 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDAR: Sensing Linear Probing Performance in Joint Embedding SSL Architectures
Dec 07, 2023



Joint embedding (JE) architectures have emerged as a promising avenue for acquiring transferable data representations. A key obstacle to using JE methods, however, is the inherent challenge of evaluating learned representations without access to a downstream task, and an annotated dataset. Without efficient and reliable evaluation, it is difficult to iterate on architectural and training choices for JE methods. In this paper, we introduce LiDAR (Linear Discriminant Analysis Rank), a metric designed to measure the quality of representations within JE architectures. Our metric addresses several shortcomings of recent approaches based on feature covariance rank by discriminating between informative and uninformative features. In essence, LiDAR quantifies the rank of the Linear Discriminant Analysis (LDA) matrix associated with the surrogate SSL task -- a measure that intuitively captures the information content as it pertains to solving the SSL task. We empirically demonstrate that LiDAR significantly surpasses naive rank based approaches in its predictive power of optimal hyperparameters. Our proposed criterion presents a more robust and intuitive means of assessing the quality of representations within JE architectures, which we hope facilitates broader adoption of these powerful techniques in various domains.
Vanishing Gradients in Reinforcement Finetuning of Language Models
Oct 31, 2023



Pretrained language models are commonly aligned with human preferences and downstream tasks via reinforcement finetuning (RFT), which entails maximizing a (possibly learned) reward function using policy gradient algorithms. This work highlights a fundamental optimization obstacle in RFT: we prove that the expected gradient for an input vanishes when its reward standard deviation under the model is small, even if the expected reward is far from optimal. Through experiments on an RFT benchmark and controlled environments, as well as a theoretical analysis, we then demonstrate that vanishing gradients due to small reward standard deviation are prevalent and detrimental, leading to extremely slow reward maximization. Lastly, we explore ways to overcome vanishing gradients in RFT. We find the common practice of an initial supervised finetuning (SFT) phase to be the most promising candidate, which sheds light on its importance in an RFT pipeline. Moreover, we show that a relatively small number of SFT optimization steps on as few as 1% of the input samples can suffice, indicating that the initial SFT phase need not be expensive in terms of compute and data labeling efforts. Overall, our results emphasize that being mindful for inputs whose expected gradient vanishes, as measured by the reward standard deviation, is crucial for successful execution of RFT.
What Algorithms can Transformers Learn? A Study in Length Generalization
Oct 24, 2023



Large language models exhibit surprising emergent generalization properties, yet also struggle on many simple reasoning tasks such as arithmetic and parity. This raises the question of if and when Transformer models can learn the true algorithm for solving a task. We study the scope of Transformers' abilities in the specific setting of length generalization on algorithmic tasks. Here, we propose a unifying framework to understand when and how Transformers can exhibit strong length generalization on a given task. Specifically, we leverage RASP (Weiss et al., 2021) -- a programming language designed for the computational model of a Transformer -- and introduce the RASP-Generalization Conjecture: Transformers tend to length generalize on a task if the task can be solved by a short RASP program which works for all input lengths. This simple conjecture remarkably captures most known instances of length generalization on algorithmic tasks. Moreover, we leverage our insights to drastically improve generalization performance on traditionally hard tasks (such as parity and addition). On the theoretical side, we give a simple example where the "min-degree-interpolator" model of learning from Abbe et al. (2023) does not correctly predict Transformers' out-of-distribution behavior, but our conjecture does. Overall, our work provides a novel perspective on the mechanisms of compositional generalization and the algorithmic capabilities of Transformers.
Smooth ECE: Principled Reliability Diagrams via Kernel Smoothing
Sep 21, 2023Calibration measures and reliability diagrams are two fundamental tools for measuring and interpreting the calibration of probabilistic predictors. Calibration measures quantify the degree of miscalibration, and reliability diagrams visualize the structure of this miscalibration. However, the most common constructions of reliability diagrams and calibration measures -- binning and ECE -- both suffer from well-known flaws (e.g. discontinuity). We show that a simple modification fixes both constructions: first smooth the observations using an RBF kernel, then compute the Expected Calibration Error (ECE) of this smoothed function. We prove that with a careful choice of bandwidth, this method yields a calibration measure that is well-behaved in the sense of (B{\l}asiok, Gopalan, Hu, and Nakkiran 2023a) -- a consistent calibration measure. We call this measure the SmoothECE. Moreover, the reliability diagram obtained from this smoothed function visually encodes the SmoothECE, just as binned reliability diagrams encode the BinnedECE. We also provide a Python package with simple, hyperparameter-free methods for measuring and plotting calibration: `pip install relplot\`.
When Does Optimizing a Proper Loss Yield Calibration?
May 30, 2023Optimizing proper loss functions is popularly believed to yield predictors with good calibration properties; the intuition being that for such losses, the global optimum is to predict the ground-truth probabilities, which is indeed calibrated. However, typical machine learning models are trained to approximately minimize loss over restricted families of predictors, that are unlikely to contain the ground truth. Under what circumstances does optimizing proper loss over a restricted family yield calibrated models? What precise calibration guarantees does it give? In this work, we provide a rigorous answer to these questions. We replace the global optimality with a local optimality condition stipulating that the (proper) loss of the predictor cannot be reduced much by post-processing its predictions with a certain family of Lipschitz functions. We show that any predictor with this local optimality satisfies smooth calibration as defined in Kakade-Foster (2008), B{\l}asiok et al. (2023). Local optimality is plausibly satisfied by well-trained DNNs, which suggests an explanation for why they are calibrated from proper loss minimization alone. Finally, we show that the connection between local optimality and calibration error goes both ways: nearly calibrated predictors are also nearly locally optimal.
Loss minimization yields multicalibration for large neural networks
Apr 19, 2023Multicalibration is a notion of fairness that aims to provide accurate predictions across a large set of groups. Multicalibration is known to be a different goal than loss minimization, even for simple predictors such as linear functions. In this note, we show that for (almost all) large neural network sizes, optimally minimizing squared error leads to multicalibration. Our results are about representational aspects of neural networks, and not about algorithmic or sample complexity considerations. Previous such results were known only for predictors that were nearly Bayes-optimal and were therefore representation independent. We emphasize that our results do not apply to specific algorithms for optimizing neural networks, such as SGD, and they should not be interpreted as "fairness comes for free from optimizing neural networks".
A Unifying Theory of Distance from Calibration
Nov 30, 2022We study the fundamental question of how to define and measure the distance from calibration for probabilistic predictors. While the notion of perfect calibration is well-understood, there is no consensus on how to quantify the distance from perfect calibration. Numerous calibration measures have been proposed in the literature, but it is unclear how they compare to each other, and many popular measures such as Expected Calibration Error (ECE) fail to satisfy basic properties like continuity. We present a rigorous framework for analyzing calibration measures, inspired by the literature on property testing. We propose a ground-truth notion of distance from calibration: the $\ell_1$ distance to the nearest perfectly calibrated predictor. We define a consistent calibration measure as one that is a polynomial factor approximation to the this distance. Applying our framework, we identify three calibration measures that are consistent and can be estimated efficiently: smooth calibration, interval calibration, and Laplace kernel calibration. The former two give quadratic approximations to the ground truth distance, which we show is information-theoretically optimal. Our work thus establishes fundamental lower and upper bounds on measuring distance to calibration, and also provides theoretical justification for preferring certain metrics (like Laplace kernel calibration) in practice.
APE: Aligning Pretrained Encoders to Quickly Learn Aligned Multimodal Representations
Oct 08, 2022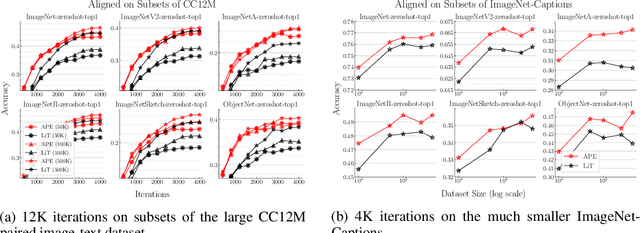
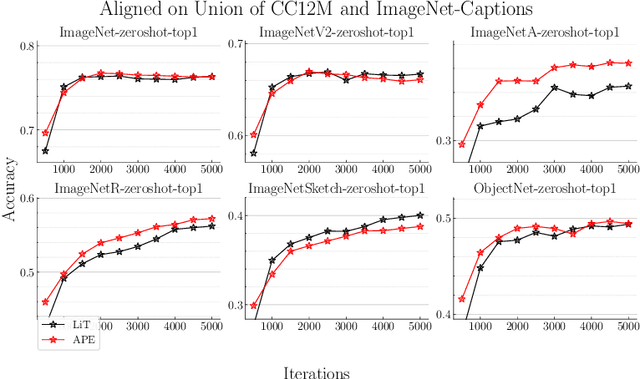
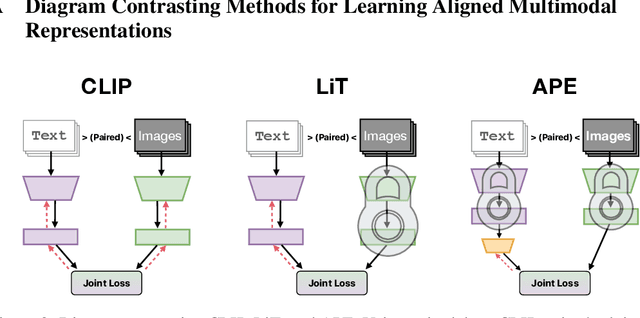
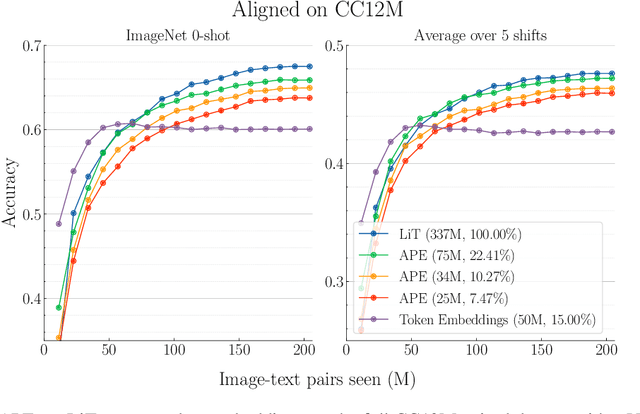
Recent advances in learning aligned multimodal representations have been primarily driven by training large neural networks on massive, noisy paired-modality datasets. In this work, we ask whether it is possible to achieve similar results with substantially less training time and data. We achieve this by taking advantage of existing pretrained unimodal encoders and careful curation of alignment data relevant to the downstream task of interest. We study a natural approach to aligning existing encoders via small auxiliary functions, and we find that this method is competitive with (or outperforms) state of the art in many settings while being less prone to overfitting, less costly to train, and more robust to distribution shift. With a properly chosen alignment distribution, our method surpasses prior state of the art for ImageNet zero-shot classification on public data while using two orders of magnitude less time and data and training 77% fewer parameters.
The Calibration Generalization Gap
Oct 06, 2022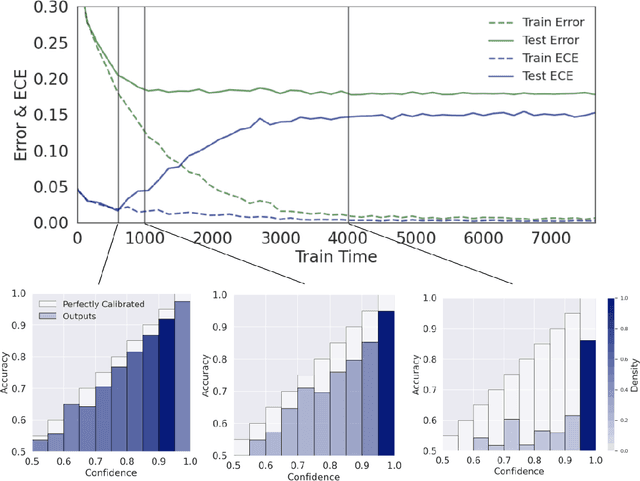
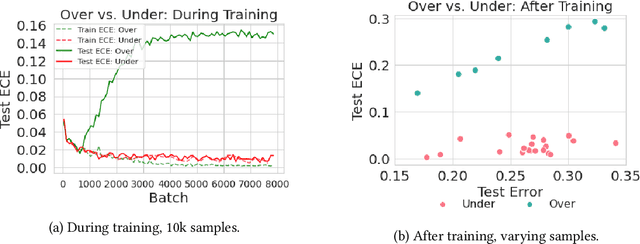
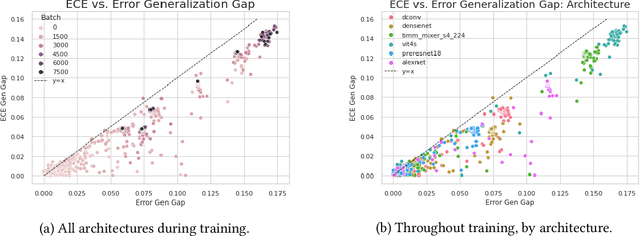
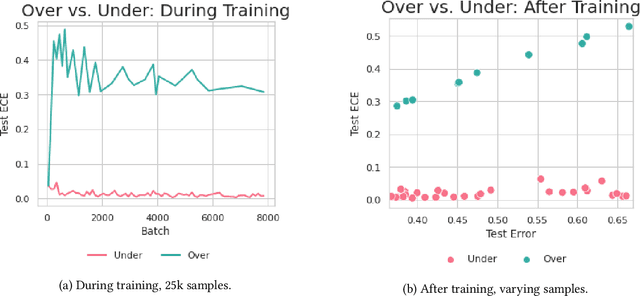
Calibration is a fundamental property of a good predictive model: it requires that the model predicts correctly in proportion to its confidence. Modern neural networks, however, provide no strong guarantees on their calibration -- and can be either poorly calibrated or well-calibrated depending on the setting. It is currently unclear which factors contribute to good calibration (architecture, data augmentation, overparameterization, etc), though various claims exist in the literature. We propose a systematic way to study the calibration error: by decomposing it into (1) calibration error on the train set, and (2) the calibration generalization gap. This mirrors the fundamental decomposition of generalization. We then investigate each of these terms, and give empirical evidence that (1) DNNs are typically always calibrated on their train set, and (2) the calibration generalization gap is upper-bounded by the standard generalization gap. Taken together, this implies that models with small generalization gap (|Test Error - Train Error|) are well-calibrated. This perspective unifies many results in the literature, and suggests that interventions which reduce the generalization gap (such as adding data, using heavy augmentation, or smaller model size) also improve calibration. We thus hope our initial study lays the groundwork for a more systematic and comprehensive understanding of the relation between calibration, generalization, and optimization.
Benign, Tempered, or Catastrophic: A Taxonomy of Overfitting
Jul 14, 2022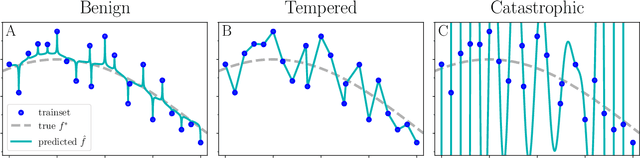

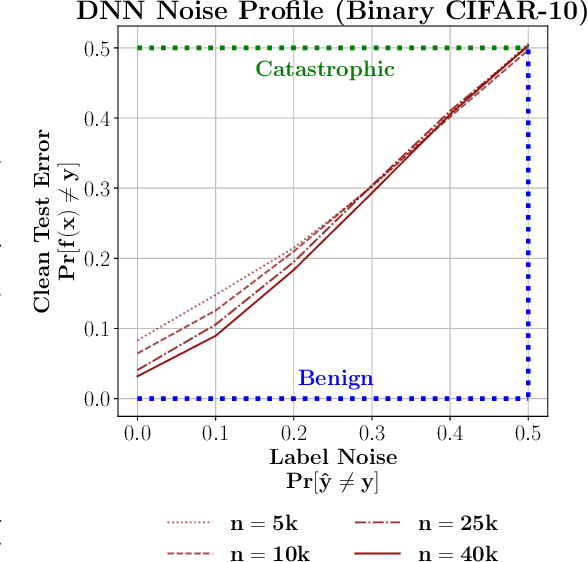

The practical success of overparameterized neural networks has motivated the recent scientific study of interpolating methods, which perfectly fit their training data. Certain interpolating methods, including neural networks, can fit noisy training data without catastrophically bad test performance, in defiance of standard intuitions from statistical learning theory. Aiming to explain this, a body of recent work has studied $\textit{benign overfitting}$, a phenomenon where some interpolating methods approach Bayes optimality, even in the presence of noise. In this work we argue that while benign overfitting has been instructive and fruitful to study, many real interpolating methods like neural networks $\textit{do not fit benignly}$: modest noise in the training set causes nonzero (but non-infinite) excess risk at test time, implying these models are neither benign nor catastrophic but rather fall in an intermediate regime. We call this intermediate regime $\textit{tempered overfitting}$, and we initiate its systematic study. We first explore this phenomenon in the context of kernel (ridge) regression (KR) by obtaining conditions on the ridge parameter and kernel eigenspectrum under which KR exhibits each of the three behaviors. We find that kernels with powerlaw spectra, including Laplace kernels and ReLU neural tangent kernels, exhibit tempered overfitting. We then empirically study deep neural networks through the lens of our taxonomy, and find that those trained to interpolation are tempered, while those stopped early are benign. We hope our work leads to a more refined understanding of overfitting in modern learning.