 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Optimization Methods for the Quantification Problem
Jun 13, 2016
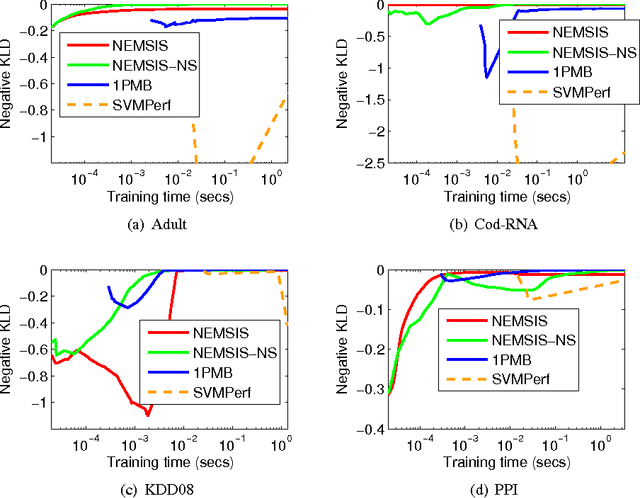


The estimation of class prevalence, i.e., the fraction of a population that belongs to a certain class, is a very useful tool in data analytics and learning, and finds applications in many domains such as sentiment analysis, epidemiology, etc. For example, in sentiment analysis, the objective is often not to estimate whether a specific text conveys a positive or a negative sentiment, but rather estimate the overall distribution of positive and negative sentiments during an event window. A popular way of performing the above task, often dubbed quantification, is to use supervised learning to train a prevalence estimator from labeled data. Contemporary literature cites several performance measures used to measure the success of such prevalence estimators. In this paper we propose the first online stochastic algorithms for directly optimizing these quantification-specific performance measures. We also provide algorithms that optimize hybrid performance measures that seek to balance quantification and classification performance. Our algorithms present a significant advancement in the theory of multivariate optimization and we show, by a rigorous theoretical analysis, that they exhibit optimal convergence. We also report extensive experiments on benchmark and real data sets which demonstrate that our methods significantly outperform existing optimization techniques used for these performance measures.
Locally Non-linear Embeddings for Extreme Multi-label Learning
Jul 09, 2015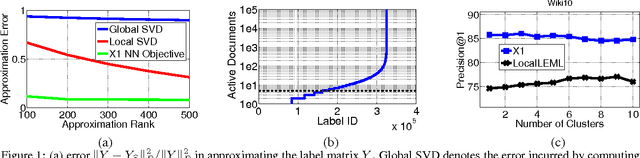
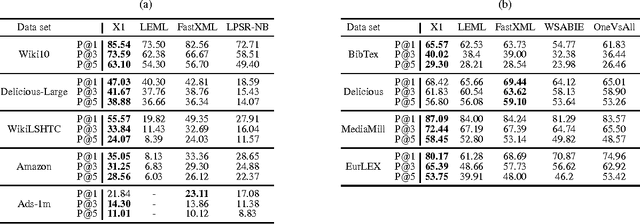

The objective in extreme multi-label learning is to train a classifier that can automatically tag a novel data point with the most relevant subset of labels from an extremely large label set. Embedding based approaches make training and prediction tractable by assuming that the training label matrix is low-rank and hence the effective number of labels can be reduced by projecting the high dimensional label vectors onto a low dimensional linear subspace. Still, leading embedding approaches have been unable to deliver high prediction accuracies or scale to large problems as the low rank assumption is violated in most real world applications. This paper develops the X-One classifier to address both limitations. The main technical contribution in X-One is a formulation for learning a small ensemble of local distance preserving embeddings which can accurately predict infrequently occurring (tail) labels. This allows X-One to break free of the traditional low-rank assumption and boost classification accuracy by learning embeddings which preserve pairwise distances between only the nearest label vectors. We conducted extensive experiments on several real-world as well as benchmark data sets and compared our method against state-of-the-art methods for extreme multi-label classification. Experiments reveal that X-One can make significantly more accurate predictions then the state-of-the-art methods including both embeddings (by as much as 35%) as well as trees (by as much as 6%). X-One can also scale efficiently to data sets with a million labels which are beyond the pale of leading embedding methods.
Robust Regression via Hard Thresholding
Jun 08, 2015


We study the problem of Robust Least Squares Regression (RLSR) where several response variables can be adversarially corrupted. More specifically, for a data matrix X \in R^{p x n} and an underlying model w*, the response vector is generated as y = X'w* + b where b \in R^n is the corruption vector supported over at most C.n coordinates. Existing exact recovery results for RLSR focus solely on L1-penalty based convex formulations and impose relatively strict model assumptions such as requiring the corruptions b to be selected independently of X. In this work, we study a simple hard-thresholding algorithm called TORRENT which, under mild conditions on X, can recover w* exactly even if b corrupts the response variables in an adversarial manner, i.e. both the support and entries of b are selected adversarially after observing X and w*. Our results hold under deterministic assumptions which are satisfied if X is sampled from any sub-Gaussian distribution. Finally unlike existing results that apply only to a fixed w*, generated independently of X, our results are universal and hold for any w* \in R^p. Next, we propose gradient descent-based extensions of TORRENT that can scale efficiently to large scale problems, such as high dimensional sparse recovery and prove similar recovery guarantees for these extensions. Empirically we find TORRENT, and more so its extensions, offering significantly faster recovery than the state-of-the-art L1 solvers. For instance, even on moderate-sized datasets (with p = 50K) with around 40% corrupted responses, a variant of our proposed method called TORRENT-HYB is more than 20x faster than the best L1 solver.
Surrogate Functions for Maximizing Precision at the Top
May 26, 2015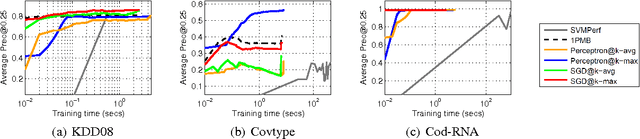
The problem of maximizing precision at the top of a ranked list, often dubbed Precision@k (prec@k), finds relevance in myriad learning applications such as ranking, multi-label classification, and learning with severe label imbalance. However, despite its popularity, there exist significant gaps in our understanding of this problem and its associated performance measure. The most notable of these is the lack of a convex upper bounding surrogate for prec@k. We also lack scalable perceptron and stochastic gradient descent algorithms for optimizing this performance measure. In this paper we make key contributions in these directions. At the heart of our results is a family of truly upper bounding surrogates for prec@k. These surrogates are motivated in a principled manner and enjoy attractive properties such as consistency to prec@k under various natural margin/noise conditions. These surrogates are then used to design a class of novel perceptron algorithms for optimizing prec@k with provable mistake bounds. We also devise scalable stochastic gradient descent style methods for this problem with provable convergence bounds. Our proofs rely on novel uniform convergence bounds which require an in-depth analysis of the structural properties of prec@k and its surrogates. We conclude with experimental results comparing our algorithms with state-of-the-art cutting plane and stochastic gradient algorithms for maximizing prec@k.
* To appear in the the proceedings of the 32nd International Conference on Machine Learning (ICML 2015)
Optimizing Non-decomposable Performance Measures: A Tale of Two Classes
May 26, 2015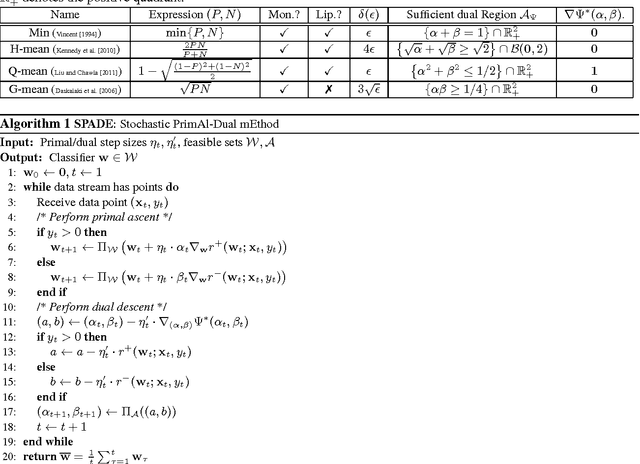



Modern classification problems frequently present mild to severe label imbalance as well as specific requirements on classification characteristics, and require optimizing performance measures that are non-decomposable over the dataset, such as F-measure. Such measures have spurred much interest and pose specific challenges to learning algorithms since their non-additive nature precludes a direct application of well-studied large scale optimization methods such as stochastic gradient descent. In this paper we reveal that for two large families of performance measures that can be expressed as functions of true positive/negative rates, it is indeed possible to implement point stochastic updates. The families we consider are concave and pseudo-linear functions of TPR, TNR which cover several popularly used performance measures such as F-measure, G-mean and H-mean. Our core contribution is an adaptive linearization scheme for these families, using which we develop optimization techniques that enable truly point-based stochastic updates. For concave performance measures we propose SPADE, a stochastic primal dual solver; for pseudo-linear measures we propose STAMP, a stochastic alternate maximization procedure. Both methods have crisp convergence guarantees, demonstrate significant speedups over existing methods - often by an order of magnitude or more, and give similar or more accurate predictions on test data.
* To appear in proceedings of the 32nd International Conference on Machine Learning (ICML 2015)
Online and Stochastic Gradient Methods for Non-decomposable Loss Functions
Oct 24, 2014
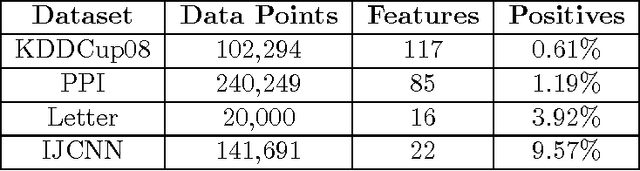
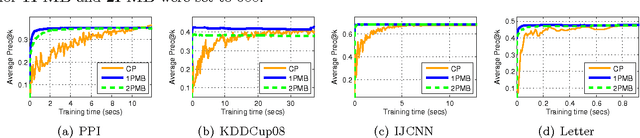
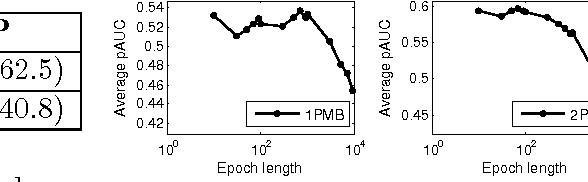
Modern applications in sensitive domains such as biometrics and medicine frequently require the use of non-decomposable loss functions such as precision@k, F-measure etc. Compared to point loss functions such as hinge-loss, these offer much more fine grained control over prediction, but at the same time present novel challenges in terms of algorithm design and analysis. In this work we initiate a study of online learning techniques for such non-decomposable loss functions with an aim to enable incremental learning as well as design scalable solvers for batch problems. To this end, we propose an online learning framework for such loss functions. Our model enjoys several nice properties, chief amongst them being the existence of efficient online learning algorithms with sublinear regret and online to batch conversion bounds. Our model is a provable extension of existing online learning models for point loss functions. We instantiate two popular losses, prec@k and pAUC, in our model and prove sublinear regret bounds for both of them. Our proofs require a novel structural lemma over ranked lists which may be of independent interest. We then develop scalable stochastic gradient descent solvers for non-decomposable loss functions. We show that for a large family of loss functions satisfying a certain uniform convergence property (that includes prec@k, pAUC, and F-measure), our methods provably converge to the empirical risk minimizer. Such uniform convergence results were not known for these losses and we establish these using novel proof techniques. We then use extensive experimentation on real life and benchmark datasets to establish that our method can be orders of magnitude faster than a recently proposed cutting plane method.
On Iterative Hard Thresholding Methods for High-dimensional M-Estimation
Oct 21, 2014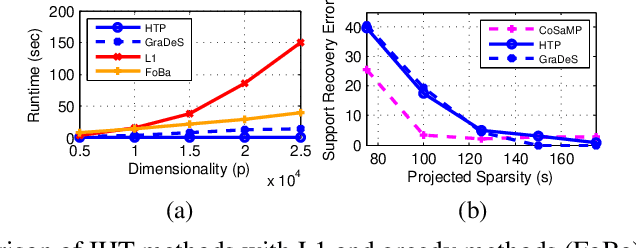
The use of M-estimators in generalized linear regression models in high dimensional settings requires risk minimization with hard $L_0$ constraints. Of the known methods, the class of projected gradient descent (also known as iterative hard thresholding (IHT)) methods is known to offer the fastest and most scalable solutions. However, the current state-of-the-art is only able to analyze these methods in extremely restrictive settings which do not hold in high dimensional statistical models. In this work we bridge this gap by providing the first analysis for IHT-style methods in the high dimensional statistical setting. Our bounds are tight and match known minimax lower bounds. Our results rely on a general analysis framework that enables us to analyze several popular hard thresholding style algorithms (such as HTP, CoSaMP, SP) in the high dimensional regression setting. We also extend our analysis to a large family of "fully corrective methods" that includes two-stage and partial hard-thresholding algorithms. We show that our results hold for the problem of sparse regression, as well as low-rank matrix recovery.
Large-scale Multi-label Learning with Missing Labels
Nov 25, 2013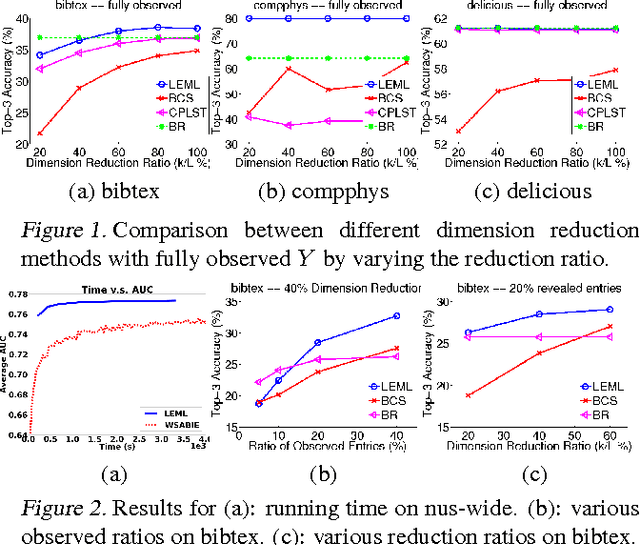
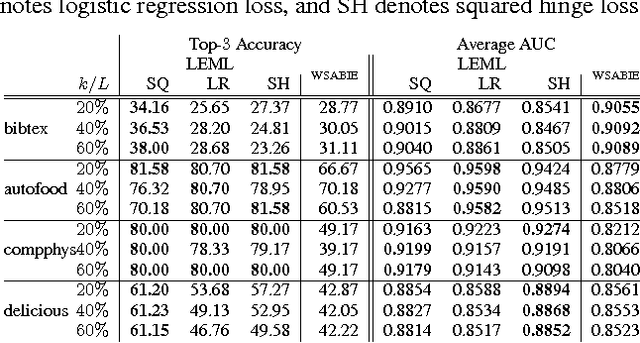
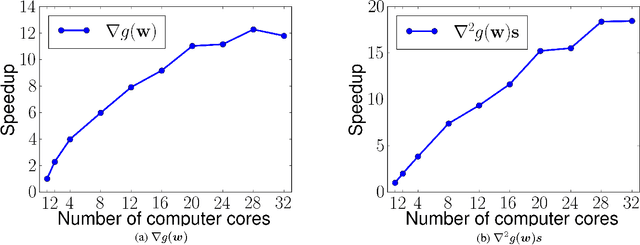
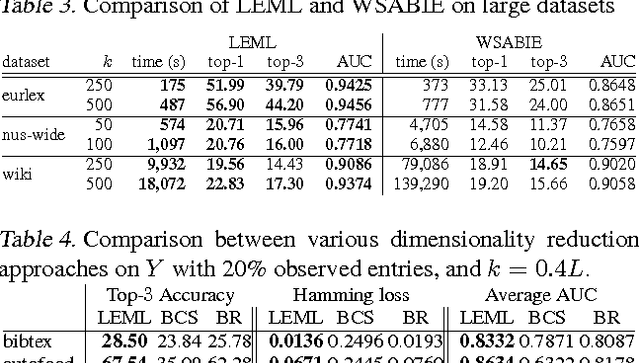
The multi-label classification problem has generated significant interest in recent years. However, existing approaches do not adequately address two key challenges: (a) the ability to tackle problems with a large number (say millions) of labels, and (b) the ability to handle data with missing labels. In this paper, we directly address both these problems by studying the multi-label problem in a generic empirical risk minimization (ERM) framework. Our framework, despite being simple, is surprisingly able to encompass several recent label-compression based methods which can be derived as special cases of our method. To optimize the ERM problem, we develop techniques that exploit the structure of specific loss functions - such as the squared loss function - to offer efficient algorithms. We further show that our learning framework admits formal excess risk bounds even in the presence of missing labels. Our risk bounds are tight and demonstrate better generalization performance for low-rank promoting trace-norm regularization when compared to (rank insensitive) Frobenius norm regularization. Finally, we present extensive empirical results on a variety of benchmark datasets and show that our methods perform significantly better than existing label compression based methods and can scale up to very large datasets such as the Wikipedia dataset.
On the Generalization Ability of Online Learning Algorithms for Pairwise Loss Functions
May 11, 2013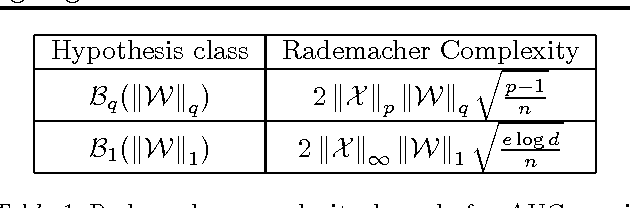
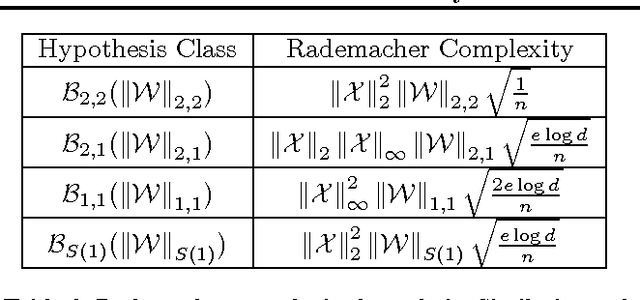

In this paper, we study the generalization properties of online learning based stochastic methods for supervised learning problems where the loss function is dependent on more than one training sample (e.g., metric learning, ranking). We present a generic decoupling technique that enables us to provide Rademacher complexity-based generalization error bounds. Our bounds are in general tighter than those obtained by Wang et al (COLT 2012) for the same problem. Using our decoupling technique, we are further able to obtain fast convergence rates for strongly convex pairwise loss functions. We are also able to analyze a class of memory efficient online learning algorithms for pairwise learning problems that use only a bounded subset of past training samples to update the hypothesis at each step. Finally, in order to complement our generalization bounds, we propose a novel memory efficient online learning algorithm for higher order learning problems with bounded regret guarantees.
* To appear in proceedings of the 30th International Conference on Machine Learning (ICML 2013)
On Translation Invariant Kernels and Screw Functions
Feb 18, 2013We explore the connection between Hilbertian metrics and positive definite kernels on the real line. In particular, we look at a well-known characterization of translation invariant Hilbertian metrics on the real line by von Neumann and Schoenberg (1941). Using this result we are able to give an alternate proof of Bochner's theorem for translation invariant positive definite kernels on the real line (Rudin, 1962).