 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Abstractive Dialogue Summarization with Sketch Supervision
Jun 03, 2021
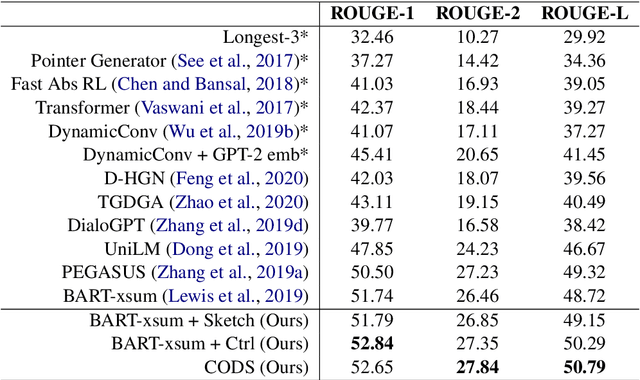
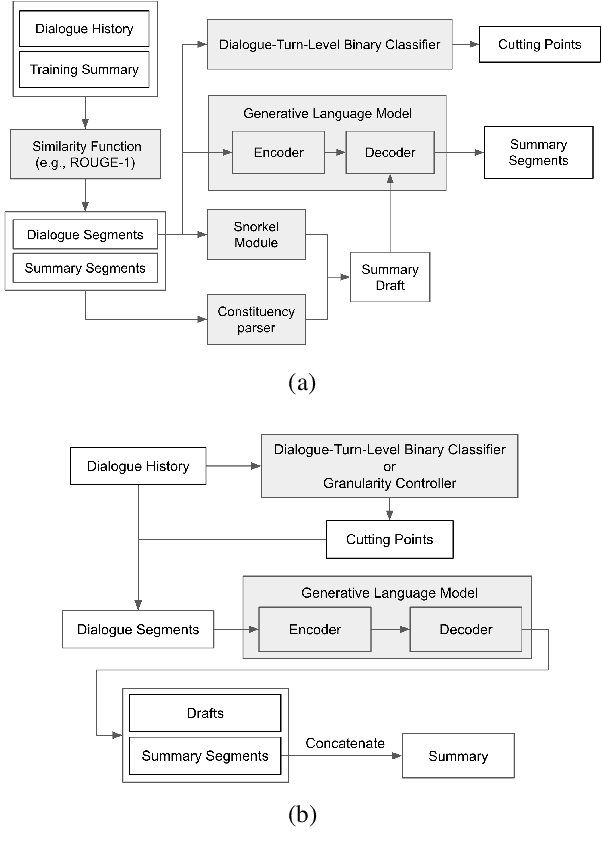

In this paper, we aim to improve abstractive dialogue summarization quality and, at the same time, enable granularity control. Our model has two primary components and stages: 1) a two-stage generation strategy that generates a preliminary summary sketch serving as the basis for the final summary. This summary sketch provides a weakly supervised signal in the form of pseudo-labeled interrogative pronoun categories and key phrases extracted using a constituency parser. 2) A simple strategy to control the granularity of the final summary, in that our model can automatically determine or control the number of generated summary sentences for a given dialogue by predicting and highlighting different text spans from the source text. Our model achieves state-of-the-art performance on the largest dialogue summarization corpus SAMSum, with as high as 50.79 in ROUGE-L score. In addition, we conduct a case study and show competitive human evaluation results and controllability to human-annotated summaries.
Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
Apr 18, 2021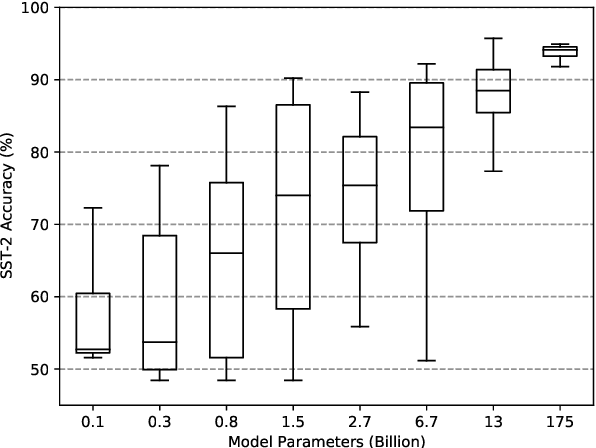
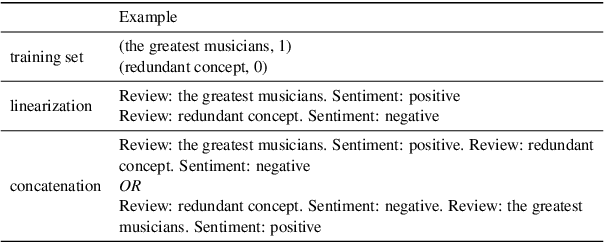
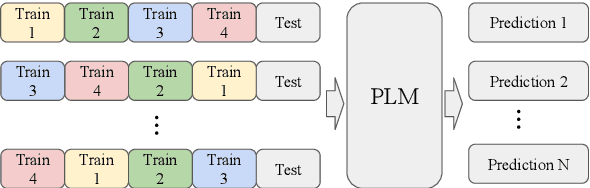
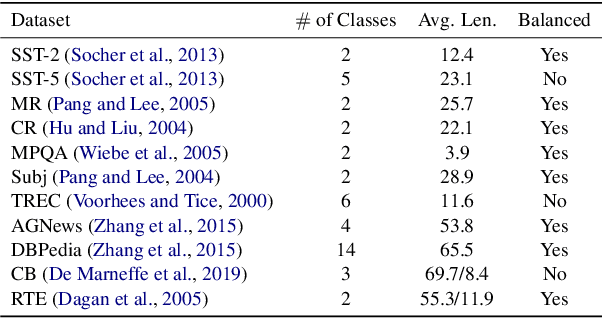
When primed with only a handful of training samples, very large pretrained language models such as GPT-3, have shown competitive results when compared to fully-supervised fine-tuned large pretrained language models. We demonstrate that the order in which the samples are provided can be the difference between near state-of-the-art and random guess performance: Essentially some permutations are "fantastic" and some not. We analyse this phenomenon in detail, establishing that: it is present across model sizes (even for the largest current models), it is not related to a specific subset of samples, and that a given good permutation for one model is not transferable to another. While one could use a development set to determine which permutations are performant, this would deviate from the few-shot setting as it requires additional annotated data. Instead, we use the generative nature of the language models to construct an artificial development set and based on entropy statistics of the candidate permutations from this set we identify performant prompts. Our method improves upon GPT-family models by on average 13% relative across eleven different established text classification tasks.
Improving Question Answering Model Robustness with Synthetic Adversarial Data Generation
Apr 18, 2021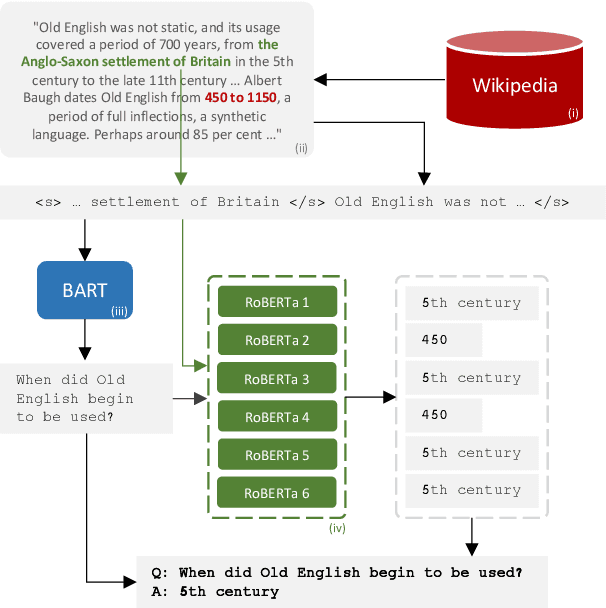
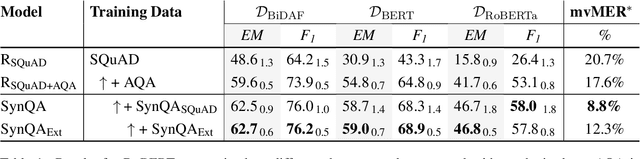
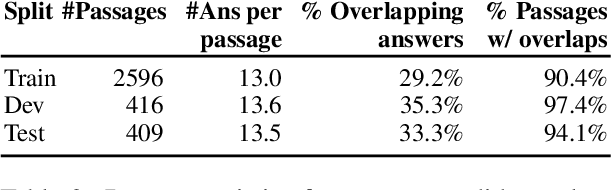
Despite the availability of very large datasets and pretrained models, state-of-the-art question answering models remain susceptible to a variety of adversarial attacks and are still far from obtaining human-level language understanding. One proposed way forward is dynamic adversarial data collection, in which a human annotator attempts to create examples for which a model-in-the-loop fails. However, this approach comes at a higher cost per sample and slower pace of annotation, as model-adversarial data requires more annotator effort to generate. In this work, we investigate several answer selection, question generation, and filtering methods that form a synthetic adversarial data generation pipeline that takes human-generated adversarial samples and unannotated text to create synthetic question-answer pairs. Models trained on both synthetic and human-generated data outperform models not trained on synthetic adversarial data, and obtain state-of-the-art results on the AdversarialQA dataset with overall performance gains of 3.7F1. Furthermore, we find that training on the synthetic adversarial data improves model generalisation across domains for non-adversarial data, demonstrating gains on 9 of the 12 datasets for MRQA. Lastly, we find that our models become considerably more difficult to beat by human adversaries, with a drop in macro-averaged validated model error rate from 17.6% to 8.8% when compared to non-augmented models.
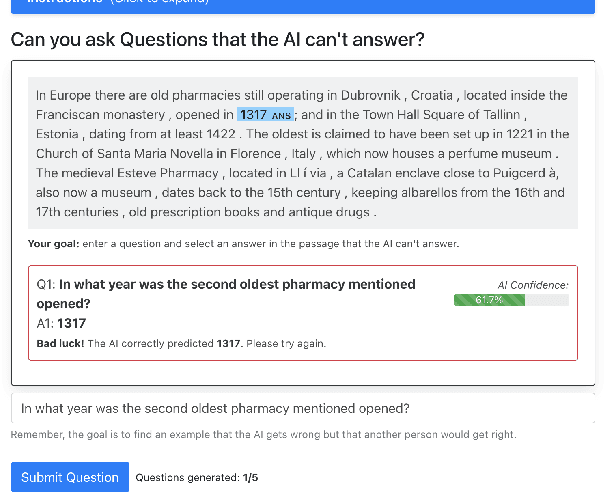
Dynabench: Rethinking Benchmarking in NLP
Apr 07, 2021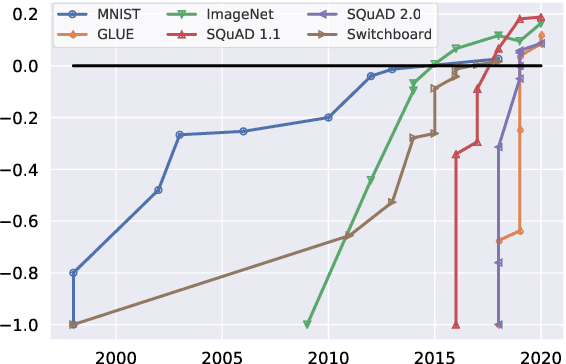
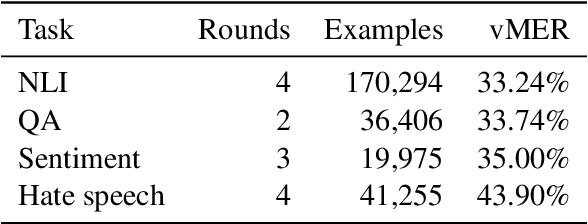
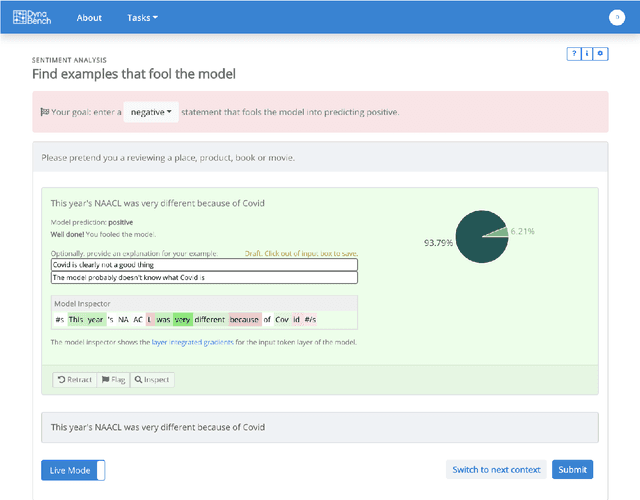
We introduce Dynabench, an open-source platform for dynamic dataset creation and model benchmarking. Dynabench runs in a web browser and supports human-and-model-in-the-loop dataset creation: annotators seek to create examples that a target model will misclassify, but that another person will not. In this paper, we argue that Dynabench addresses a critical need in our community: contemporary models quickly achieve outstanding performance on benchmark tasks but nonetheless fail on simple challenge examples and falter in real-world scenarios. With Dynabench, dataset creation, model development, and model assessment can directly inform each other, leading to more robust and informative benchmarks. We report on four initial NLP tasks, illustrating these concepts and highlighting the promise of the platform, and address potential objections to dynamic benchmarking as a new standard for the field.
PAQ: 65 Million Probably-Asked Questions and What You Can Do With Them
Feb 13, 2021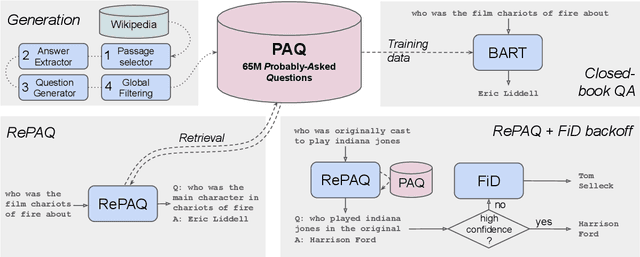
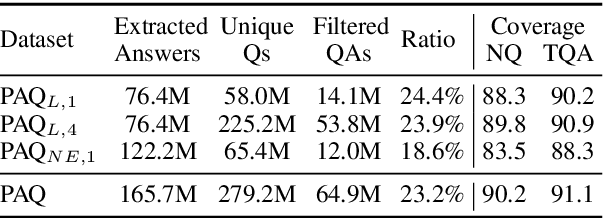

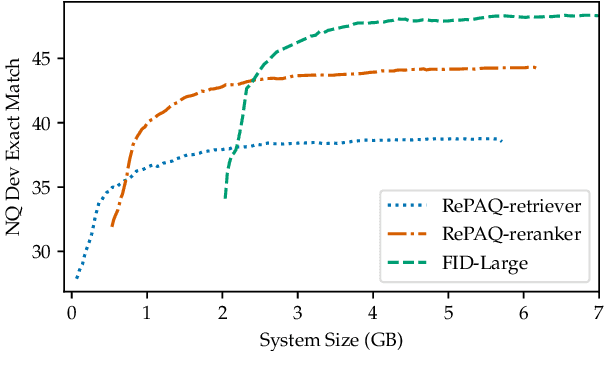
Open-domain Question Answering models which directly leverage question-answer (QA) pairs, such as closed-book QA (CBQA) models and QA-pair retrievers, show promise in terms of speed and memory compared to conventional models which retrieve and read from text corpora. QA-pair retrievers also offer interpretable answers, a high degree of control, and are trivial to update at test time with new knowledge. However, these models lack the accuracy of retrieve-and-read systems, as substantially less knowledge is covered by the available QA-pairs relative to text corpora like Wikipedia. To facilitate improved QA-pair models, we introduce Probably Asked Questions (PAQ), a very large resource of 65M automatically-generated QA-pairs. We introduce a new QA-pair retriever, RePAQ, to complement PAQ. We find that PAQ preempts and caches test questions, enabling RePAQ to match the accuracy of recent retrieve-and-read models, whilst being significantly faster. Using PAQ, we train CBQA models which outperform comparable baselines by 5%, but trail RePAQ by over 15%, indicating the effectiveness of explicit retrieval. RePAQ can be configured for size (under 500MB) or speed (over 1K questions per second) whilst retaining high accuracy. Lastly, we demonstrate RePAQ's strength at selective QA, abstaining from answering when it is likely to be incorrect. This enables RePAQ to ``back-off" to a more expensive state-of-the-art model, leading to a combined system which is both more accurate and 2x faster than the state-of-the-art model alone.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021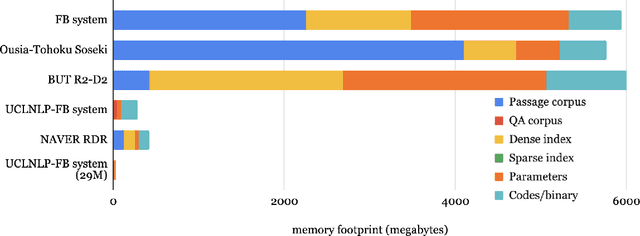
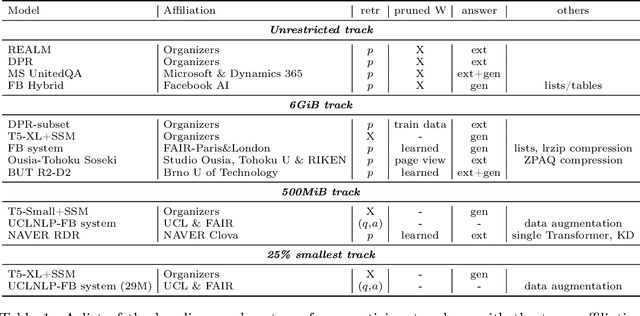
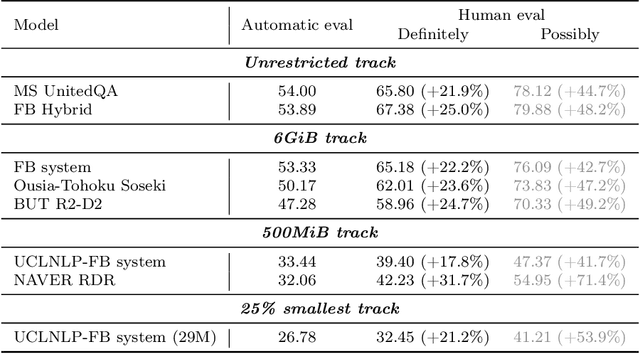
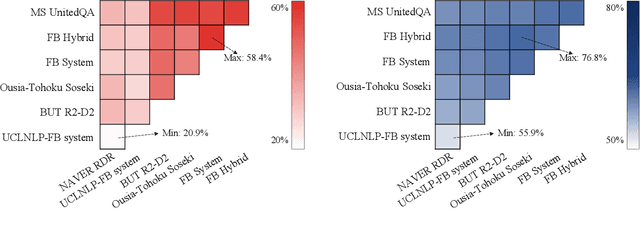
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
Don't Read Too Much into It: Adaptive Computation for Open-Domain Question Answering
Nov 10, 2020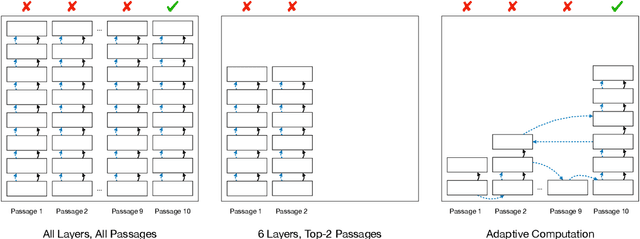
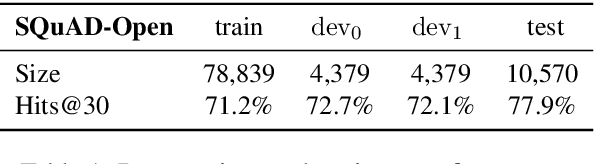
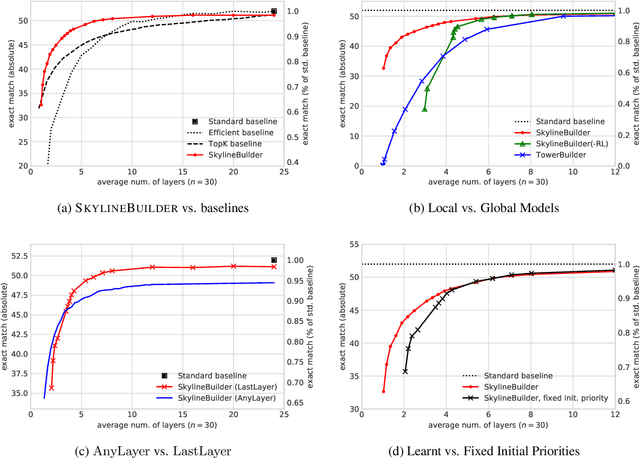
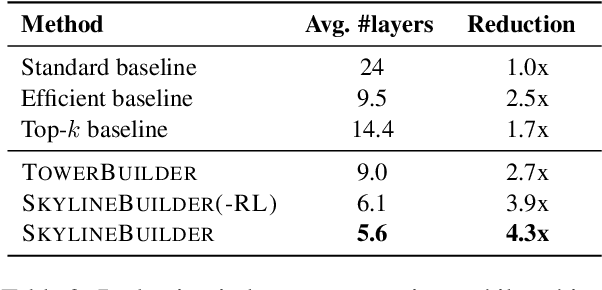
Most approaches to Open-Domain Question Answering consist of a light-weight retriever that selects a set of candidate passages, and a computationally expensive reader that examines the passages to identify the correct answer. Previous works have shown that as the number of retrieved passages increases, so does the performance of the reader. However, they assume all retrieved passages are of equal importance and allocate the same amount of computation to them, leading to a substantial increase in computational cost. To reduce this cost, we propose the use of adaptive computation to control the computational budget allocated for the passages to be read. We first introduce a technique operating on individual passages in isolation which relies on anytime prediction and a per-layer estimation of an early exit probability. We then introduce SkylineBuilder, an approach for dynamically deciding on which passage to allocate computation at each step, based on a resource allocation policy trained via reinforcement learning. Our results on SQuAD-Open show that adaptive computation with global prioritisation improves over several strong static and adaptive methods, leading to a 4.3x reduction in computation while retaining 95% performance of the full model.
Question and Answer Test-Train Overlap in Open-Domain Question Answering Datasets
Aug 06, 2020


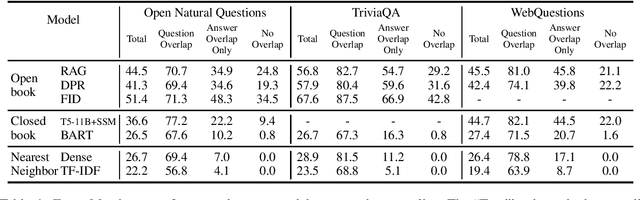
Ideally Open-Domain Question Answering models should exhibit a number of competencies, ranging from simply memorizing questions seen at training time, to answering novel question formulations with answers seen during training, to generalizing to completely novel questions with novel answers. However, single aggregated test set scores do not show the full picture of what capabilities models truly have. In this work, we perform a detailed study of the test sets of three popular open-domain benchmark datasets with respect to these competencies. We find that 60-70% of test-time answers are also present somewhere in the training sets. We also find that 30% of test-set questions have a near-duplicate paraphrase in their corresponding training sets. Using these findings, we evaluate a variety of popular open-domain models to obtain greater insight into what extent they can actually generalize, and what drives their overall performance. We find that all models perform dramatically worse on questions that cannot be memorized from training sets, with a mean absolute performance difference of 63% between repeated and non-repeated data. Finally we show that simple nearest-neighbor models out-perform a BART closed-book QA model, further highlighting the role that training set memorization plays in these benchmarks
Learning Reasoning Strategies in End-to-End Differentiable Proving
Jul 14, 2020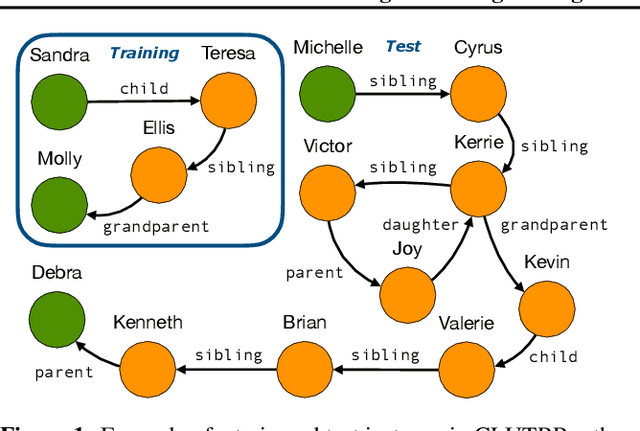
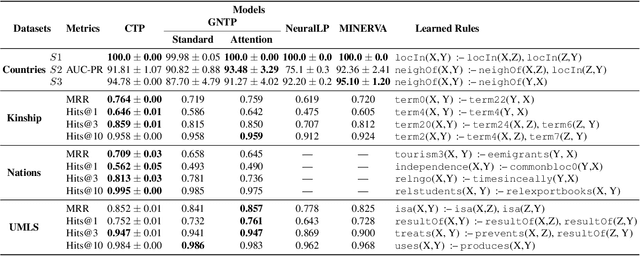

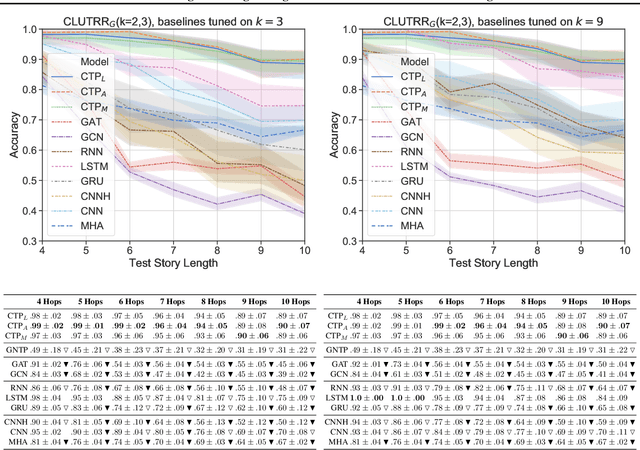
Attempts to render deep learning models interpretable, data-efficient, and robust have seen some success through hybridisation with rule-based systems, for example, in Neural Theorem Provers (NTPs). These neuro-symbolic models can induce interpretable rules and learn representations from data via back-propagation, while providing logical explanations for their predictions. However, they are restricted by their computational complexity, as they need to consider all possible proof paths for explaining a goal, thus rendering them unfit for large-scale applications. We present Conditional Theorem Provers (CTPs), an extension to NTPs that learns an optimal rule selection strategy via gradient-based optimisation. We show that CTPs are scalable and yield state-of-the-art results on the CLUTRR dataset, which tests systematic generalisation of neural models by learning to reason over smaller graphs and evaluating on larger ones. Finally, CTPs show better link prediction results on standard benchmarks in comparison with other neural-symbolic models, while being explainable. All source code and datasets are available online, at https://github.com/uclnlp/ctp.
AxCell: Automatic Extraction of Results from Machine Learning Papers
Apr 29, 2020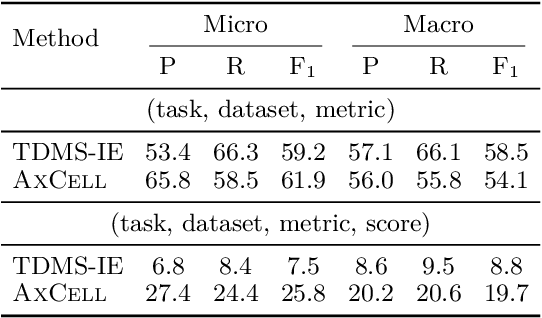
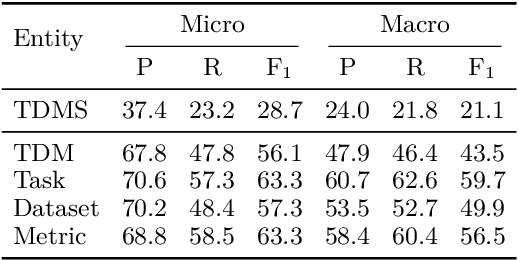
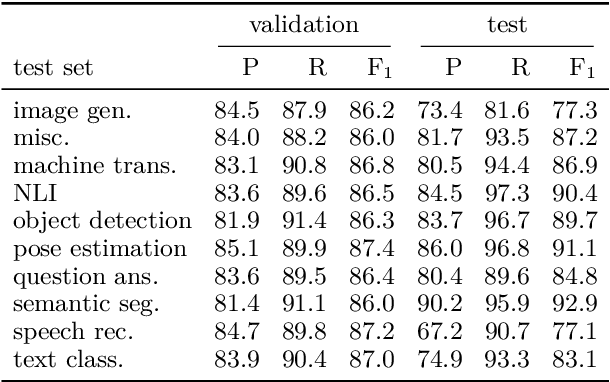
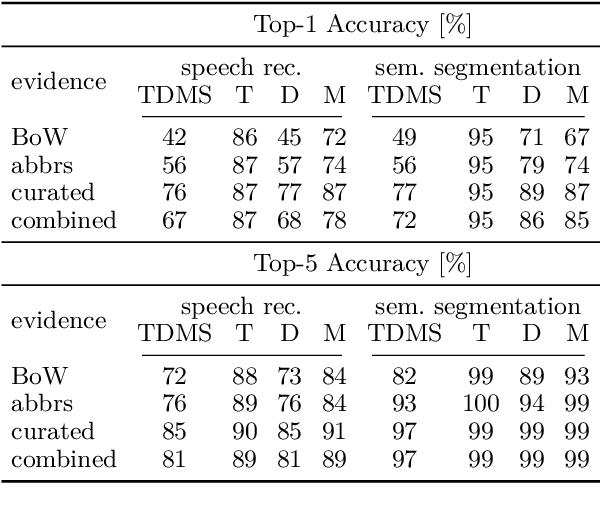
Tracking progress in machine learning has become increasingly difficult with the recent explosion in the number of papers. In this paper, we present AxCell, an automatic machine learning pipeline for extracting results from papers. AxCell uses several novel components, including a table segmentation subtask, to learn relevant structural knowledge that aids extraction. When compared with existing methods, our approach significantly improves the state of the art for results extraction. We also release a structured, annotated dataset for training models for results extraction, and a dataset for evaluating the performance of models on this task. Lastly, we show the viability of our approach enables it to be used for semi-automated results extraction in production, suggesting our improvements make this task practically viable for the first time. Code is available on GitHub.