 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumans Continue to Outperform Large Language Models in Complex Clinical Decision-Making: A Study with Medical Calculators
Nov 08, 2024


Although large language models (LLMs) have been assessed for general medical knowledge using medical licensing exams, their ability to effectively support clinical decision-making tasks, such as selecting and using medical calculators, remains uncertain. Here, we evaluate the capability of both medical trainees and LLMs to recommend medical calculators in response to various multiple-choice clinical scenarios such as risk stratification, prognosis, and disease diagnosis. We assessed eight LLMs, including open-source, proprietary, and domain-specific models, with 1,009 question-answer pairs across 35 clinical calculators and measured human performance on a subset of 100 questions. While the highest-performing LLM, GPT-4o, provided an answer accuracy of 74.3% (CI: 71.5-76.9%), human annotators, on average, outperformed LLMs with an accuracy of 79.5% (CI: 73.5-85.0%). With error analysis showing that the highest-performing LLMs continue to make mistakes in comprehension (56.6%) and calculator knowledge (8.1%), our findings emphasize that humans continue to surpass LLMs on complex clinical tasks such as calculator recommendation.
Neural Natural Language Processing for Unstructured Data in Electronic Health Records: a Review
Jul 07, 2021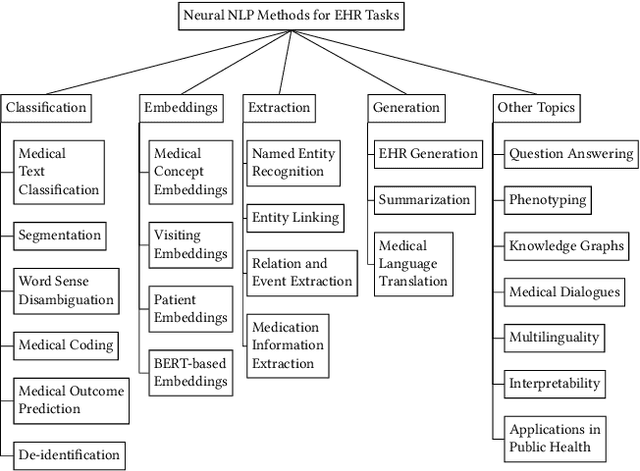
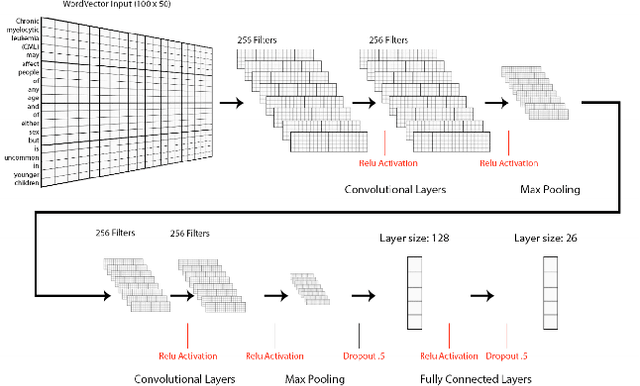
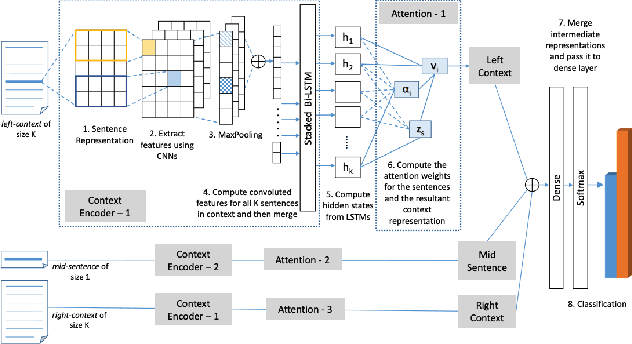

Electronic health records (EHRs), digital collections of patient healthcare events and observations, are ubiquitous in medicine and critical to healthcare delivery, operations, and research. Despite this central role, EHRs are notoriously difficult to process automatically. Well over half of the information stored within EHRs is in the form of unstructured text (e.g. provider notes, operation reports) and remains largely untapped for secondary use. Recently, however, newer neural network and deep learning approaches to Natural Language Processing (NLP) have made considerable advances, outperforming traditional statistical and rule-based systems on a variety of tasks. In this survey paper, we summarize current neural NLP methods for EHR applications. We focus on a broad scope of tasks, namely, classification and prediction, word embeddings, extraction, generation, and other topics such as question answering, phenotyping, knowledge graphs, medical dialogue, multilinguality, interpretability, etc.
Visualization of Emergency Department Clinical Data for Interpretable Patient Phenotyping
Jul 05, 2019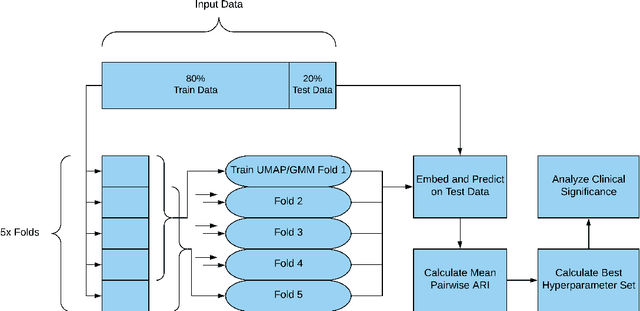
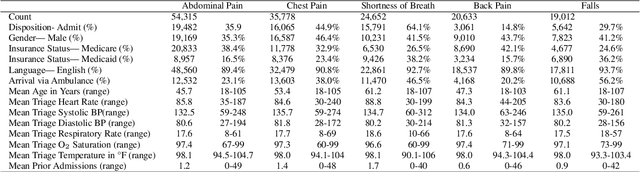
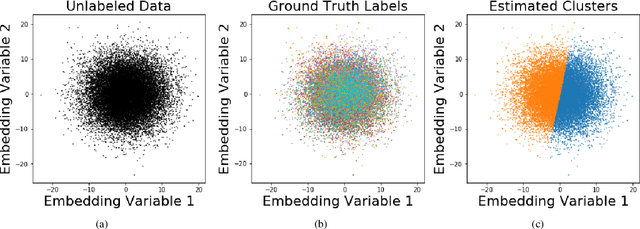

Visual summarization of clinical data collected on patients contained within the electronic health record (EHR) may enable precise and rapid triage at the time of patient presentation to an emergency department (ED). The triage process is critical in the appropriate allocation of resources and in anticipating eventual patient disposition, typically admission to the hospital or discharge home. EHR data are high-dimensional and complex, but offer the opportunity to discover and characterize underlying data-driven patient phenotypes. These phenotypes will enable improved, personalized therapeutic decision making and prognostication. In this work, we focus on the challenge of two-dimensional patient projections. A low dimensional embedding offers visual interpretability lost in higher dimensions. While linear dimensionality reduction techniques such as principal component analysis are often used towards this aim, they are insufficient to describe the variance of patient data. In this work, we employ the newly-described non-linear embedding technique called uniform manifold approximation and projection (UMAP). UMAP seeks to capture both local and global structures in high-dimensional data. We then use Gaussian mixture models to identify clusters in the embedded data and use the adjusted Rand index (ARI) to establish stability in the discovery of these clusters. This technique is applied to five common clinical chief complaints from a real-world ED EHR dataset, describing the emergent properties of discovered clusters. We observe clinically-relevant cluster attributes, suggesting that visual embeddings of EHR data using non-linear dimensionality reduction is a promising approach to reveal data-driven patient phenotypes. In the five chief complaints, we find between 2 and 6 clusters, with the peak mean pairwise ARI between subsequent training iterations to range from 0.35 to 0.74.