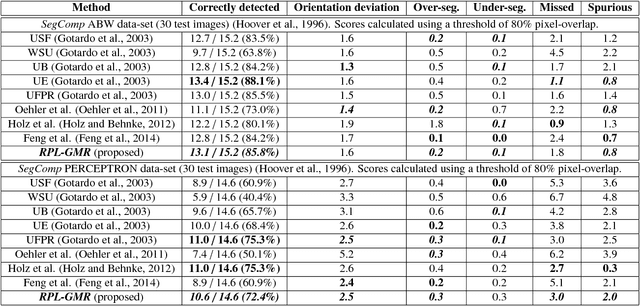
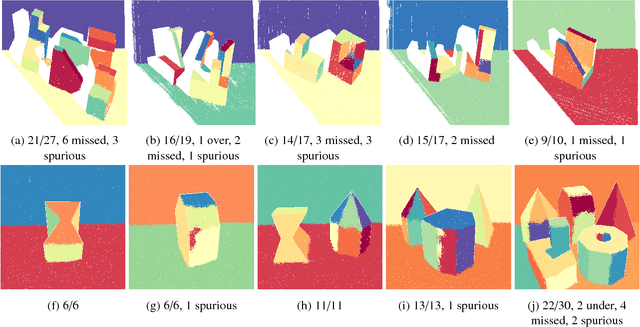
We propose a novel algorithm for unsupervised extraction of piecewise planar models from depth-data. Among other applications, such models are a good way of enabling autonomous agents (robots, cars, drones, etc.) to effectively perceive their surroundings and to navigate in three dimensions. We propose to do this by fitting the data with a piecewise-linear Gaussian mixture regression model whose components are skewed over planes, making them flat in appearance rather than being ellipsoidal, by embedding an outlier-trimming process that is formally incorporated into the proposed expectation-maximization algorithm, and by selectively fusing contiguous, coplanar components. Part of our motivation is an attempt to estimate more accurate plane-extraction by allowing each model component to make use of all available data through probabilistic clustering. The algorithm is thoroughly evaluated against a standard benchmark and is shown to rank among the best of the existing state-of-the-art methods.
* 11 pages, 2 figures, 1 table
A Comprehensive Analysis of Deep Regression
Mar 22, 2018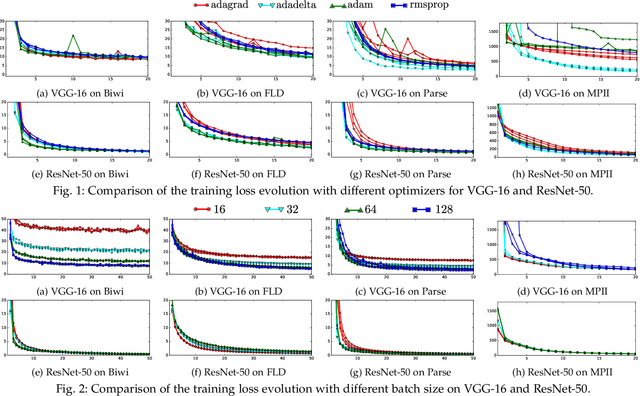

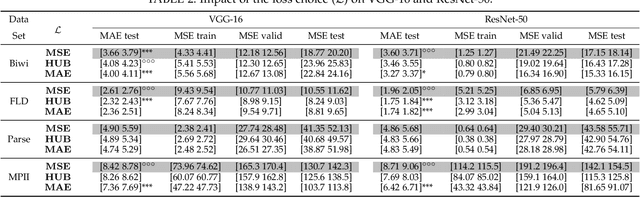
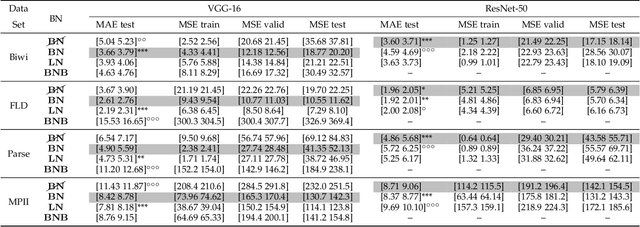
Deep learning revolutionized data science, and recently, its popularity has grown exponentially, as did the amount of papers employing deep networks. Vision tasks such as human pose estimation did not escape this methodological change. The large number of deep architectures lead to a plethora of methods that are evaluated under different experimental protocols. Moreover, small changes in the architecture of the network, or in the data pre-processing procedure, together with the stochastic nature of the optimization methods, lead to notably different results, making extremely difficult to sift methods that significantly outperform others. Therefore, when proposing regression algorithms, practitioners proceed by trial-and-error. This situation motivated the current study, in which we perform a systematic evaluation and a statistical analysis of the performance of vanilla deep regression -- short for convolutional neural networks with a linear regression top layer --. Up to our knowledge this is the first comprehensive analysis of deep regression techniques. We perform experiments on three vision problems and report confidence intervals for the median performance as well as the statistical significance of the results, if any. Surprisingly, the variability due to different data pre-processing procedures generally eclipses the variability due to modifications in the network architecture.
Tracking Gaze and Visual Focus of Attention of People Involved in Social Interaction
Nov 21, 2017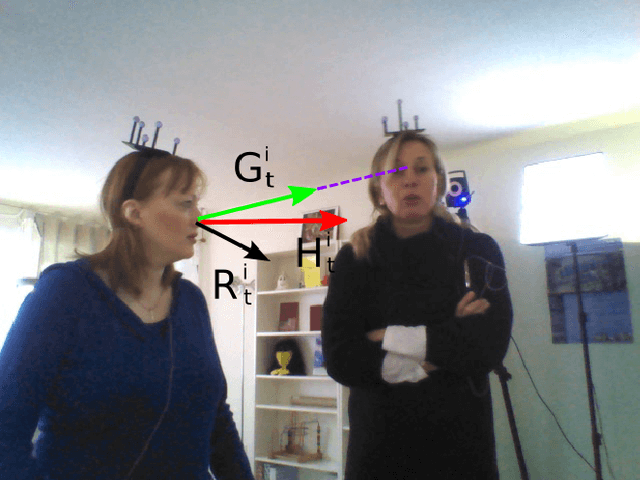
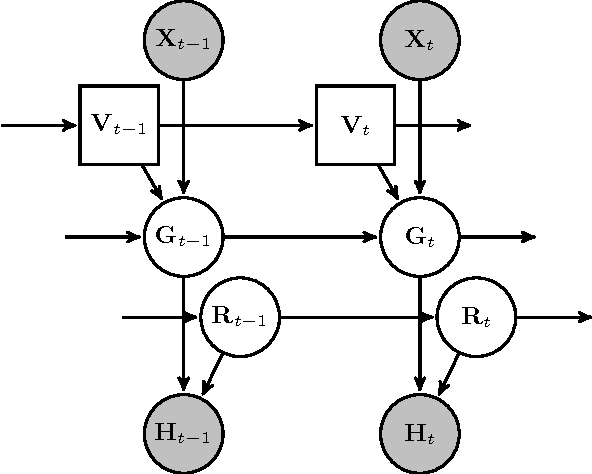
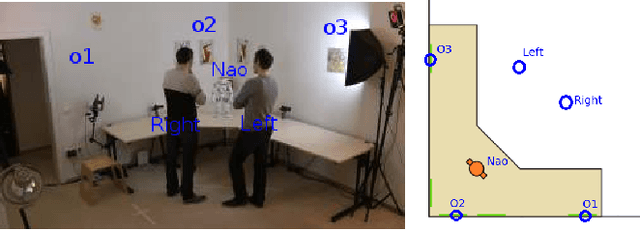
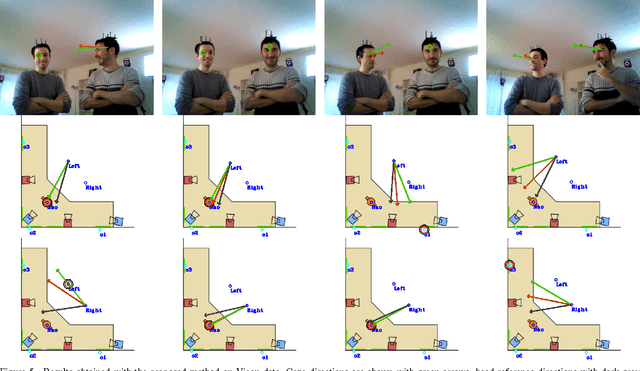
The visual focus of attention (VFOA) has been recognized as a prominent conversational cue. We are interested in estimating and tracking the VFOAs associated with multi-party social interactions. We note that in this type of situations the participants either look at each other or at an object of interest; therefore their eyes are not always visible. Consequently both gaze and VFOA estimation cannot be based on eye detection and tracking. We propose a method that exploits the correlation between eye gaze and head movements. Both VFOA and gaze are modeled as latent variables in a Bayesian switching state-space model. The proposed formulation leads to a tractable learning procedure and to an efficient algorithm that simultaneously tracks gaze and visual focus. The method is tested and benchmarked using two publicly available datasets that contain typical multi-party human-robot and human-human interactions.
* 15 pages, 8 figures, 6 tables