 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Inference for Fuzzy Clustering
Jan 06, 2026Clustering is a central tool in biomedical research for discovering heterogeneous patient subpopulations, where group boundaries are often diffuse rather than sharply separated. Traditional methods produce hard partitions, whereas soft clustering methods such as fuzzy $c$-means (FCM) allow mixed memberships and better capture uncertainty and gradual transitions. Despite the widespread use of FCM, principled statistical inference for fuzzy clustering remains limited. We develop a new framework for weighted fuzzy $c$-means (WFCM) for settings with potential cluster size imbalance. Cluster-specific weights rebalance the classical FCM criterion so that smaller clusters are not overwhelmed by dominant groups, and the weighted objective induces a normalized density model with scale parameter $σ$ and fuzziness parameter $m$. Estimation is performed via a blockwise majorize--minimize (MM) procedure that alternates closed-form membership and centroid updates with likelihood-based updates of $(σ,\bw)$. The intractable normalizing constant is approximated by importance sampling using a data-adaptive Gaussian mixture proposal. We further provide likelihood ratio tests for comparing cluster centers and bootstrap-based confidence intervals. We establish consistency and asymptotic normality of the maximum likelihood estimator, validate the method through simulations, and illustrate it using single-cell RNA-seq and Alzheimer disease Neuroimaging Initiative (ADNI) data. These applications demonstrate stable uncertainty quantification and biologically meaningful soft memberships, ranging from well-separated cell populations under imbalance to a graded AD versus non-AD continuum consistent with disease progression.
Naive Dictionary On Musical Corpora: From Knowledge Representation To Pattern Recognition
Nov 29, 2018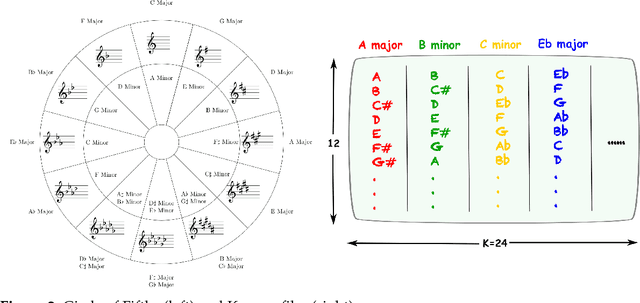
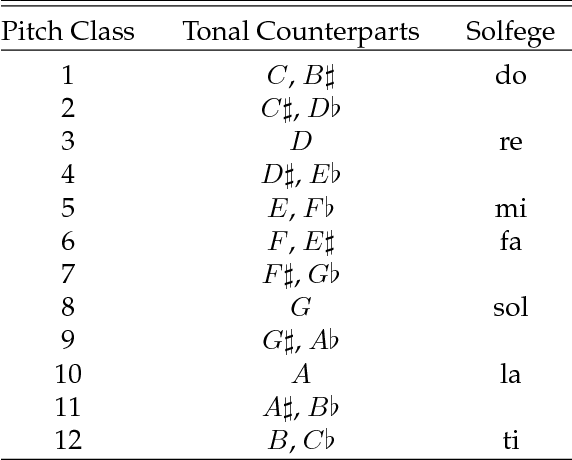
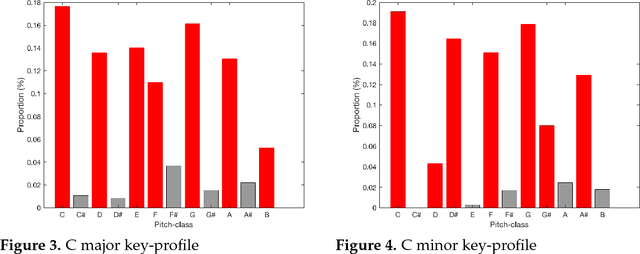
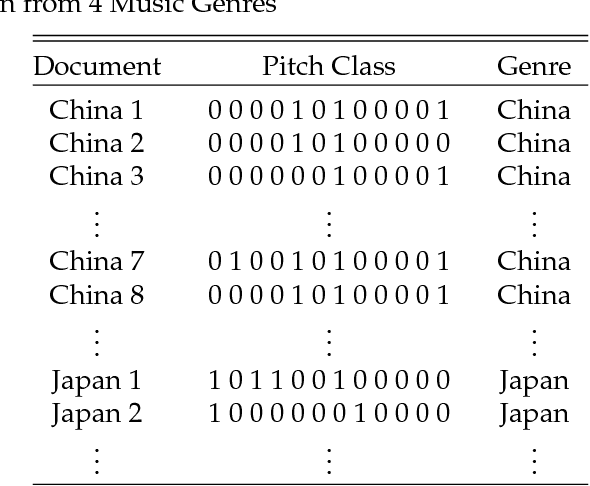
In this paper, we propose and develop the novel idea of treating musical sheets as literary documents in the traditional text analytics parlance, to fully benefit from the vast amount of research already existing in statistical text mining and topic modelling. We specifically introduce the idea of representing any given piece of music as a collection of "musical words" that we codenamed "muselets", which are essentially musical words of various lengths. Given the novelty and therefore the extremely difficulty of properly forming a complete version of a dictionary of muselets, the present paper focuses on a simpler albeit naive version of the ultimate dictionary, which we refer to as a Naive Dictionary because of the fact that all the words are of the same length. We specifically herein construct a naive dictionary featuring a corpus made up of African American, Chinese, Japanese and Arabic music, on which we perform both topic modelling and pattern recognition. Although some of the results based on the Naive Dictionary are reasonably good, we anticipate phenomenal predictive performances once we get around to actually building a full scale complete version of our intended dictionary of muselets.
On the Statistical Challenges of Echo State Networks and Some Potential Remedies
Feb 20, 2018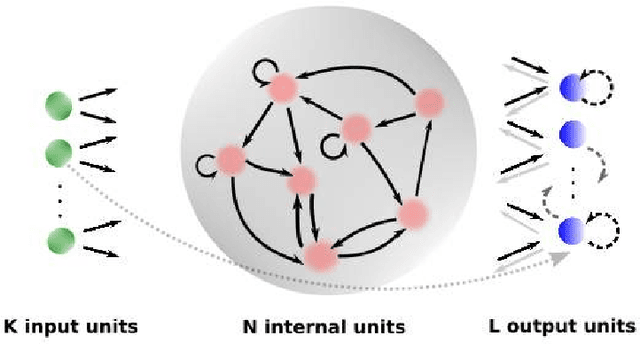

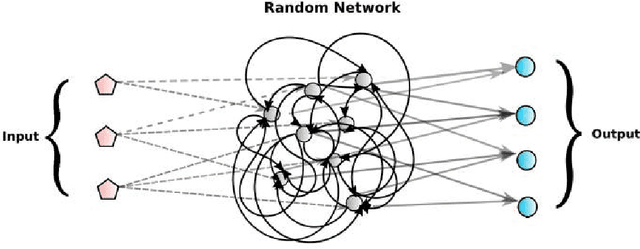
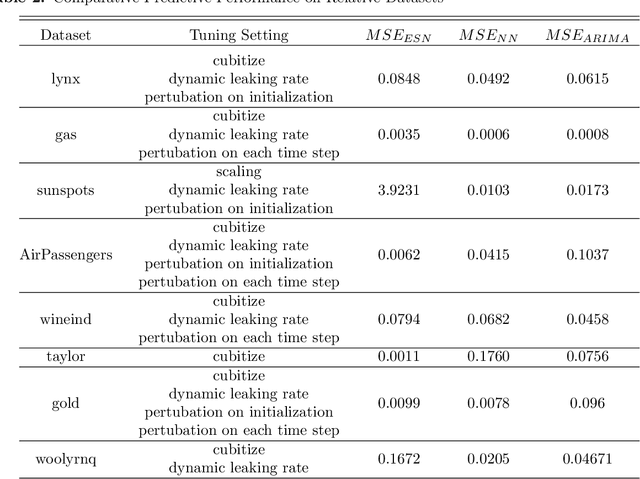
Echo state networks are powerful recurrent neural networks. However, they are often unstable and shaky, making the process of finding an good ESN for a specific dataset quite hard. Obtaining a superb accuracy by using the Echo State Network is a challenging task. We create, develop and implement a family of predictably optimal robust and stable ensemble of Echo State Networks via regularizing the training and perturbing the input. Furthermore, several distributions of weights have been tried based on the shape to see if the shape of the distribution has the impact for reducing the error. We found ESN can track in short term for most dataset, but it collapses in the long run. Short-term tracking with large size reservoir enables ESN to perform strikingly with superior prediction. Based on this scenario, we go a further step to aggregate many of ESNs into an ensemble to lower the variance and stabilize the system by stochastic replications and bootstrapping of input data.