 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransmission Map and Atmospheric Light Guided Iterative Updater Network for Single Image Dehazing
Aug 04, 2020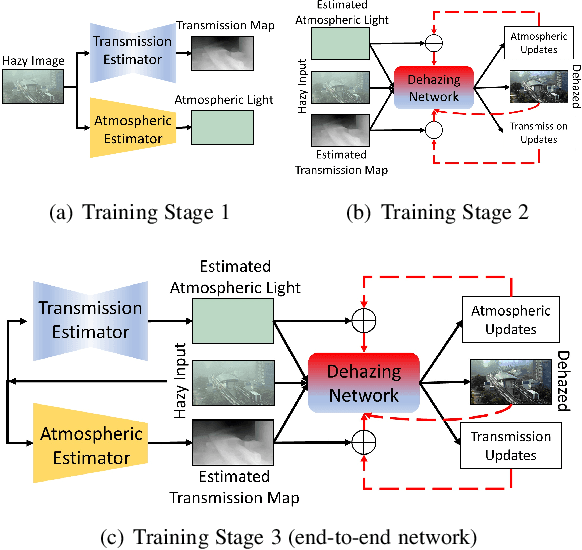
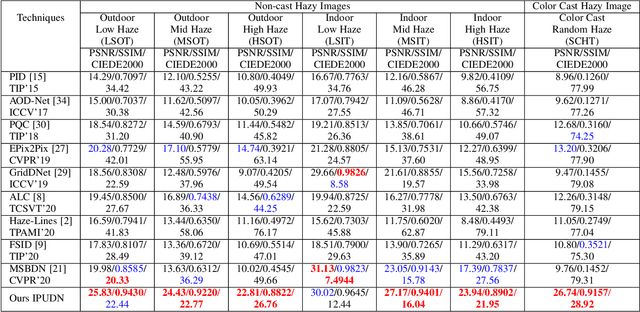


Hazy images obscure content visibility and hinder several subsequent computer vision tasks. For dehazing in a wide variety of hazy conditions, an end-to-end deep network jointly estimating the dehazed image along with suitable transmission map and atmospheric light for guidance could prove effective. To this end, we propose an Iterative Prior Updated Dehazing Network (IPUDN) based on a novel iterative update framework. We present a novel convolutional architecture to estimate channel-wise atmospheric light, which along with an estimated transmission map are used as priors for the dehazing network. Use of channel-wise atmospheric light allows our network to handle color casts in hazy images. In our IPUDN, the transmission map and atmospheric light estimates are updated iteratively using corresponding novel updater networks. The iterative mechanism is leveraged to gradually modify the estimates toward those appropriately representing the hazy condition. These updates occur jointly with the iterative estimation of the dehazed image using a convolutional neural network with LSTM driven recurrence, which introduces inter-iteration dependencies. Our approach is qualitatively and quantitatively found effective for synthetic and real-world hazy images depicting varied hazy conditions, and it outperforms the state-of-the-art. Thorough analyses of IPUDN through additional experiments and detailed ablation studies are also presented.
Lightweight Modules for Efficient Deep Learning based Image Restoration
Jul 11, 2020
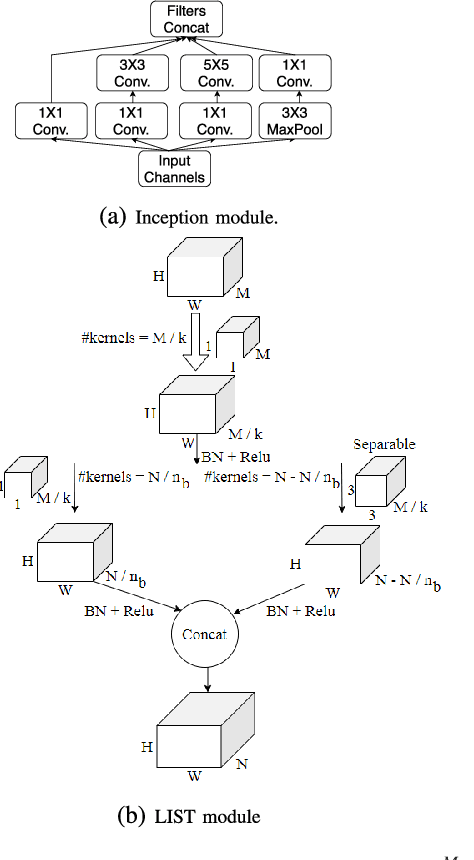
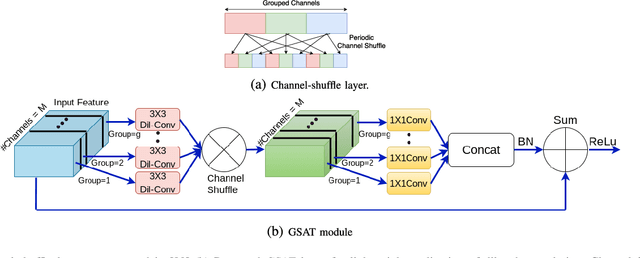
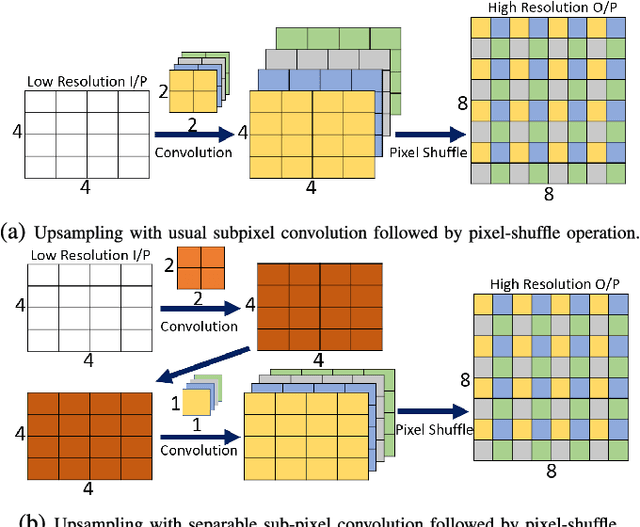
Low level image restoration is an integral component of modern artificial intelligence (AI) driven camera pipelines. Most of these frameworks are based on deep neural networks which present a massive computational overhead on resource constrained platform like a mobile phone. In this paper, we propose several lightweight low-level modules which can be used to create a computationally low cost variant of a given baseline model. Recent works for efficient neural networks design have mainly focused on classification. However, low-level image processing falls under the image-to-image' translation genre which requires some additional computational modules not present in classification. This paper seeks to bridge this gap by designing generic efficient modules which can replace essential components used in contemporary deep learning based image restoration networks. We also present and analyse our results highlighting the drawbacks of applying depthwise separable convolutional kernel (a popular method for efficient classification network) for sub-pixel convolution based upsampling (a popular upsampling strategy for low-level vision applications). This shows that concepts from domain of classification cannot always be seamlessly integrated into image-to-image translation tasks. We extensively validate our findings on three popular tasks of image inpainting, denoising and super-resolution. Our results show that proposed networks consistently output visually similar reconstructions compared to full capacity baselines with significant reduction of parameters, memory footprint and execution speeds on contemporary mobile devices.
Unsupervised Pre-trained, Texture Aware And Lightweight Model for Deep Learning-Based Iris Recognition Under Limited Annotated Data
Feb 20, 2020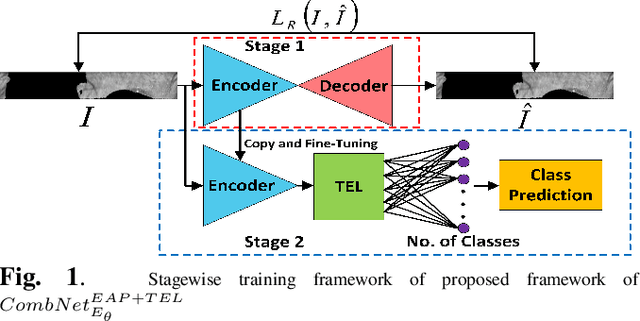
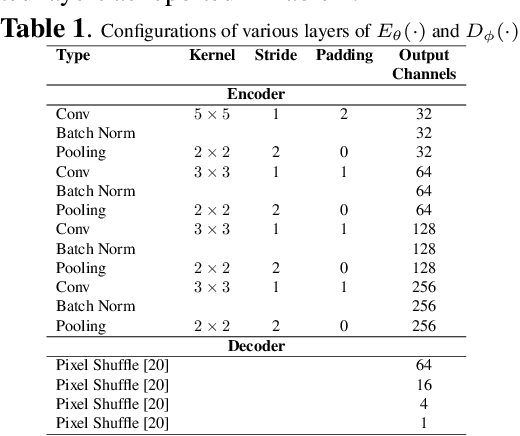

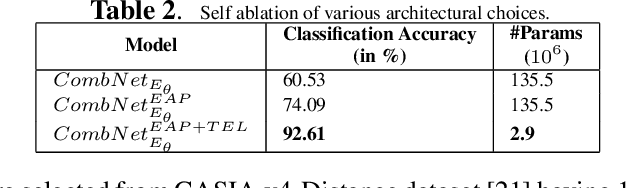
In this paper, we present a texture aware lightweight deep learning framework for iris recognition. Our contributions are primarily three fold. Firstly, to address the dearth of labelled iris data, we propose a reconstruction loss guided unsupervised pre-training stage followed by supervised refinement. This drives the network weights to focus on discriminative iris texture patterns. Next, we propose several texture aware improvisations inside a Convolution Neural Net to better leverage iris textures. Finally, we show that our systematic training and architectural choices enable us to design an efficient framework with upto 100X fewer parameters than contemporary deep learning baselines yet achieve better recognition performance for within and cross dataset evaluations.
The Angel is in the Priors: Improving GAN based Image and Sequence Inpainting with Better Noise and Structural Priors
Aug 16, 2019
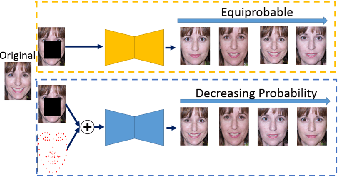
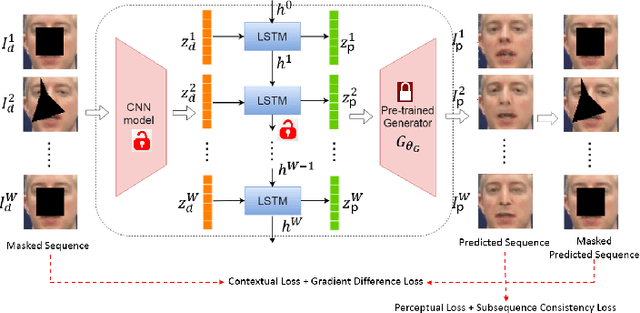

Contemporary deep learning based inpainting algorithms are mainly based on a hybrid dual stage training policy of supervised reconstruction loss followed by an unsupervised adversarial critic loss. However, there is a dearth of literature for a fully unsupervised GAN based inpainting framework. The primary aversion towards the latter genre is due to its prohibitively slow iterative optimization requirement during inference to find a matching noise prior for a masked image. In this paper, we show that priors matter in GAN: we learn a data driven parametric network to predict a matching prior for a given image. This converts an iterative paradigm to a single feed forward inference pipeline with a massive 1500X speedup and simultaneous improvement in reconstruction quality. We show that an additional structural prior imposed on GAN model results in higher fidelity outputs. To extend our model for sequence inpainting, we propose a recurrent net based grouped noise prior learning. To our knowledge, this is the first demonstration of an unsupervised GAN based sequence inpainting. A further improvement in sequence inpainting is achieved with an additional subsequence consistency loss. These contributions improve the spatio-temporal characteristics of reconstructed sequences. Extensive experiments conducted on SVHN, Standford Cars, CelebA and CelebA-HQ image datasets, synthetic sequences and ViDTIMIT video datasets reveal that we consistently improve upon previous unsupervised baseline and also achieve comparable performances(sometimes also better) to hybrid benchmarks.
Faster Unsupervised Semantic Inpainting: A GAN Based Approach
Aug 14, 2019
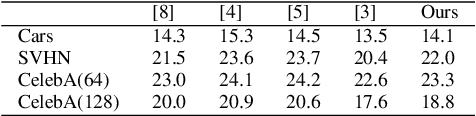


In this paper, we propose to improve the inference speed and visual quality of contemporary baseline of Generative Adversarial Networks (GAN) based unsupervised semantic inpainting. This is made possible with better initialization of the core iterative optimization involved in the framework. To our best knowledge, this is also the first attempt of GAN based video inpainting with consideration to temporal cues. On single image inpainting, we achieve about 4.5-5$\times$ speedup and 80$\times$ on videos compared to baseline. Simultaneously, our method has better spatial and temporal reconstruction qualities as found on three image and one video dataset.
Fast Bayesian Uncertainty Estimation of Batch Normalized Single Image Super-Resolution Network
Mar 22, 2019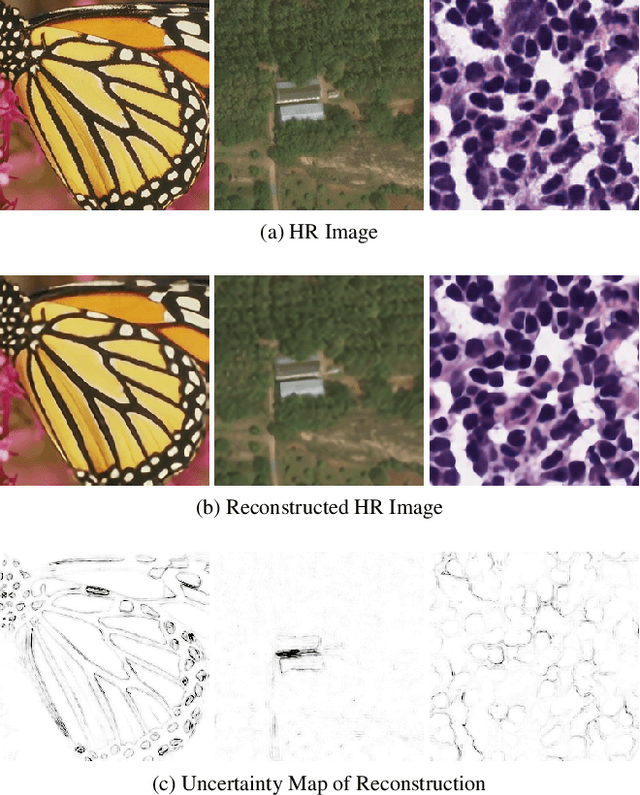

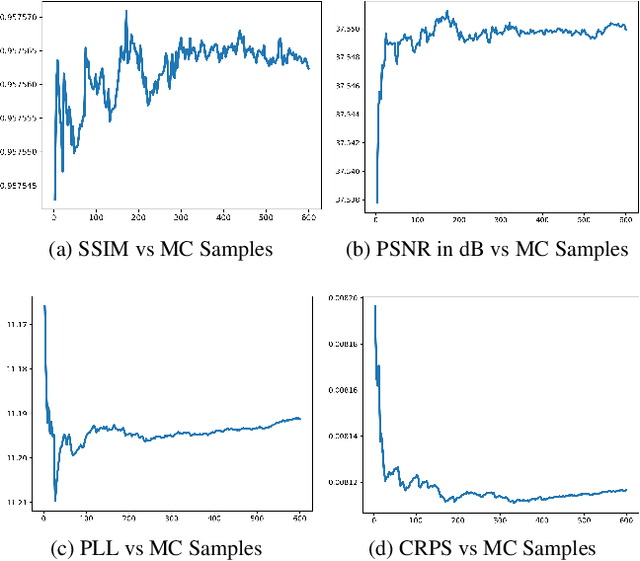
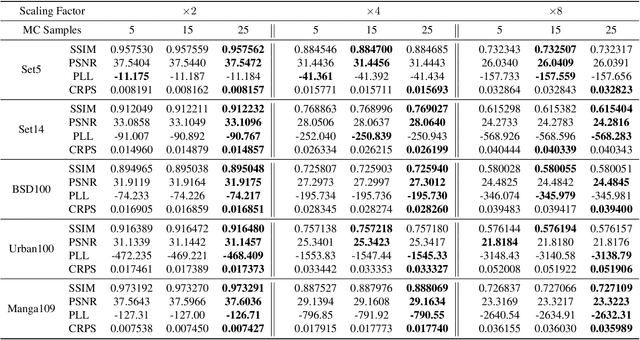
In recent years, deep convolutional neural network (CNN) has achieved unprecedented success in image super-resolution (SR) task. But the black-box nature of the neural network and due to its lack of transparency, it is hard to trust the outcome. In this regards, we introduce a Bayesian approach for uncertainty estimation in super-resolution network. We generate Monte Carlo (MC) samples from a posterior distribution by using batch mean and variance as a stochastic parameter in the batch-normalization layer during test time. Those MC samples not only reconstruct the image from its low-resolution counterpart but also provides a confidence map of reconstruction which will be very impactful for practical use. We also introduce a faster approach for estimating the uncertainty, and it can be useful for real-time applications. We validate our results using standard datasets for performance analysis and also for different domain-specific super-resolution task. We also estimate uncertainty quality using standard statistical metrics and also provides a qualitative evaluation of uncertainty for SR applications.
Improved Techniques for GAN based Facial Inpainting
Oct 20, 2018
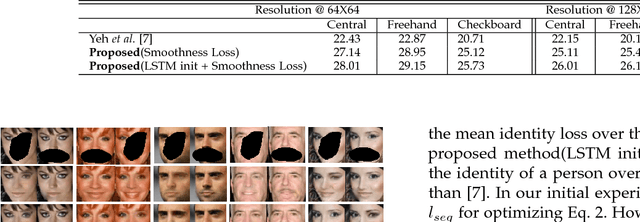

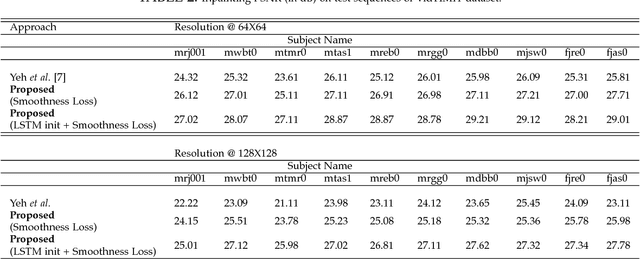
In this paper we present several architectural and optimization recipes for generative adversarial network(GAN) based facial semantic inpainting. Current benchmark models are susceptible to initial solutions of non-convex optimization criterion of GAN based inpainting. We present an end-to-end trainable parametric network to deterministically start from good initial solutions leading to more photo realistic reconstructions with significant optimization speed up. For the first time, we show how to efficiently extend GAN based single image inpainter models to sequences by a)learning to initialize a temporal window of solutions with a recurrent neural network and b)imposing a temporal smoothness loss(during iterative optimization) to respect the redundancy in temporal dimension of a sequence. We conduct comprehensive empirical evaluations on CelebA images and pseudo sequences followed by real life videos of VidTIMIT dataset. The proposed method significantly outperforms current GAN based state-of-the-art in terms of reconstruction quality with a simultaneous speedup of over 15$\times$. We also show that our proposed model is better in preserving facial identity in a sequence even without explicitly using any face recognition module during training.
Unsupervised Domain Adaptation for Learning Eye Gaze from a Million Synthetic Images: An Adversarial Approach
Oct 18, 2018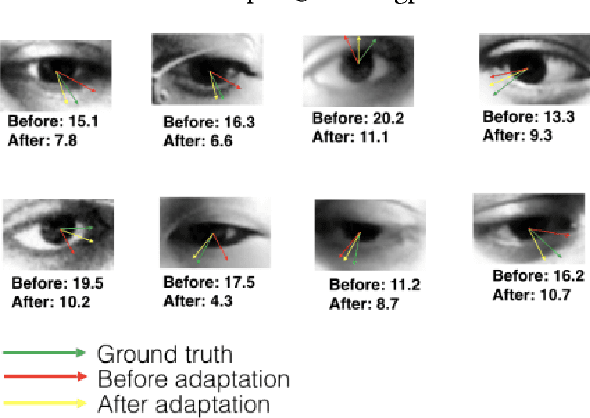
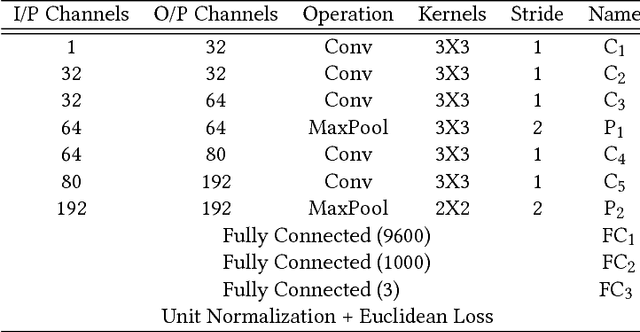


With contemporary advancements of graphics engines, recent trend in deep learning community is to train models on automatically annotated simulated examples and apply on real data during test time. This alleviates the burden of manual annotation. However, there is an inherent difference of distributions between images coming from graphics engine and real world. Such domain difference deteriorates test time performances of models trained on synthetic examples. In this paper we address this issue with unsupervised adversarial feature adaptation across synthetic and real domain for the special use case of eye gaze estimation which is an essential component for various downstream HCI tasks. We initially learn a gaze estimator on annotated synthetic samples rendered from a 3D game engine and then adapt the features of unannotated real samples via a zero-sum minmax adversarial game against a domain discriminator following the recent paradigm of generative adversarial networks. Such adversarial adaptation forces features of both domains to be indistinguishable which enables us to use regression models trained on synthetic domain to be used on real samples. On the challenging MPIIGaze real life dataset, we outperform recent fully supervised methods trained on manually annotated real samples by appreciable margins and also achieve 13\% more relative gain after adaptation compared to the current benchmark method of SimGAN
Retinal Vessel Segmentation under Extreme Low Annotation: A Generative Adversarial Network Approach
Sep 05, 2018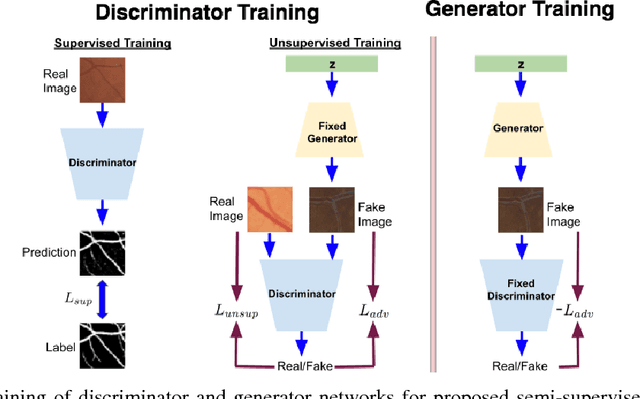
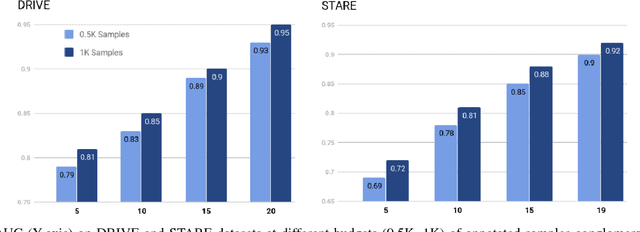
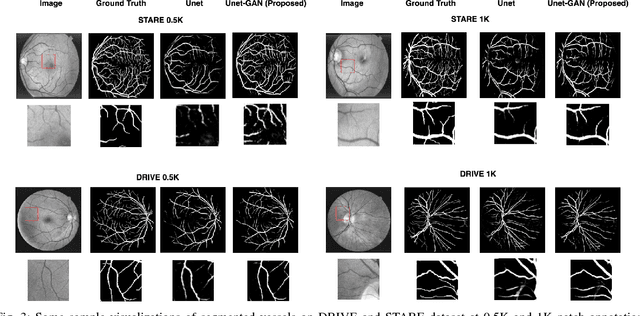

Contemporary deep learning based medical image segmentation algorithms require hours of annotation labor by domain experts. These data hungry deep models perform sub-optimally in the presence of limited amount of labeled data. In this paper, we present a data efficient learning framework using the recent concept of Generative Adversarial Networks; this allows a deep neural network to perform significantly better than its fully supervised counterpart in low annotation regime. The proposed method is an extension of our previous work with the addition of a new unsupervised adversarial loss and a structured prediction based architecture. To the best of our knowledge, this work is the first demonstration of an adversarial framework based structured prediction model for medical image segmentation. Though generic, we apply our method for segmentation of blood vessels in retinal fundus images. We experiment with extreme low annotation budget (0.8 - 1.6% of contemporary annotation size). On DRIVE and STARE datasets, the proposed method outperforms our previous method and other fully supervised benchmark models by significant margins especially with very low number of annotated examples. In addition, our systematic ablation studies suggest some key recipes for successfully training GAN based semi-supervised algorithms with an encoder-decoder style network architecture.
Improving Consistency and Correctness of Sequence Inpainting using Semantically Guided Generative Adversarial Network
Nov 17, 2017
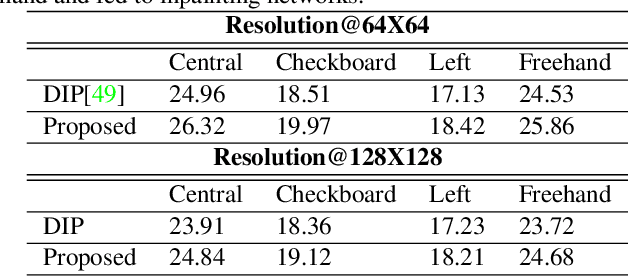
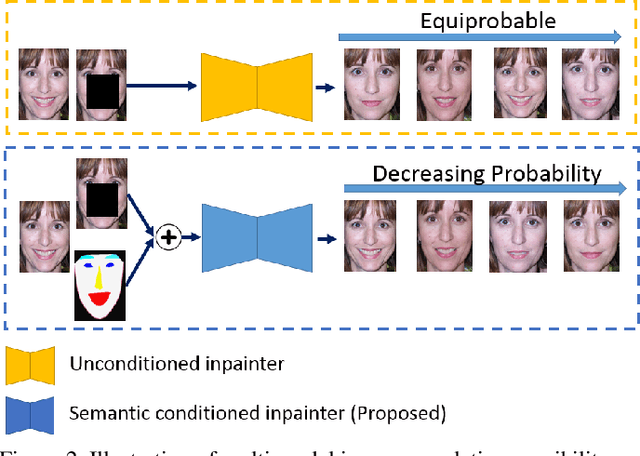

Contemporary benchmark methods for image inpainting are based on deep generative models and specifically leverage adversarial loss for yielding realistic reconstructions. However, these models cannot be directly applied on image/video sequences because of an intrinsic drawback- the reconstructions might be independently realistic, but, when visualized as a sequence, often lacks fidelity to the original uncorrupted sequence. The fundamental reason is that these methods try to find the best matching latent space representation near to natural image manifold without any explicit distance based loss. In this paper, we present a semantically conditioned Generative Adversarial Network (GAN) for sequence inpainting. The conditional information constrains the GAN to map a latent representation to a point in image manifold respecting the underlying pose and semantics of the scene. To the best of our knowledge, this is the first work which simultaneously addresses consistency and correctness of generative model based inpainting. We show that our generative model learns to disentangle pose and appearance information; this independence is exploited by our model to generate highly consistent reconstructions. The conditional information also aids the generator network in GAN to produce sharper images compared to the original GAN formulation. This helps in achieving more appealing inpainting performance. Though generic, our algorithm was targeted for inpainting on faces. When applied on CelebA and Youtube Faces datasets, the proposed method results in a significant improvement over the current benchmark, both in terms of quantitative evaluation (Peak Signal to Noise Ratio) and human visual scoring over diversified combinations of resolutions and deformations.