 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonlinear Methods for Analyzing Pose in Behavioral Research
Apr 01, 2026Advances in markerless pose estimation have made it possible to capture detailed human movement in naturalistic settings using standard video, enabling new forms of behavioral analysis at scale. However, the high dimensionality, noise, and temporal complexity of pose data raise significant challenges for extracting meaningful patterns of coordination and behavioral change. This paper presents a general-purpose analysis pipeline for human pose data, designed to support both linear and nonlinear characterizations of movement across diverse experimental contexts. The pipeline combines principled preprocessing, dimensionality reduction, and recurrence-based time series analysis to quantify the temporal structure of movement dynamics. To illustrate the pipeline's flexibility, we present three case studies spanning facial and full-body movement, 2D and 3D data, and individual versus multi-agent behavior. Together, these examples demonstrate how the same analytic workflow can be adapted to extract theoretically meaningful insights from complex pose time series.
Facial Movement Dynamics Reveal Workload During Complex Multitasking
Mar 18, 2026Real-time cognitive workload monitoring is crucial in safety-critical environments, yet established measures are intrusive, expensive, or lack temporal resolution. We tested whether facial movement dynamics from a standard webcam could provide a low-cost alternative. Seventy-two participants completed a multitasking simulation (OpenMATB) under varied load while facial keypoints were tracked via OpenPose. Linear kinematics (velocity, acceleration, displacement) and recurrence quantification features were extracted. Increasing load altered dynamics across timescales: movement magnitudes rose, temporal organisation fragmented then reorganised into complex patterns, and eye-head coordination weakened. Random forest classifiers trained on pose kinematics outperformed task performance metrics (85% vs. 55% accuracy) but generalised poorly across participants (43% vs. 33% chance). Participant-specific models reached 50% accuracy with minimal calibration (2 minutes per condition), improving continuously to 73% without plateau. Facial movement dynamics sensitively track workload with brief calibration, enabling adaptive interfaces using commodity cameras, though individual differences limit cross-participant generalisation.
Predicting and Understanding Human Action Decisions during Skillful Joint-Action via Machine Learning and Explainable-AI
Jun 06, 2022
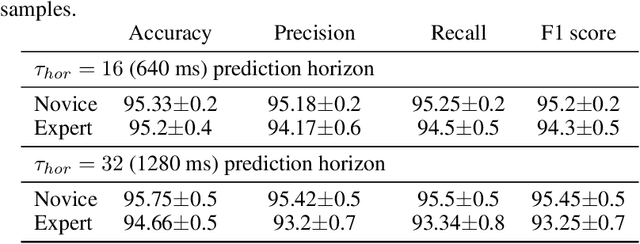
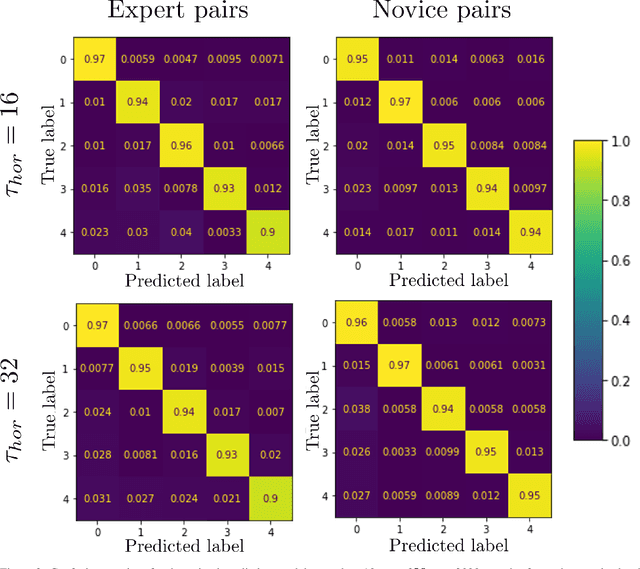
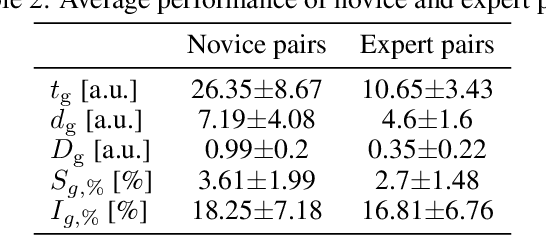
This study uses supervised machine learning (SML) and explainable artificial intelligence (AI) to model, predict and understand human decision-making during skillful joint-action. Long short-term memory networks were trained to predict the target selection decisions of expert and novice actors completing a dyadic herding task. Results revealed that the trained models were expertise specific and could not only accurately predict the target selection decisions of expert and novice herders but could do so at timescales that preceded an actor's conscious intent. To understand what differentiated the target selection decisions of expert and novice actors, we then employed the explainable-AI technique, SHapley Additive exPlanation, to identify the importance of informational features (variables) on model predictions. This analysis revealed that experts were more influenced by information about the state of their co-herders compared to novices. The utility of employing SML and explainable-AI techniques for investigating human decision-making is discussed.