 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Monitoring of Proton Exchange Membrane Water Electrolyzer by Transformers-Based Machine Learning Model
May 18, 2026Green hydrogen plays an essential role in decarbonization, with capacity projected to scale to 560 GW by 2030 (vs. 1.39 GW in 2023) in net-zero settings. Proton exchange membrane (PEM) electrolysis is one of the most promising technology routes to green hydrogen production, and real-time system health monitoring of PEM electrolyzers is essential for their scalable deployment. In lab settings, performance degradation can be characterized through electrochemical testing protocols by periodic pauses of normal operation. Such interruption is not practical for full-scale stack deployments, limiting system operators' ability to make real-time assessments of state-of-health (SoH). We present a machine learning (ML) framework that performs virtual electrochemical characterization during normal operation. The method uses an encoder-decoder transformer, conditioned on operational data, to reconstruct characterization outputs, focusing here on polarization curves. Inspired by patch-based sequence tokenization, we segment the inputs into patches and encode them to form meaningful tokens, which substantially improves learning efficiency. Across four longitudinal runs, lasting up to 478 hours on different test cells and loading cycles, the model accurately reconstructed polarization curves and achieved 10x reduction in mean squared error (MSE) compared to a vanilla transformer. This proof-of-concept demonstrates that ML models can enable continuous performance monitoring for PEM electrolyzers and that the encoder captures meaningful latent representations of SoH, opening up opportunities to derive interpretable indicators in future work.
Improved Mix-up with KL-Entropy for Learning From Noisy Labels
Aug 16, 2019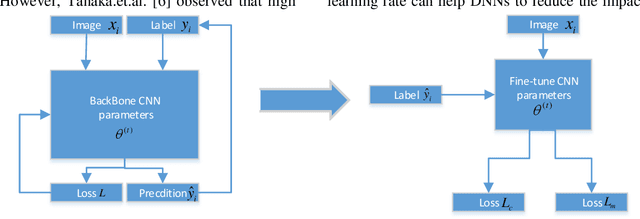
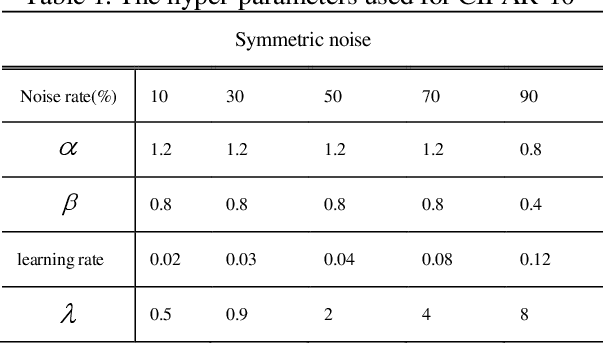
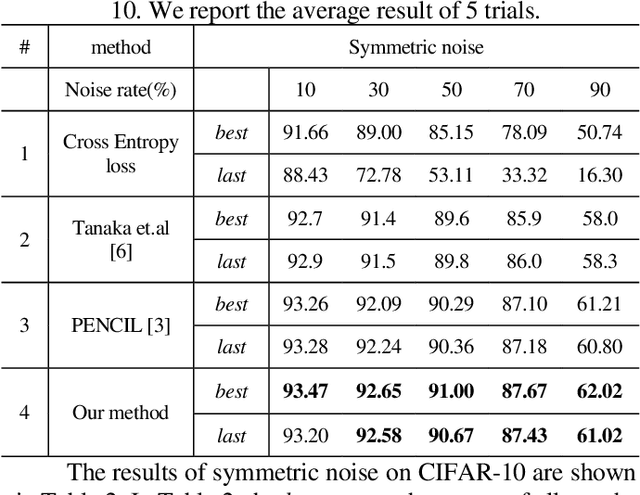
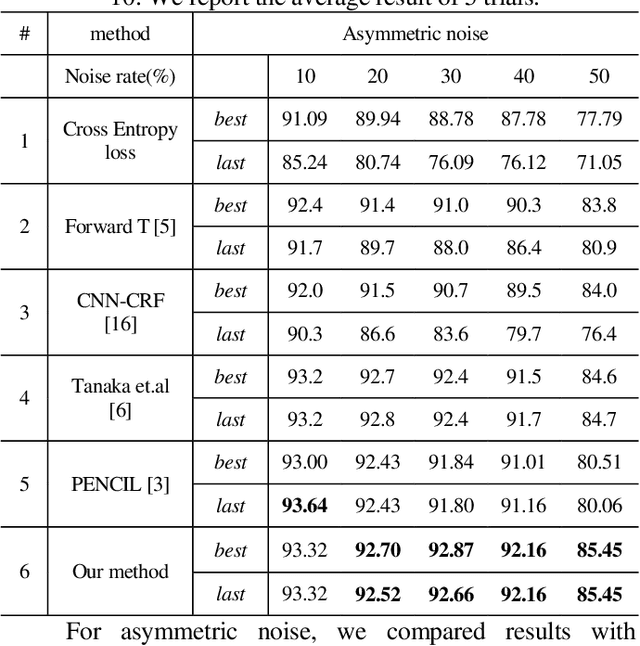
Despite the deep neural networks (DNN) has achieved excellent performance in image classification researches, the training of DNNs needs a large of clean data with accurate annotations. The collect of a dataset is easy, but it is difficult to annotate the collecting data. On the websites, there exist a lot of image data which contains inaccurate annotations, but training on these datasets may make networks easier to over-fit the noisy labels and cause performance degradation. In this work, we propose an improved joint optimization framework, which mixed the mix-up entropy and Kullback-Leibler (KL) entropy as the loss function. The new loss function can give the better fine-tuning after the framework updates both the label annotations. We conduct experiments on CIFAR-10 dataset and Clothing1M dataset. The result shows the advantageous performance of our approach compared with other state-of-the-art methods.