 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeliberation Networks and How to Train Them
Nov 06, 2022Deliberation networks are a family of sequence-to-sequence models, which have achieved state-of-the-art performance in a wide range of tasks such as machine translation and speech synthesis. A deliberation network consists of multiple standard sequence-to-sequence models, each one conditioned on the initial input and the output of the previous model. During training, there are several key questions: whether to apply Monte Carlo approximation to the gradients or the loss, whether to train the standard models jointly or separately, whether to run an intermediate model in teacher forcing or free running mode, whether to apply task-specific techniques. Previous work on deliberation networks typically explores one or two training options for a specific task. This work introduces a unifying framework, covering various training options, and addresses the above questions. In general, it is simpler to approximate the gradients. When parallel training is essential, separate training should be adopted. Regardless of the task, the intermediate model should be in free running mode. For tasks where the output is continuous, a guided attention loss can be used to prevent degradation into a standard model.
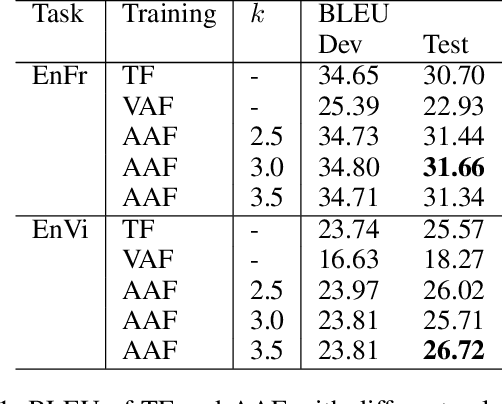
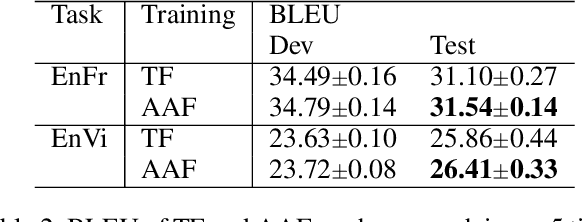
Parallel Attention Forcing for Machine Translation
Nov 06, 2022



Attention-based autoregressive models have achieved state-of-the-art performance in various sequence-to-sequence tasks, including Text-To-Speech (TTS) and Neural Machine Translation (NMT), but can be difficult to train. The standard training approach, teacher forcing, guides a model with the reference back-history. During inference, the generated back-history must be used. This mismatch limits the evaluation performance. Attention forcing has been introduced to address the mismatch, guiding the model with the generated back-history and reference attention. While successful in tasks with continuous outputs like TTS, attention forcing faces additional challenges in tasks with discrete outputs like NMT. This paper introduces the two extensions of attention forcing to tackle these challenges. (1) Scheduled attention forcing automatically turns attention forcing on and off, which is essential for tasks with discrete outputs. (2) Parallel attention forcing makes training parallel, and is applicable to Transformer-based models. The experiments show that the proposed approaches improve the performance of models based on RNNs and Transformers.
Attention Forcing for Machine Translation
Apr 02, 2021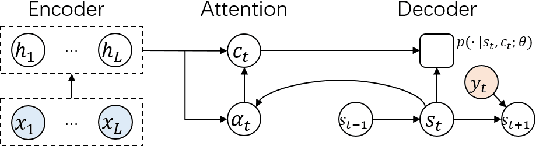
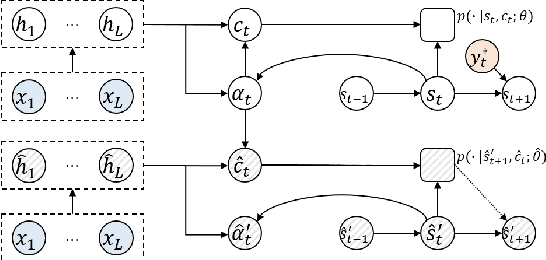
Auto-regressive sequence-to-sequence models with attention mechanisms have achieved state-of-the-art performance in various tasks including Text-To-Speech (TTS) and Neural Machine Translation (NMT). The standard training approach, teacher forcing, guides a model with the reference output history. At inference stage, the generated output history must be used. This mismatch can impact performance. However, it is highly challenging to train the model using the generated output. Several approaches have been proposed to address this problem, normally by selectively using the generated output history. To make training stable, these approaches often require a heuristic schedule or an auxiliary classifier. This paper introduces attention forcing for NMT. This approach guides the model with the generated output history and reference attention, and can reduce the training-inference mismatch without a schedule or a classifier. Attention forcing has been successful in TTS, but its application to NMT is more challenging, due to the discrete and multi-modal nature of the output space. To tackle this problem, this paper adds a selection scheme to vanilla attention forcing, which automatically selects a suitable training approach for each pair of training data. Experiments show that attention forcing can improve the overall translation quality and the diversity of the translations.
Attention Forcing for Sequence-to-sequence Model Training
Oct 02, 2019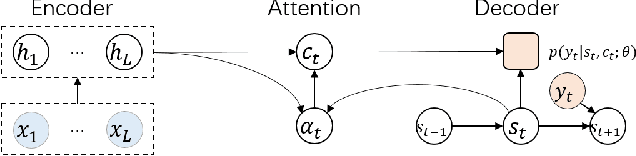
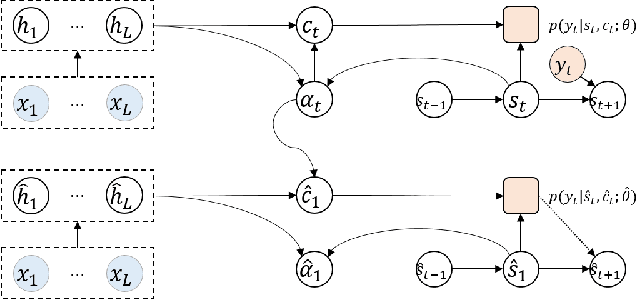

Auto-regressive sequence-to-sequence models with attention mechanism have achieved state-of-the-art performance in many tasks such as machine translation and speech synthesis. These models can be difficult to train. The standard approach, teacher forcing, guides a model with reference output history during training. The problem is that the model is unlikely to recover from its mistakes during inference, where the reference output is replaced by generated output. Several approaches deal with this problem, largely by guiding the model with generated output history. To make training stable, these approaches often require a heuristic schedule or an auxiliary classifier. This paper introduces attention forcing, which guides the model with generated output history and reference attention. This approach can train the model to recover from its mistakes, in a stable fashion, without the need for a schedule or a classifier. In addition, it allows the model to generate output sequences aligned with the references, which can be important for cascaded systems like many speech synthesis systems. Experiments on speech synthesis show that attention forcing yields significant performance gain. Experiments on machine translation show that for tasks where various re-orderings of the output are valid, guiding the model with generated output history is challenging, while guiding the model with reference attention is beneficial.