 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theory on Flow Matching with Neural Networks
Jun 08, 2026In this work, we develop theoretical foundation for flow matching with neural-network-parameterized conditional velocity fields. We establish convergence guarantees for gradient descent in the over-parameterized 2-layered ReLU neural network regime. We derive generalization bounds for the conditional velocity-field matching objective. Building on these results, we provide Wasserstein-distance guarantees for the samples generated by the induced flow. Our analysis is based on generalization bound for multi-task representation learning with unbounded losses, which may be of independent interest beyond flow-based generative modeling. These theoretical results are validated through extensive experiments on both synthetic and real-world image benchmarks.
Optimally taming biases in black-box models for efficient semiparametric estimation
Jun 04, 2026Modern semiparametric estimation often relies on flexible black-box machine learning methods to estimate nuisance functions, raising a fundamental question: how do nuisance estimation errors propagate into inference for low-dimensional target parameters? The dominant paradigm, exemplified by double machine learning (DML), yields error bounds in which nuisance estimation errors enter multiplicatively. While widely adopted, it remains unclear whether this multiplicative-rate dependence is optimal for black-box models. In this paper, we start by revisiting the partial linear model $Y = μ_0(X)+T\cdotβ_0+\varepsilon$ under a structure-agnostic setting, where the nuisance function $μ_0$ is estimated using a generic machine learning model, with approximation error $δ^a_μ$ and stochastic error $δ_μ^s$. We show that the standard DML rate is not optimal in the regime where the auxiliary function $\mathbb{E}[T|X=x]$ cannot be consistently estimated. We propose a new estimator for $β_0$ that achieves a sharper rate of $n^{-1/2}+δ^a_μ+(δ_μ^s)^2$ and establish a matching lower bound demonstrating its optimality. Our results reveal a new principle: the first-order stochastic error of nuisance estimation can be eliminated without imposing any additional assumptions. This also leads to a revised tuning strategy favoring under-smoothing, where $δ^a_μ\asymp(δ_μ^s)^2$, rather than the classical bias-variance trade-off $δ^a_μ\asymp δ_μ^s$. Under mild additional conditions, the estimator is asymptotically normal with minimal asymptotic variance. The proposed method extends to a broad class of semi-parametric linear functional estimation problems, including average treatment effect estimation. Our results imply that popular orthogonal score methods in semiparametric estimation with black-box nuisance learners can be substantially improved.
Goedel-Architect: Streamlining Formal Theorem Proving with Blueprint Generation and Refinement
Jun 04, 2026We introduce Goedel-Architect, an agentic framework for formal theorem proving in Lean 4 centered on blueprint generation and refinement. A blueprint is a dependency graph of definitions and lemmas that builds up to the main theorem. First, Goedel-Architect generates a blueprint of formally stated definitions and lemmas, along with declared dependencies. This blueprint is optionally guided by a natural language proof. Then, a tool-equipped Lean prover component closes each open lemma node in parallel using relevant dependencies. Failed lemmas in turn drive refinement of the global blueprint. This strategy contrasts with other mainstream approaches which use recursive lemma decomposition, and can inefficiently loop on dead-end strategies. Using the open-weight DeepSeek-V4-Flash (284B-A13B) as the backbone, Goedel-Architect attains 99.2% pass@1 on MiniF2F-test and 75.6% pass@1 on PutnamBench. With an optional natural-language proof seeding the initial blueprint on the harder problems, we additionally close the remaining two MiniF2F-test problems (reaching 100%), lift PutnamBench to 88.8% (597/672), and solve 4/6 on IMO 2025, 11/12 on Putnam 2025, and 3/6 on USAMO 2026. This represents state-of-the-art performance for an open-source pipeline at a price point up to 500x less than comparable open-source pipelines.
Fine-tuning Factor Augmented Neural Lasso for Heterogeneous Environments
Apr 14, 2026Fine-tuning is a widely used strategy for adapting pre-trained models to new tasks, yet its methodology and theoretical properties in high-dimensional nonparametric settings with variable selection have not yet been developed. This paper introduces the fine-tuning factor augmented neural Lasso (FAN-Lasso), a transfer learning framework for high-dimensional nonparametric regression with variable selection that simultaneously handles covariate and posterior shifts. We use a low-rank factor structure to manage high-dimensional dependent covariates and propose a novel residual fine-tuning decomposition in which the target function is expressed as a transformation of a frozen source function and other variables to achieve transfer learning and nonparametric variable selection. This augmented feature from the source predictor allows for the transfer of knowledge to the target domain and reduces model complexity there. We derive minimax-optimal excess risk bounds for the fine-tuning FAN-Lasso, characterizing the precise conditions, in terms of relative sample sizes and function complexities, under which fine-tuning yields statistical acceleration over single-task learning. The proposed framework also provides a theoretical perspective on parameter-efficient fine-tuning methods. Extensive numerical experiments across diverse covariate- and posterior-shift scenarios demonstrate that the fine-tuning FAN-Lasso consistently outperforms standard baselines and achieves near-oracle performance even under severe target sample size constraints, empirically validating the derived rates.
Factor Informed Double Deep Learning For Average Treatment Effect Estimation
Aug 23, 2025We investigate the problem of estimating the average treatment effect (ATE) under a very general setup where the covariates can be high-dimensional, highly correlated, and can have sparse nonlinear effects on the propensity and outcome models. We present the use of a Double Deep Learning strategy for estimation, which involves combining recently developed factor-augmented deep learning-based estimators, FAST-NN, for both the response functions and propensity scores to achieve our goal. By using FAST-NN, our method can select variables that contribute to propensity and outcome models in a completely nonparametric and algorithmic manner and adaptively learn low-dimensional function structures through neural networks. Our proposed novel estimator, FIDDLE (Factor Informed Double Deep Learning Estimator), estimates ATE based on the framework of augmented inverse propensity weighting AIPW with the FAST-NN-based response and propensity estimates. FIDDLE consistently estimates ATE even under model misspecification and is flexible to also allow for low-dimensional covariates. Our method achieves semiparametric efficiency under a very flexible family of propensity and outcome models. We present extensive numerical studies on synthetic and real datasets to support our theoretical guarantees and establish the advantages of our methods over other traditional choices, especially when the data dimension is large.
Covariate-Balancing-Aware Interpretable Deep Learning models for Treatment Effect Estimation
Mar 08, 2022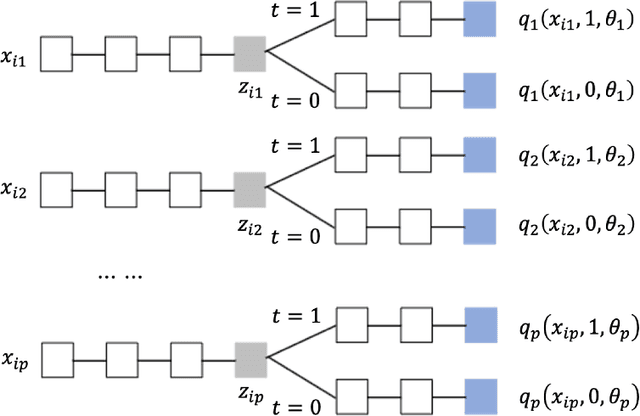

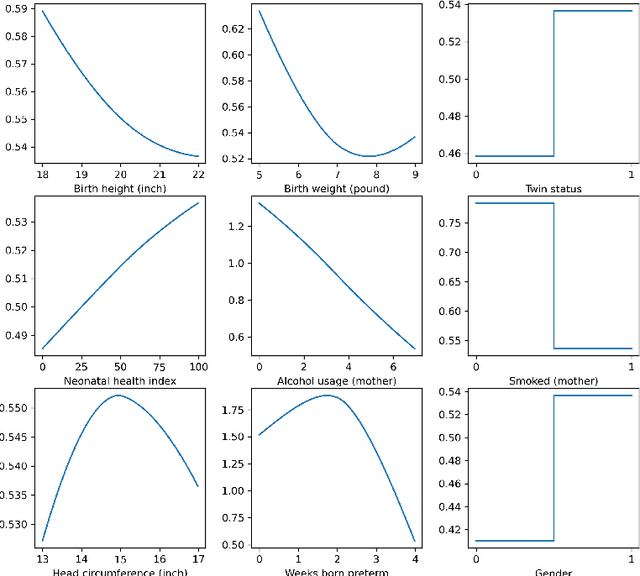
Estimating treatment effects is of great importance for many biomedical applications with observational data. Particularly, interpretability of the treatment effects is preferable for many biomedical researchers. In this paper, we first give a theoretical analysis and propose an upper bound for the bias of average treatment effect estimation under the strong ignorability assumption. The proposed upper bound consists of two parts: training error for factual outcomes, and the distance between treated and control distributions. We use the Weighted Energy Distance (WED) to measure the distance between two distributions. Motivated by the theoretical analysis, we implement this upper bound as an objective function being minimized by leveraging a novel additive neural network architecture, which combines the expressivity of deep neural network, the interpretability of generalized additive model, the sufficiency of the balancing score for estimation adjustment, and covariate balancing properties of treated and control distributions, for estimating average treatment effects from observational data. Furthermore, we impose a so-called weighted regularization procedure based on non-parametric theory, to obtain some desirable asymptotic properties. The proposed method is illustrated by re-examining the benchmark datasets for causal inference, and it outperforms the state-of-art.