 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFootprint-Guided Exemplar-Free Continual Histopathology Report Generation
Feb 27, 2026Rapid progress in vision-language modeling has enabled pathology report generation from gigapixel whole-slide images, but most approaches assume static training with simultaneous access to all data. In clinical deployment, however, new organs, institutions, and reporting conventions emerge over time, and sequential fine-tuning can cause catastrophic forgetting. We introduce an exemplar-free continual learning framework for WSI-to-report generation that avoids storing raw slides or patch exemplars. The core idea is a compact domain footprint built in a frozen patch-embedding space: a small codebook of representative morphology tokens together with slide-level co-occurrence summaries and lightweight patch-count priors. These footprints support generative replay by synthesizing pseudo-WSI representations that reflect domain-specific morphological mixtures, while a teacher snapshot provides pseudo-reports to supervise the updated model without retaining past data. To address shifting reporting conventions, we distill domain-specific linguistic characteristics into a compact style descriptor and use it to steer generation. At inference, the model identifies the most compatible descriptor directly from the slide signal, enabling domain-agnostic setup without requiring explicit domain identifiers. Evaluated across multiple public continual learning benchmarks, our approach outperforms exemplar-free and limited-buffer rehearsal baselines, highlighting footprint-based generative replay as a practical solution for deployment in evolving clinical settings.
Concept Drift Challenge in Multimedia Anomaly Detection: A Case Study with Facial Datasets
Jul 27, 2022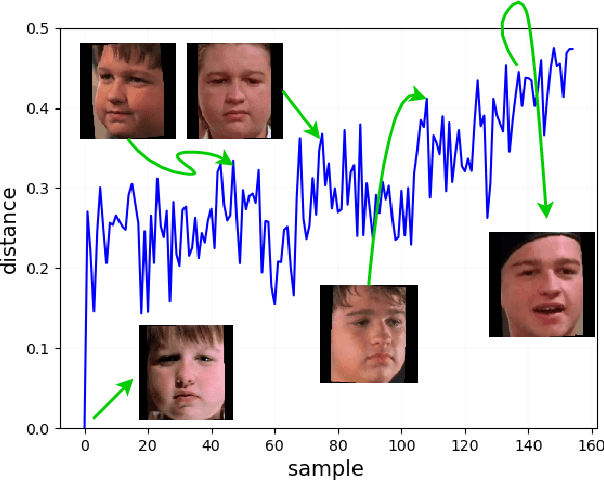
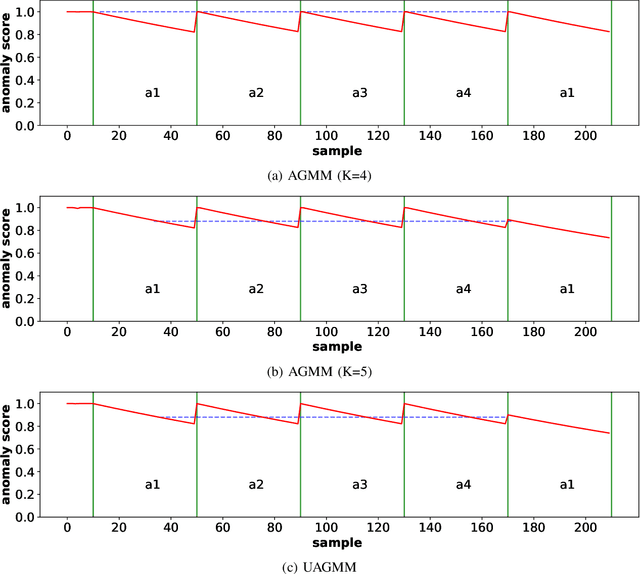
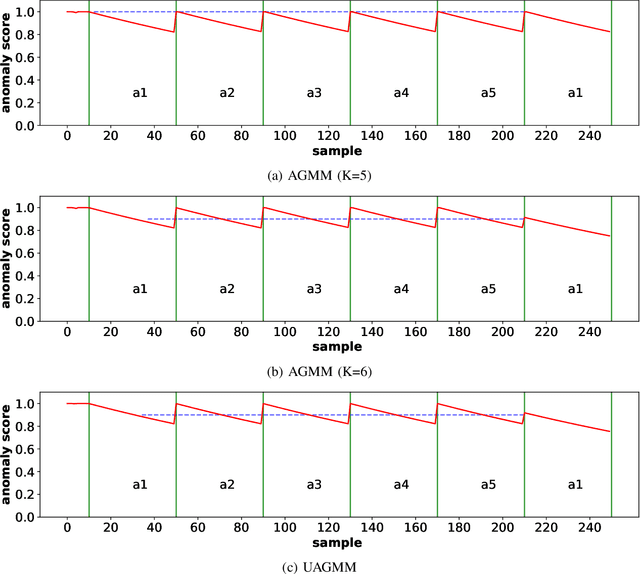
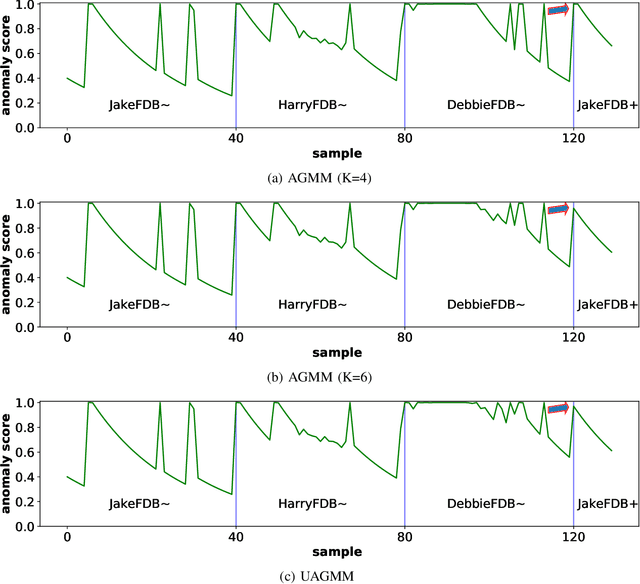
Anomaly detection in multimedia datasets is a widely studied area. Yet, the concept drift challenge in data has been ignored or poorly handled by the majority of the anomaly detection frameworks. The state-of-the-art approaches assume that the data distribution at training and deployment time will be the same. However, due to various real-life environmental factors, the data may encounter drift in its distribution or can drift from one class to another in the late future. Thus, a one-time trained model might not perform adequately. In this paper, we systematically investigate the effect of concept drift on various detection models and propose a modified Adaptive Gaussian Mixture Model (AGMM) based framework for anomaly detection in multimedia data. In contrast to the baseline AGMM, the proposed extension of AGMM remembers the past for a longer period in order to handle the drift better. Extensive experimental analysis shows that the proposed model better handles the drift in data as compared with the baseline AGMM. Further, to facilitate research and comparison with the proposed framework, we contribute three multimedia datasets constituting faces as samples. The face samples of individuals correspond to the age difference of more than ten years to incorporate a longer temporal context.