 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Prompt Embedding Optimization for LLM Jailbreaking
Apr 27, 2026Existing white-box jailbreak attacks against aligned LLMs typically append discrete adversarial suffixes to the user prompt, which visibly alters the prompt and operates in a combinatorial token space. Prior work has avoided directly optimizing the embeddings of the original prompt tokens, presumably because perturbing them risks destroying the prompt's semantic content. We propose Prompt Embedding Optimization (PEO), a multi-round white-box jailbreak that directly optimizes the embeddings of the original prompt tokens without appending any adversarial tokens, and show that the concern is unfounded: the optimized embeddings remain close enough to their originals that the visible prompt string is preserved exactly after nearest-token projection, and quantitative analysis shows the model's responses stay on topic for the large majority of prompts. PEO combines continuous embedding-space optimization with structured continuation targets and an adaptive failure-focused schedule. Counterintuitively, later PEO rounds can benefit from heuristic composite response scaffolds that are not natural standalone templates, yet ASR-Judge shows that the resulting gains are not merely empty formatting or scaffold-only outputs. Across two standard harmful-behavior benchmarks and competing white-box attacks spanning discrete suffix search, appended adversarial embeddings, and search-based adversarial generation, PEO outperforms all of them in our experiments.
Hybrid Forest: A Concept Drift Aware Data Stream Mining Algorithm
Feb 10, 2019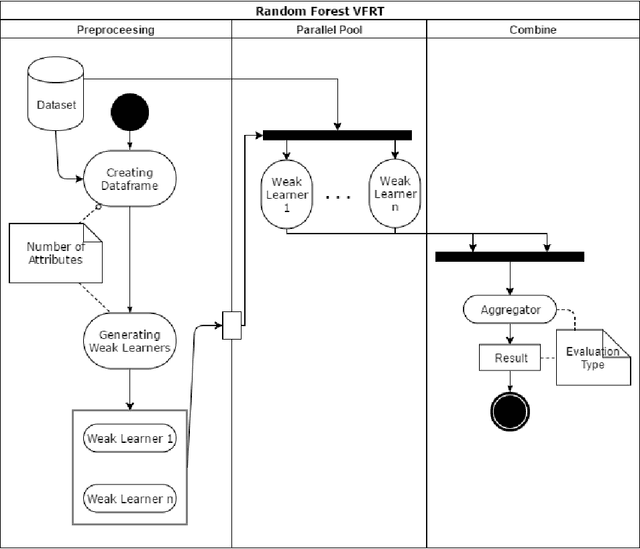
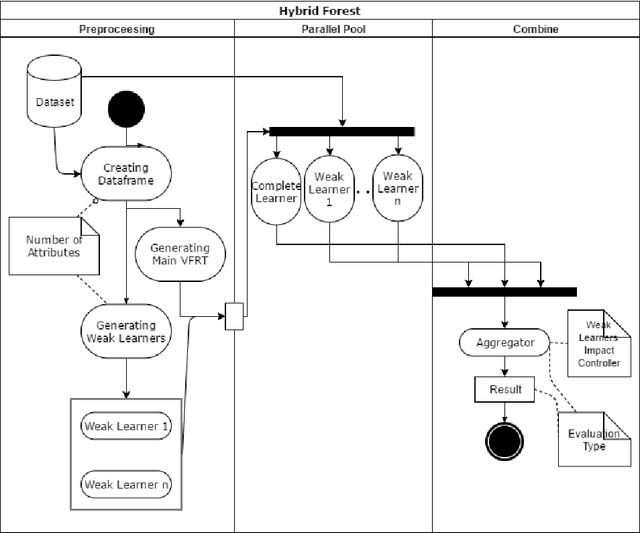

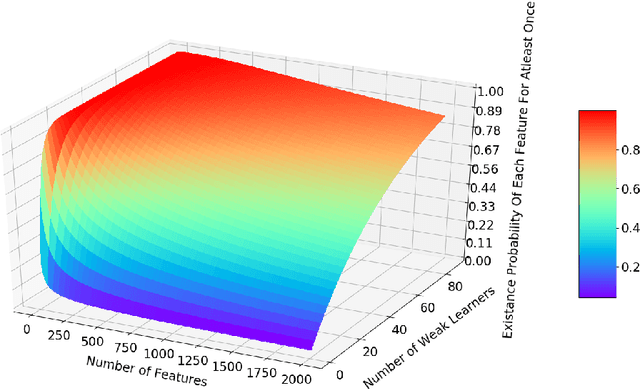
Nowadays with a growing number of online controlling systems in the organization and also a high demand of monitoring and stats facilities that uses data streams to log and control their subsystems, data stream mining becomes more and more vital. Hoeffding Trees (also called Very Fast Decision Trees a.k.a. VFDT) as a Big Data approach in dealing with the data stream for classification and regression problems showed good performance in handling facing challenges and making the possibility of any-time prediction. Although these methods outperform other methods e.g. Artificial Neural Networks (ANN) and Support Vector Regression (SVR), they suffer from high latency in adapting with new concepts when the statistical distribution of incoming data changes. In this article, we introduced a new algorithm that can detect and handle concept drift phenomenon properly. This algorithms also benefits from fast startup ability which helps systems to be able to predict faster than other algorithms at the beginning of data stream arrival. We also have shown that our approach will overperform other controversial approaches for classification and regression tasks.
A Fuzzy Community-Based Recommender System Using PageRank
Dec 18, 2018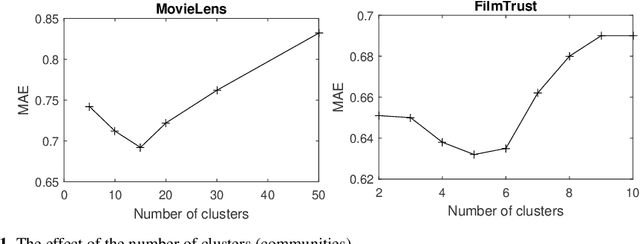
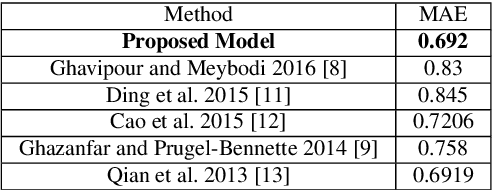
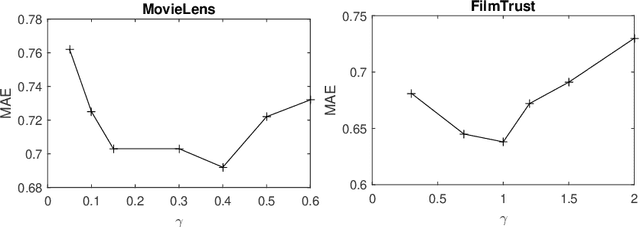

Recommendation systems are widely used by different user service providers specially those who have interactions with the large community of users. This paper introduces a recommender system based on community detection. The recommendation is provided using the local and global similarities between users. The local information is obtained from communities, and the global ones are based on the ratings. Here, a new fuzzy community detection using the personalized PageRank metaphor is introduced. The fuzzy membership values of the users to the communities are utilized to define a similarity measure. The method is evaluated by using two well-known datasets: MovieLens and FilmTrust. The results show that our method outperforms recent recommender systems.