 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Deep Learning: a Temperature Based Analysis of Graph Neural Networks
Sep 01, 2023We examine a Geometric Deep Learning model as a thermodynamic system treating the weights as non-quantum and non-relativistic particles. We employ the notion of temperature previously defined in [7] and study it in the various layers for GCN and GAT models. Potential future applications of our findings are discussed.
Deep Learning and Geometric Deep Learning: an introduction for mathematicians and physicists
May 09, 2023



In this expository paper we want to give a brief introduction, with few key references for further reading, to the inner functioning of the new and successfull algorithms of Deep Learning and Geometric Deep Learning with a focus on Graph Neural Networks. We go over the key ingredients for these algorithms: the score and loss function and we explain the main steps for the training of a model. We do not aim to give a complete and exhaustive treatment, but we isolate few concepts to give a fast introduction to the subject. We provide some appendices to complement our treatment discussing Kullback-Leibler divergence, regression, Multi-layer Perceptrons and the Universal Approximation Theorem.
A precortical module for robust CNNs to light variations
Feb 21, 2022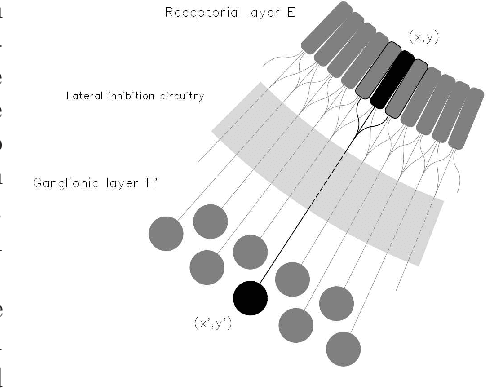
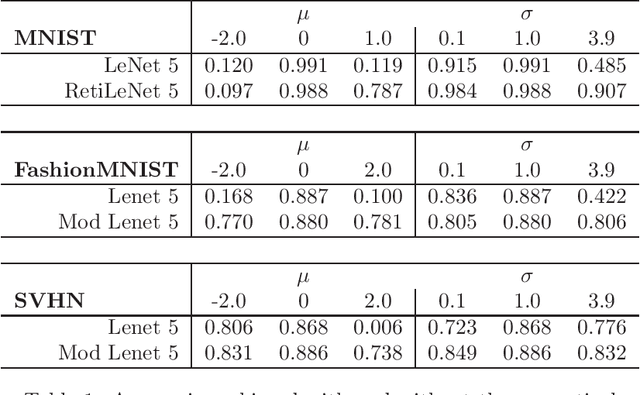

We present a simple mathematical model for the mammalian low visual pathway, taking into account its key elements: retina, lateral geniculate nucleus (LGN), primary visual cortex (V1). The analogies between the cortical level of the visual system and the structure of popular CNNs, used in image classification tasks, suggests the introduction of an additional preliminary convolutional module inspired to precortical neuronal circuits to improve robustness with respect to global light intensity and contrast variations in the input images. We validate our hypothesis on the popular databases MNIST, FashionMNIST and SVHN, obtaining significantly more robust CNNs with respect to these variations, once such extra module is added.
A geometric interpretation of stochastic gradient descent using diffusion metrics
Oct 27, 2019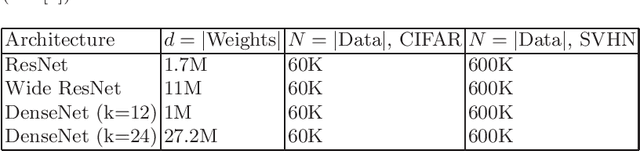
Stochastic gradient descent (SGD) is a key ingredient in the training of deep neural networks and yet its geometrical significance appears elusive. We study a deterministic model in which the trajectories of our dynamical systems are described via geodesics of a family of metrics arising from the diffusion matrix. These metrics encode information about the highly non-isotropic gradient noise in SGD. We establish a parallel with General Relativity models, where the role of the electromagnetic field is played by the gradient of the loss function. We compute an example of a two layer network.