 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Space Targeted Attacks by Statistic Alignment
May 25, 2021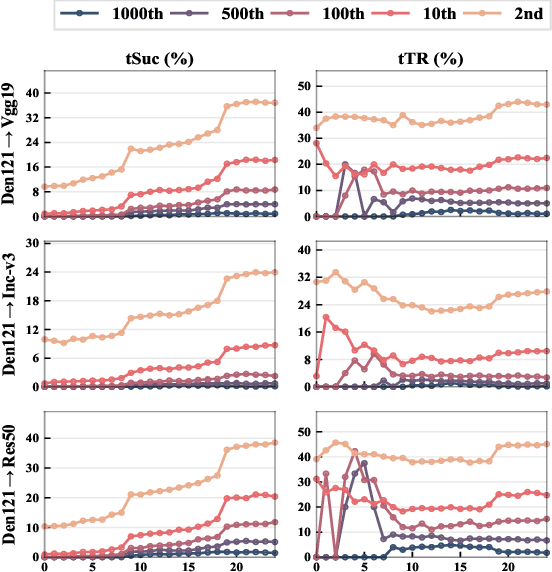
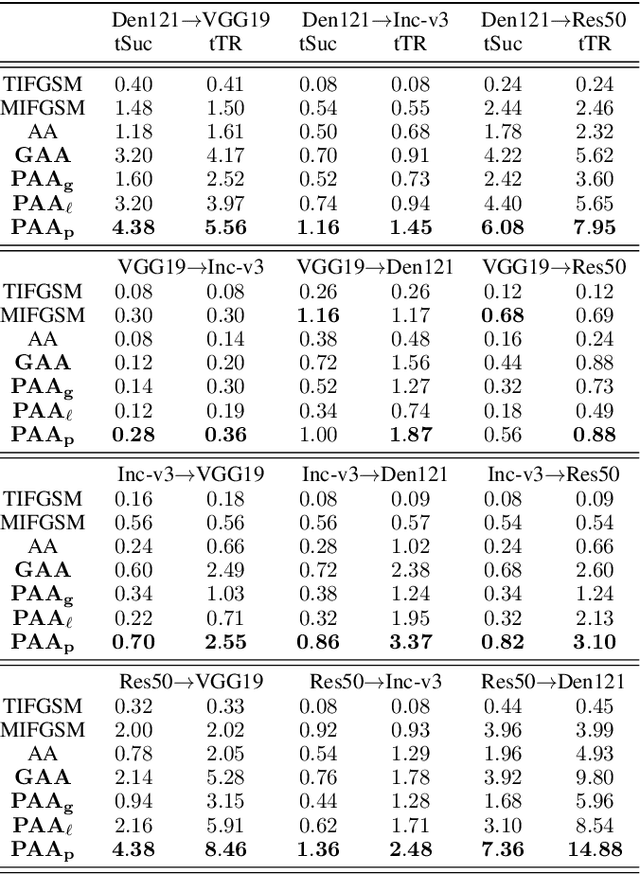
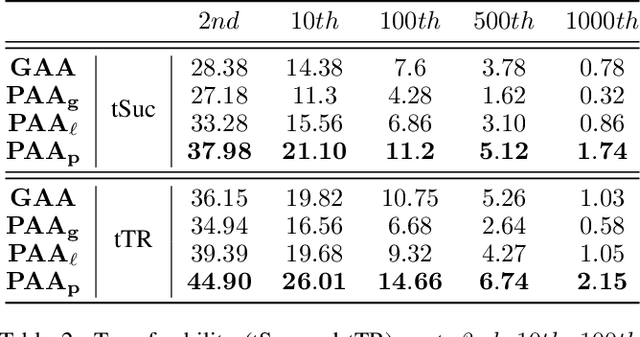
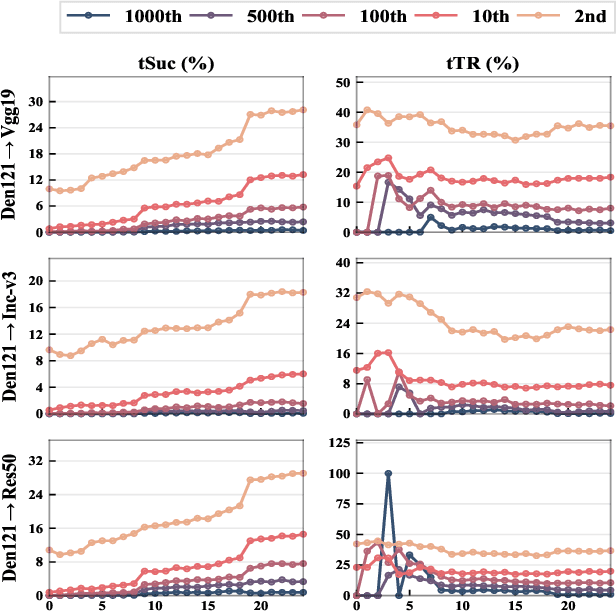
By adding human-imperceptible perturbations to images, DNNs can be easily fooled. As one of the mainstream methods, feature space targeted attacks perturb images by modulating their intermediate feature maps, for the discrepancy between the intermediate source and target features is minimized. However, the current choice of pixel-wise Euclidean Distance to measure the discrepancy is questionable because it unreasonably imposes a spatial-consistency constraint on the source and target features. Intuitively, an image can be categorized as "cat" no matter the cat is on the left or right of the image. To address this issue, we propose to measure this discrepancy using statistic alignment. Specifically, we design two novel approaches called Pair-wise Alignment Attack and Global-wise Alignment Attack, which attempt to measure similarities between feature maps by high-order statistics with translation invariance. Furthermore, we systematically analyze the layer-wise transferability with varied difficulties to obtain highly reliable attacks. Extensive experiments verify the effectiveness of our proposed method, and it outperforms the state-of-the-art algorithms by a large margin. Our code is publicly available at https://github.com/yaya-cheng/PAA-GAA.
Staircase Sign Method for Boosting Adversarial Attacks
Apr 20, 2021
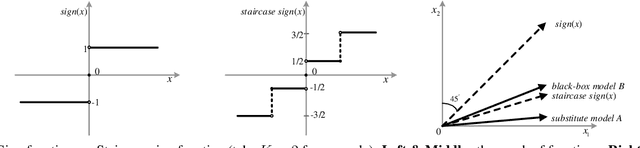
Crafting adversarial examples for the transfer-based attack is challenging and remains a research hot spot. Currently, such attack methods are based on the hypothesis that the substitute model and the victim's model learn similar decision boundaries, and they conventionally apply Sign Method (SM) to manipulate the gradient as the resultant perturbation. Although SM is efficient, it only extracts the sign of gradient units but ignores their value difference, which inevitably leads to a serious deviation. Therefore, we propose a novel Staircase Sign Method (S$^2$M) to alleviate this issue, thus boosting transfer-based attacks. Technically, our method heuristically divides the gradient sign into several segments according to the values of the gradient units, and then assigns each segment with a staircase weight for better crafting adversarial perturbation. As a result, our adversarial examples perform better in both white-box and black-box manner without being more visible. Since S$^2$M just manipulates the resultant gradient, our method can be generally integrated into any transfer-based attacks, and the computational overhead is negligible. Extensive experiments on the ImageNet dataset demonstrate the effectiveness of our proposed methods, which significantly improve the transferability (i.e., on average, \textbf{5.1\%} for normally trained models and \textbf{11.2\%} for adversarially trained defenses). Our code is available at: \url{https://github.com/qilong-zhang/Staircase-sign-method}.
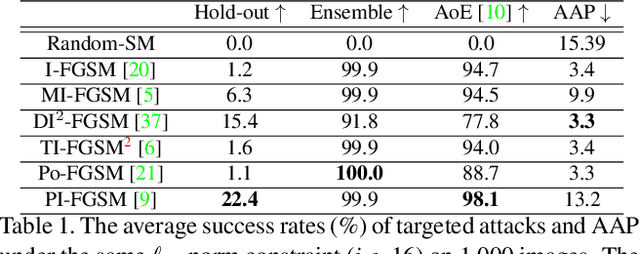
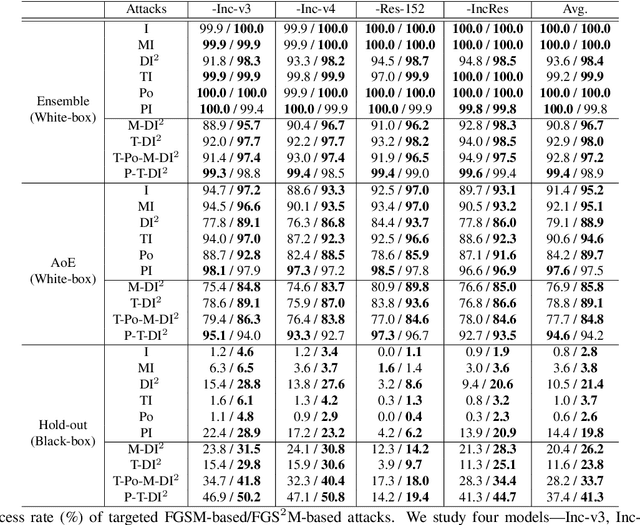
Patch-wise++ Perturbation for Adversarial Targeted Attacks
Jan 07, 2021
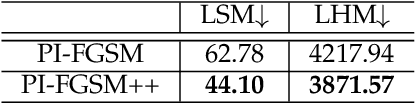
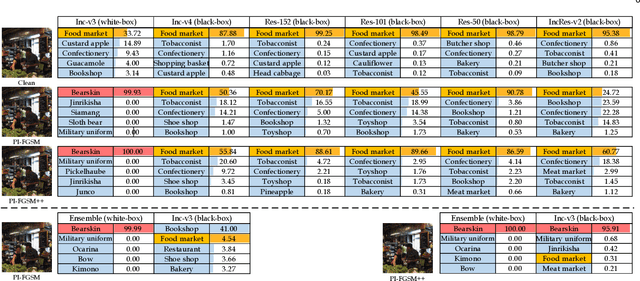
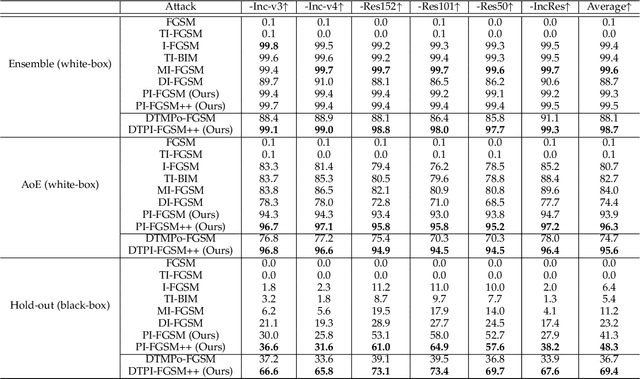
Although great progress has been made on adversarial attacks for deep neural networks (DNNs), their transferability is still unsatisfactory, especially for targeted attacks. There are two problems behind that have been long overlooked: 1) the conventional setting of $T$ iterations with the step size of $\epsilon/T$ to comply with the $\epsilon$-constraint. In this case, most of the pixels are allowed to add very small noise, much less than $\epsilon$; and 2) usually manipulating pixel-wise noise. However, features of a pixel extracted by DNNs are influenced by its surrounding regions, and different DNNs generally focus on different discriminative regions in recognition. To tackle these issues, we propose a patch-wise iterative method (PIM) aimed at crafting adversarial examples with high transferability. Specifically, we introduce an amplification factor to the step size in each iteration, and one pixel's overall gradient overflowing the $\epsilon$-constraint is properly assigned to its surrounding regions by a project kernel. But targeted attacks aim to push the adversarial examples into the territory of a specific class, and the amplification factor may lead to underfitting. Thus, we introduce the temperature and propose a patch-wise++ iterative method (PIM++) to further improve transferability without significantly sacrificing the performance of the white-box attack. Our method can be generally integrated to any gradient-based attack method. Compared with the current state-of-the-art attack methods, we significantly improve the success rate by 35.9\% for defense models and 32.7\% for normally trained models on average.
Patch-wise Attack for Fooling Deep Neural Network
Jul 16, 2020
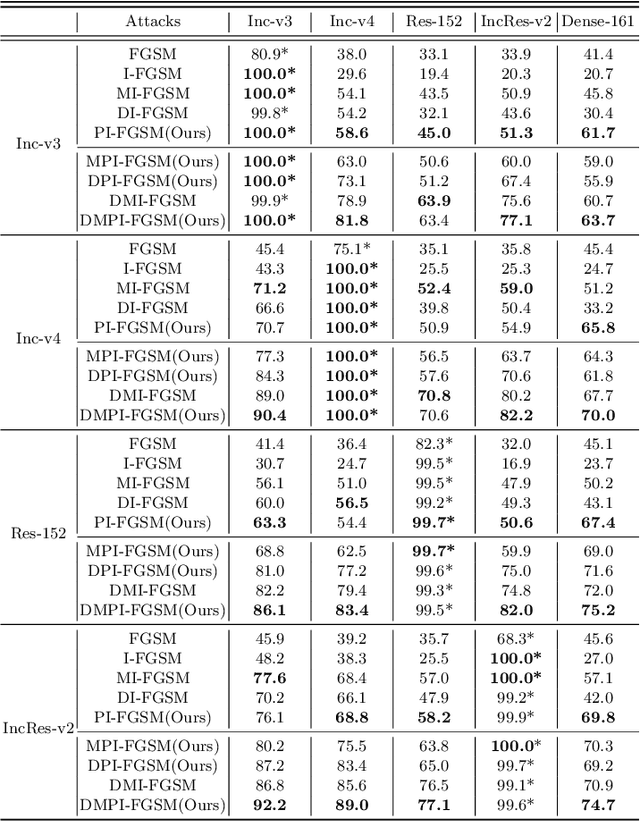
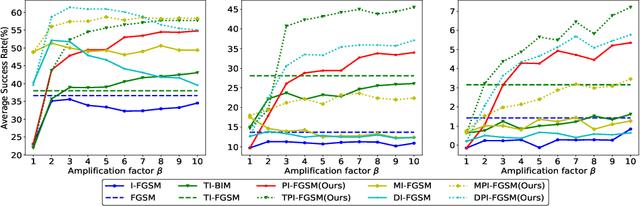
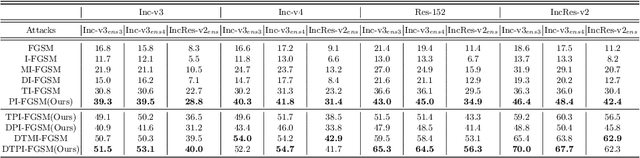
By adding human-imperceptible noise to clean images, the resultant adversarial examples can fool other unknown models. Features of a pixel extracted by deep neural networks (DNNs) are influenced by its surrounding regions, and different DNNs generally focus on different discriminative regions in recognition. Motivated by this, we propose a patch-wise iterative algorithm -- a black-box attack towards mainstream normally trained and defense models, which differs from the existing attack methods manipulating pixel-wise noise. In this way, without sacrificing the performance of white-box attack, our adversarial examples can have strong transferability. Specifically, we introduce an amplification factor to the step size in each iteration, and one pixel's overall gradient overflowing the $\epsilon$-constraint is properly assigned to its surrounding regions by a project kernel. Our method can be generally integrated to any gradient-based attack methods. Compared with the current state-of-the-art attacks, we significantly improve the success rate by 9.2\% for defense models and 3.7\% for normally trained models on average. Our code is available at \url{https://github.com/qilong-zhang/Patch-wise-iterative-attack}