 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan we Debias Social Stereotypes in AI-Generated Images? Examining Text-to-Image Outputs and User Perceptions
May 27, 2025



Recent advances in generative AI have enabled visual content creation through text-to-image (T2I) generation. However, despite their creative potential, T2I models often replicate and amplify societal stereotypes -- particularly those related to gender, race, and culture -- raising important ethical concerns. This paper proposes a theory-driven bias detection rubric and a Social Stereotype Index (SSI) to systematically evaluate social biases in T2I outputs. We audited three major T2I model outputs -- DALL-E-3, Midjourney-6.1, and Stability AI Core -- using 100 queries across three categories -- geocultural, occupational, and adjectival. Our analysis reveals that initial outputs are prone to include stereotypical visual cues, including gendered professions, cultural markers, and western beauty norms. To address this, we adopted our rubric to conduct targeted prompt refinement using LLMs, which significantly reduced bias -- SSI dropped by 61% for geocultural, 69% for occupational, and 51% for adjectival queries. We complemented our quantitative analysis through a user study examining perceptions, awareness, and preferences around AI-generated biased imagery. Our findings reveal a key tension -- although prompt refinement can mitigate stereotypes, it can limit contextual alignment. Interestingly, users often perceived stereotypical images to be more aligned with their expectations. We discuss the need to balance ethical debiasing with contextual relevance and call for T2I systems that support global diversity and inclusivity while not compromising the reflection of real-world social complexity.
Algorithmic Behaviors Across Regions: A Geolocation Audit of YouTube Search for COVID-19 Misinformation between the United States and South Africa
Sep 16, 2024Despite being an integral tool for finding health-related information online, YouTube has faced criticism for disseminating COVID-19 misinformation globally to its users. Yet, prior audit studies have predominantly investigated YouTube within the Global North contexts, often overlooking the Global South. To address this gap, we conducted a comprehensive 10-day geolocation-based audit on YouTube to compare the prevalence of COVID-19 misinformation in search results between the United States (US) and South Africa (SA), the countries heavily affected by the pandemic in the Global North and the Global South, respectively. For each country, we selected 3 geolocations and placed sock-puppets, or bots emulating "real" users, that collected search results for 48 search queries sorted by 4 search filters for 10 days, yielding a dataset of 915K results. We found that 31.55% of the top-10 search results contained COVID-19 misinformation. Among the top-10 search results, bots in SA faced significantly more misinformative search results than their US counterparts. Overall, our study highlights the contrasting algorithmic behaviors of YouTube search between two countries, underscoring the need for the platform to regulate algorithmic behavior consistently across different regions of the Globe.
Dissecting users' needs for search result explanations
Jan 29, 2024



There is a growing demand for transparency in search engines to understand how search results are curated and to enhance users' trust. Prior research has introduced search result explanations with a focus on how to explain, assuming explanations are beneficial. Our study takes a step back to examine if search explanations are needed and when they are likely to provide benefits. Additionally, we summarize key characteristics of helpful explanations and share users' perspectives on explanation features provided by Google and Bing. Interviews with non-technical individuals reveal that users do not always seek or understand search explanations and mostly desire them for complex and critical tasks. They find Google's search explanations too obvious but appreciate the ability to contest search results. Based on our findings, we offer design recommendations for search engines and explanations to help users better evaluate search results and enhance their search experience.
Anvaya: An Algorithm and Case-Study on Improving the Goodness of Software Process Models generated by Mining Event-Log Data in Issue Tracking System
Nov 22, 2015
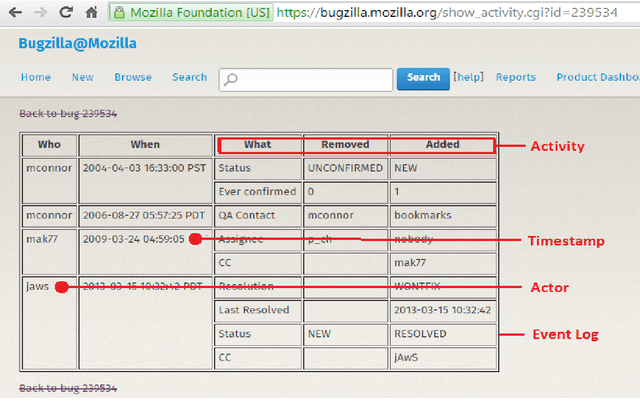
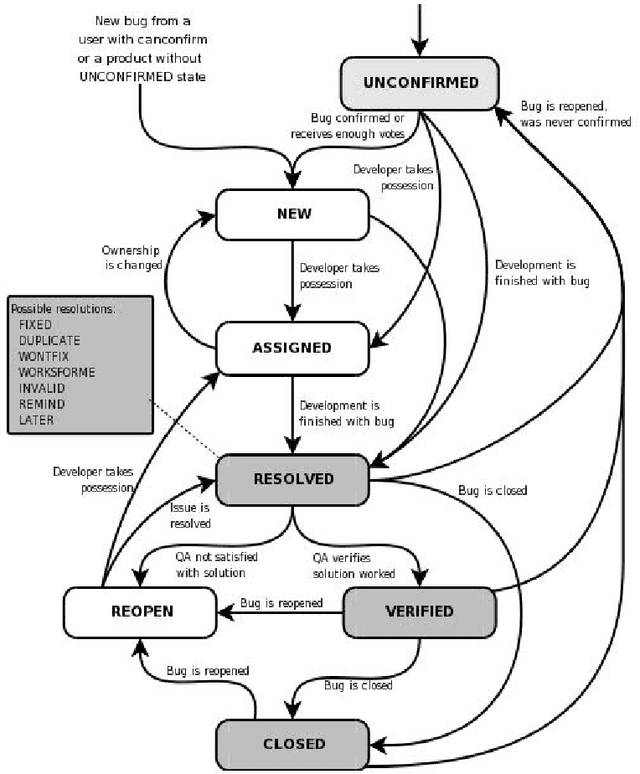
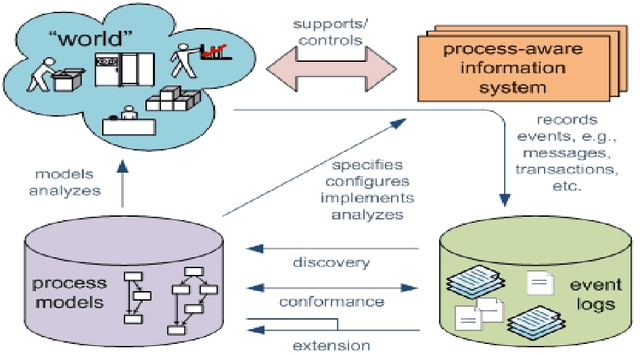
Issue Tracking Systems (ITS) such as Bugzilla can be viewed as Process Aware Information Systems (PAIS) generating event-logs during the life-cycle of a bug report. Process Mining consists of mining event logs generated from PAIS for process model discovery, conformance and enhancement. We apply process map discovery techniques to mine event trace data generated from ITS of open source Firefox browser project to generate and study process models. Bug life-cycle consists of diversity and variance. Therefore, the process models generated from the event-logs are spaghetti-like with large number of edges, inter-connections and nodes. Such models are complex to analyse and difficult to comprehend by a process analyst. We improve the Goodness (fitness and structural complexity) of the process models by splitting the event-log into homogeneous subsets by clustering structurally similar traces. We adapt the K-Medoid clustering algorithm with two different distance metrics: Longest Common Subsequence (LCS) and Dynamic Time Warping (DTW). We evaluate the goodness of the process models generated from the clusters using complexity and fitness metrics. We study back-forth \& self-loops, bug reopening, and bottleneck in the clusters obtained and show that clustering enables better analysis. We also propose an algorithm to automate the clustering process -the algorithm takes as input the event log and returns the best cluster set.