 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Two-Dimensional Ridge Regression for Subspace Clustering
Nov 03, 2020


Subspace clustering methods have been widely studied recently. When the inputs are 2-dimensional (2D) data, existing subspace clustering methods usually convert them into vectors, which severely damages inherent structures and relationships from original data. In this paper, we propose a novel subspace clustering method for 2D data. It directly uses 2D data as inputs such that the learning of representations benefits from inherent structures and relationships of the data. It simultaneously seeks image projection and representation coefficients such that they mutually enhance each other and lead to powerful data representations. An efficient algorithm is developed to solve the proposed objective function with provable decreasing and convergence property. Extensive experimental results verify the effectiveness of the new method.
Fractal Autoencoders for Feature Selection
Oct 19, 2020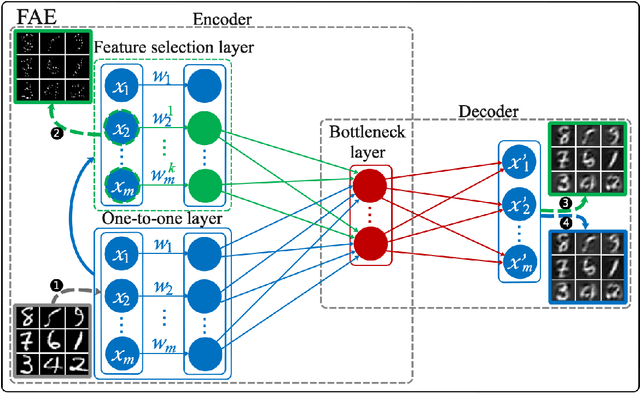

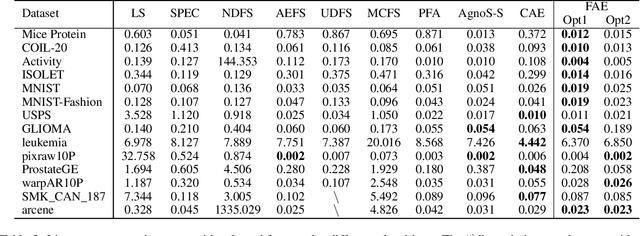
Feature selection reduces the dimensionality of data by identifying a subset of the most informative features. In this paper, we propose an innovative framework for unsupervised feature selection, called fractal autoencoders (FAE). It trains a neural network (NN) to pinpoint informative features for global exploring of representability and for local excavating of diversity. Architecturally, FAE extends autoencoders by adding a one-to-one scoring layer and a small sub-NN for feature selection in an unsupervised fashion. With such a concise architecture, FAE achieves state-of-the-art performances; extensive experimental results on fourteen datasets, including very high-dimensional data, have demonstrated the superiority of FAE over existing contemporary methods for unsupervised feature selection. In particular, FAE exhibits substantial advantages on gene expression data exploration, reducing measurement cost by about 15% over the widely used L1000 landmark genes. Further, we show that the FAE framework is easily extensible with an application.
A Uniformly Stable Algorithm For Unsupervised Feature Selection
Oct 19, 2020
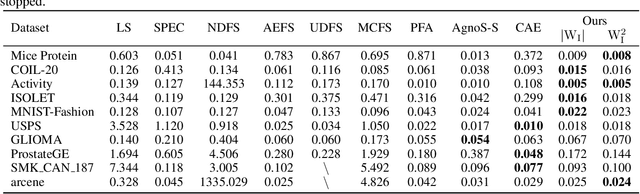
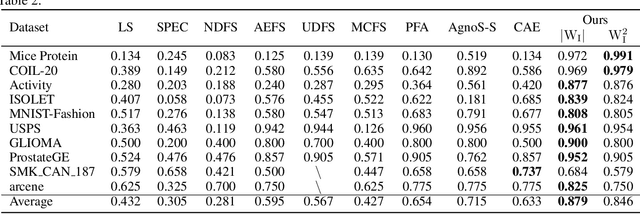
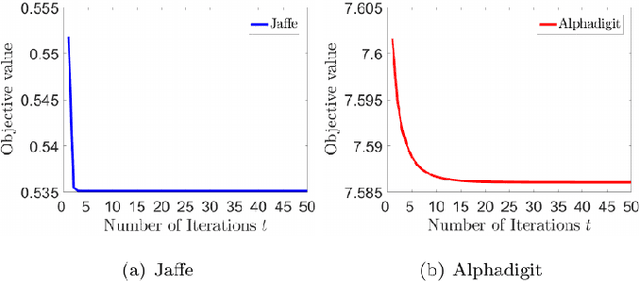
High-dimensional data presents challenges for data management. Feature selection, as an important dimensionality reduction technique, reduces the dimensionality of data by identifying an essential subset of input features, and it can provide interpretable, effective, and efficient insights for analysis and decision-making processes. Algorithmic stability is a key characteristic of an algorithm in its sensitivity to perturbations of input samples. In this paper, first we propose an innovative unsupervised feature selection algorithm. The architecture of our algorithm consists of a feature scorer and a feature selector. The scorer trains a neural network (NN) to score all the features globally, and the selector is in a dependence sub-NN which locally evaluates the representation abilities to select features. Further, we present algorithmic stability analysis and show our algorithm has a performance guarantee by providing a generalization error bound. Empirically, extensive experimental results on ten real-world datasets corroborate the superior generalization performance of our algorithm over contemporary algorithms. Notably, the features selected by our algorithm have comparable performance to the original features; therefore, our algorithm significantly facilitates data management.
Structured Graph Learning for Clustering and Semi-supervised Classification
Aug 31, 2020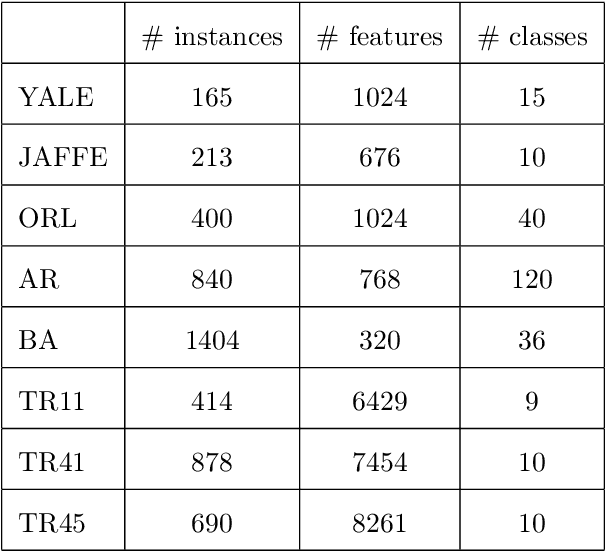
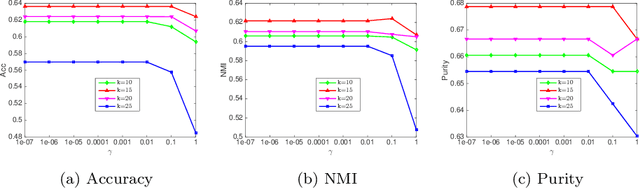
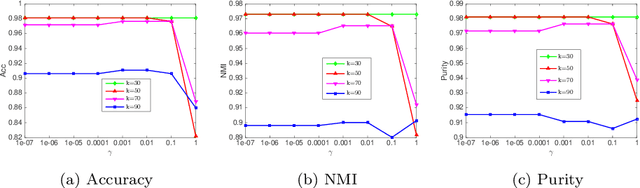
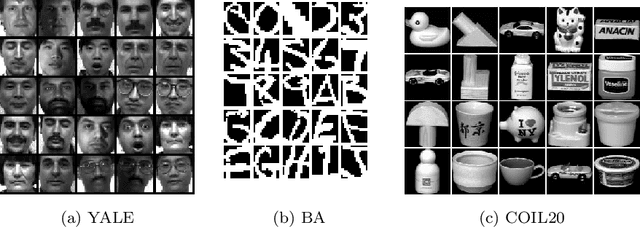
Graphs have become increasingly popular in modeling structures and interactions in a wide variety of problems during the last decade. Graph-based clustering and semi-supervised classification techniques have shown impressive performance. This paper proposes a graph learning framework to preserve both the local and global structure of data. Specifically, our method uses the self-expressiveness of samples to capture the global structure and adaptive neighbor approach to respect the local structure. Furthermore, most existing graph-based methods conduct clustering and semi-supervised classification on the graph learned from the original data matrix, which doesn't have explicit cluster structure, thus they might not achieve the optimal performance. By considering rank constraint, the achieved graph will have exactly $c$ connected components if there are $c$ clusters or classes. As a byproduct of this, graph learning and label inference are jointly and iteratively implemented in a principled way. Theoretically, we show that our model is equivalent to a combination of kernel k-means and k-means methods under certain condition. Extensive experiments on clustering and semi-supervised classification demonstrate that the proposed method outperforms other state-of-the-art methods.
Two-Dimensional Semi-Nonnegative Matrix Factorization for Clustering
May 19, 2020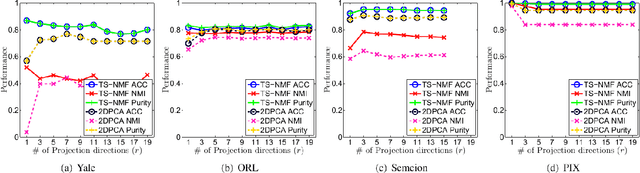
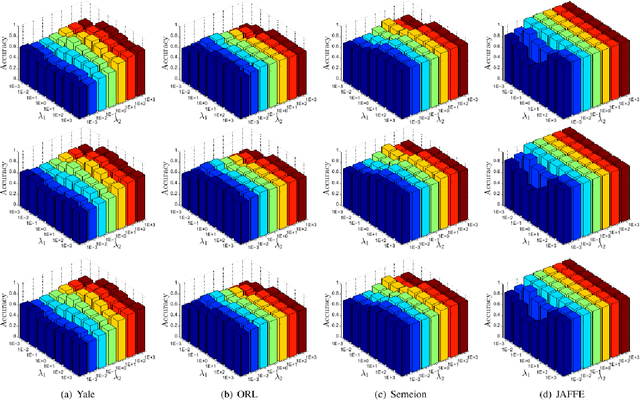
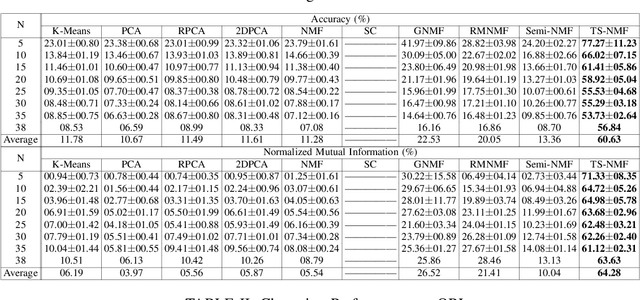
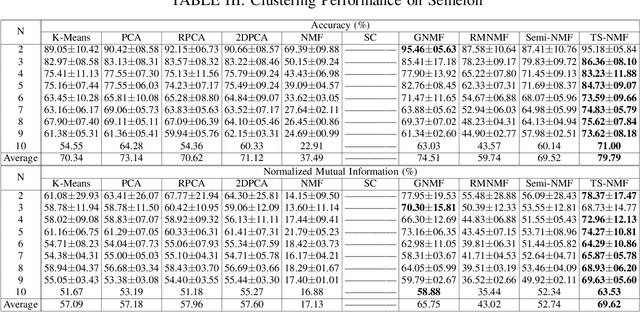
In this paper, we propose a new Semi-Nonnegative Matrix Factorization method for 2-dimensional (2D) data, named TS-NMF. It overcomes the drawback of existing methods that seriously damage the spatial information of the data by converting 2D data to vectors in a preprocessing step. In particular, projection matrices are sought under the guidance of building new data representations, such that the spatial information is retained and projections are enhanced by the goal of clustering, which helps construct optimal projection directions. Moreover, to exploit nonlinear structures of the data, manifold is constructed in the projected subspace, which is adaptively updated according to the projections and less afflicted with noise and outliers of the data and thus more representative in the projected space. Hence, seeking projections, building new data representations, and learning manifold are seamlessly integrated in a single model, which mutually enhance other and lead to a powerful data representation. Comprehensive experimental results verify the effectiveness of TS-NMF in comparison with several state-of-the-art algorithms, which suggests high potential of the proposed method for real world applications.
Nonnegative Matrix Factorization with Local Similarity Learning
Jul 09, 2019

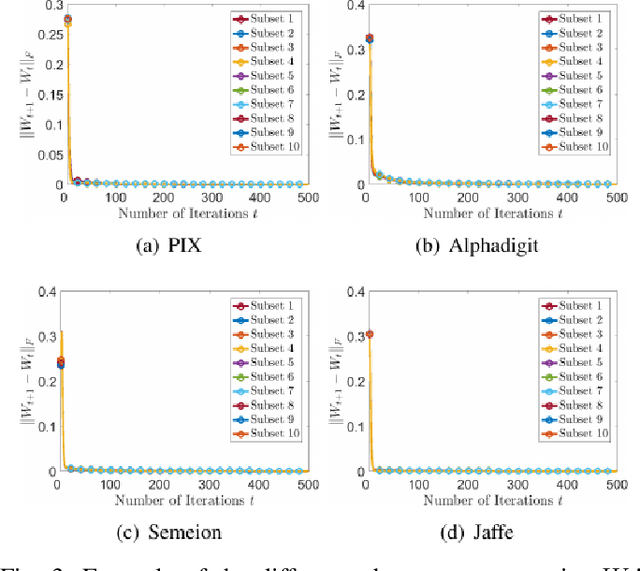
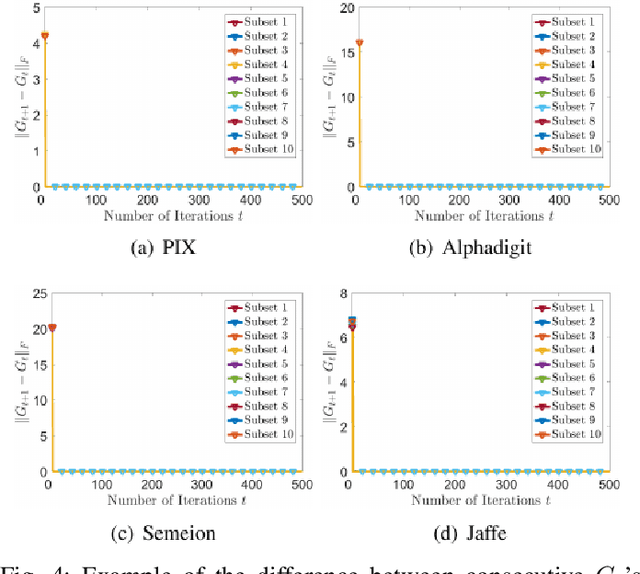
Existing nonnegative matrix factorization methods focus on learning global structure of the data to construct basis and coefficient matrices, which ignores the local structure that commonly exists among data. In this paper, we propose a new type of nonnegative matrix factorization method, which learns local similarity and clustering in a mutually enhancing way. The learned new representation is more representative in that it better reveals inherent geometric property of the data. Nonlinear expansion is given and efficient multiplicative updates are developed with theoretical convergence guarantees. Extensive experimental results have confirmed the effectiveness of the proposed model.
Automated Classification of Seizures against Nonseizures: A Deep Learning Approach
Jun 05, 2019
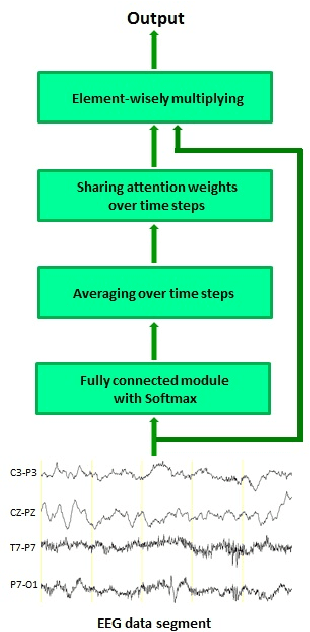
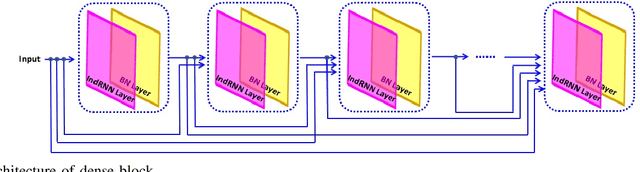
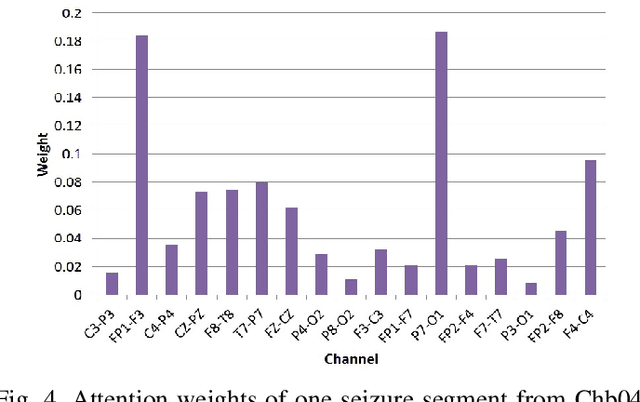
In current clinical practice, electroencephalograms (EEG) are reviewed and analyzed by well-trained neurologists to provide supports for therapeutic decisions. The way of manual reviewing is labor-intensive and error prone. Automatic and accurate seizure/nonseizure classification methods are needed. One major problem is that the EEG signals for seizure state and nonseizure state exhibit considerable variations. In order to capture essential seizure features, this paper integrates an emerging deep learning model, the independently recurrent neural network (IndRNN), with a dense structure and an attention mechanism to exploit temporal and spatial discriminating features and overcome seizure variabilities. The dense structure is to ensure maximum information flow between layers. The attention mechanism is to capture spatial features. Evaluations are performed in cross-validation experiments over the noisy CHB-MIT data set. The obtained average sensitivity, specificity and precision of 88.80%, 88.60% and 88.69% are better than using the current state-of-the-art methods. In addition, we explore how the segment length affects the classification performance. Thirteen different segment lengths are assessed, showing that the classification performance varies over the segment lengths, and the maximal fluctuating margin is more than 4%. Thus, the segment length is an important factor influencing the classification performance.
RES-PCA: A Scalable Approach to Recovering Low-rank Matrices
Apr 16, 2019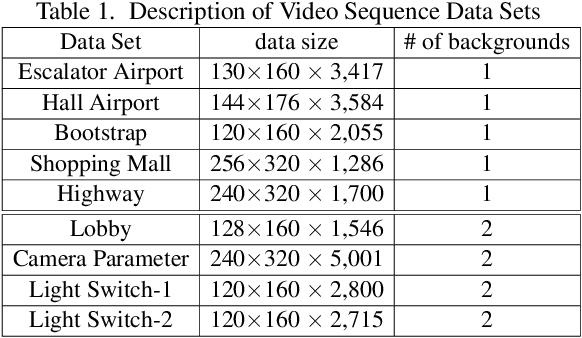

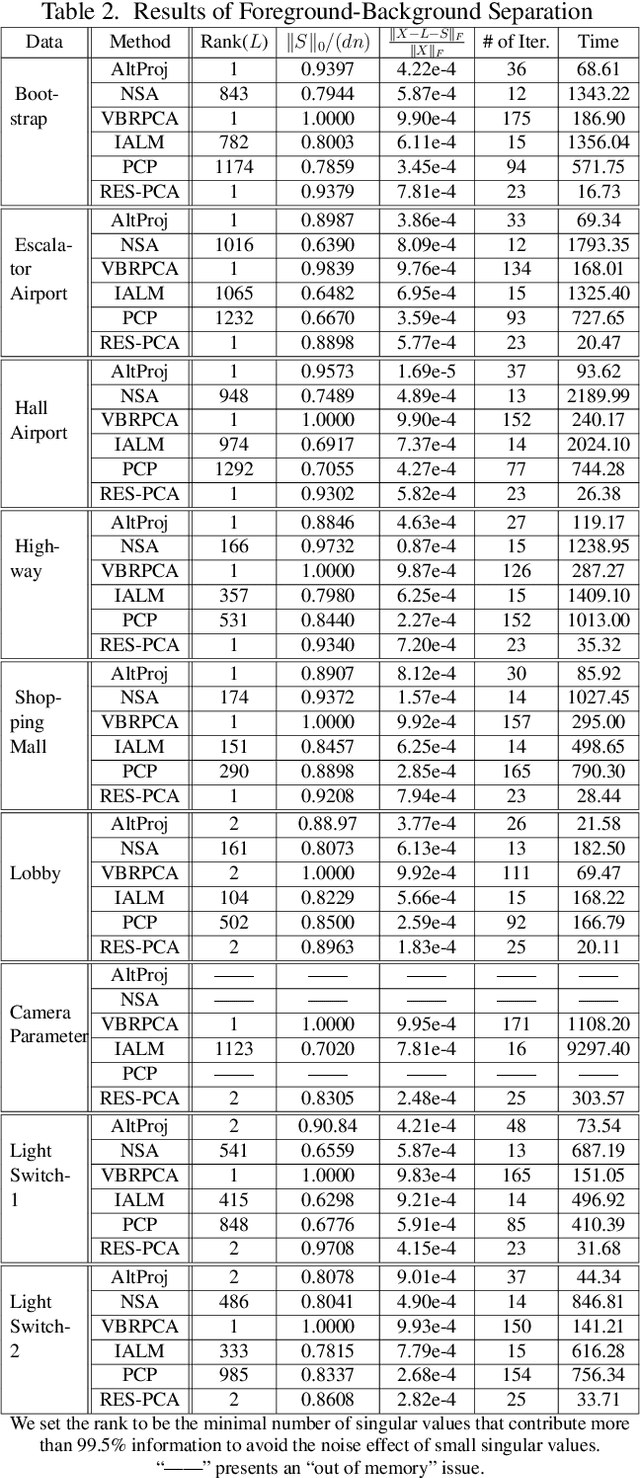

Robust principal component analysis (RPCA) has drawn significant attentions due to its powerful capability in recovering low-rank matrices as well as successful appplications in various real world problems. The current state-of-the-art algorithms usually need to solve singular value decomposition of large matrices, which generally has at least a quadratic or even cubic complexity. This drawback has limited the application of RPCA in solving real world problems. To combat this drawback, in this paper we propose a new type of RPCA method, RES-PCA, which is linearly efficient and scalable in both data size and dimension. For comparison purpose, AltProj, an existing scalable approach to RPCA requires the precise knowlwdge of the true rank; otherwise, it may fail to recover low-rank matrices. By contrast, our method works with or without knowing the true rank; even when both methods work, our method is faster. Extensive experiments have been performed and testified to the effectiveness of proposed method quantitatively and in visual quality, which suggests that our method is suitable to be employed as a light-weight, scalable component for RPCA in any application pipelines.
Discriminative Regression Machine: A Classifier for High-Dimensional Data or Imbalanced Data
Apr 16, 2019
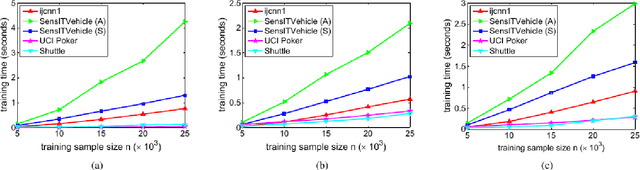
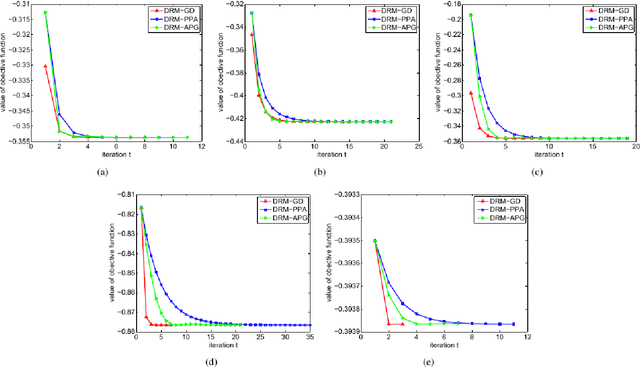
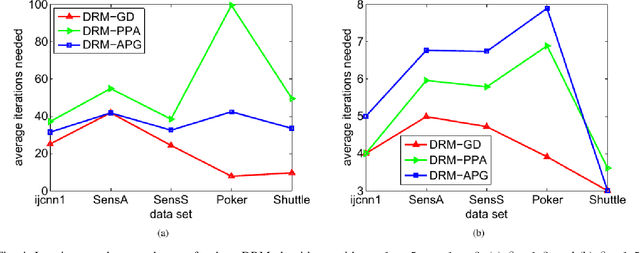
We introduce a discriminative regression approach to supervised classification in this paper. It estimates a representation model while accounting for discriminativeness between classes, thereby enabling accurate derivation of categorical information. This new type of regression models extends existing models such as ridge, lasso, and group lasso through explicitly incorporating discriminative information. As a special case we focus on a quadratic model that admits a closed-form analytical solution. The corresponding classifier is called discriminative regression machine (DRM). Three iterative algorithms are further established for the DRM to enhance the efficiency and scalability for real applications. Our approach and the algorithms are applicable to general types of data including images, high-dimensional data, and imbalanced data. We compare the DRM with currently state-of-the-art classifiers. Our extensive experimental results show superior performance of the DRM and confirm the effectiveness of the proposed approach.
A Novel Independent RNN Approach to Classification of Seizures against Non-seizures
Mar 22, 2019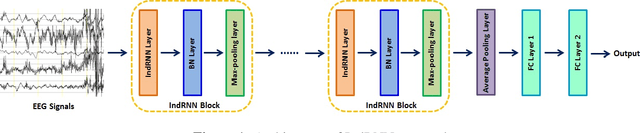
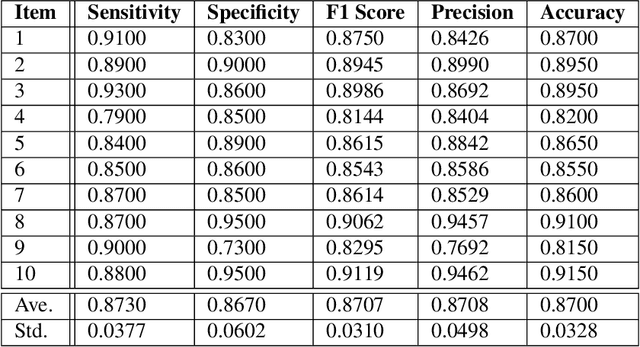
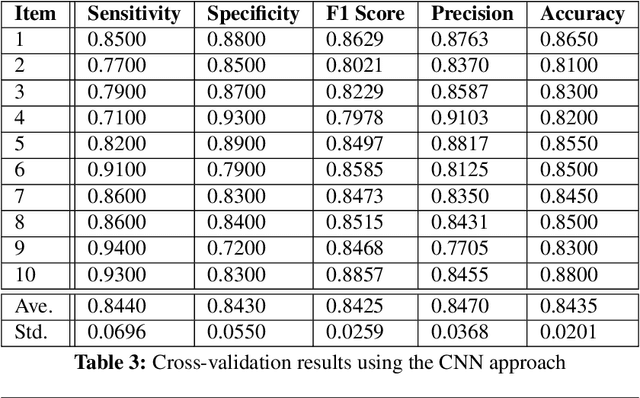
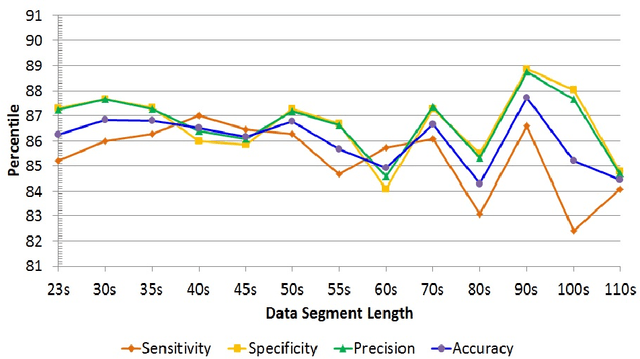
In current clinical practices, electroencephalograms (EEG) are reviewed and analyzed by trained neurologists to provide supports for therapeutic decisions. Manual reviews can be laborious and error prone. Automatic and accurate seizure/non-seizure classification methods are desirable. A critical challenge is that seizure morphologies exhibit considerable variabilities. In order to capture essential seizure features, this paper leverages an emerging deep learning model, the independently recurrent neural network (IndRNN), to construct a new approach for the seizure/non-seizure classification. This new approach gradually expands the time scales, thereby extracting temporal and spatial features from the local time duration to the entire record. Evaluations are conducted with cross-validation experiments across subjects over the noisy data of CHB-MIT. Experimental results demonstrate that the proposed approach outperforms the current state-of-the-art methods. In addition, we explore how the segment length affects the classification performance. Thirteen different segment lengths are assessed, showing that the classification performance varies over the segment lengths, and the maximal fluctuating margin is more than 4%. Thus, the segment length is an important factor influencing the classification performance.